
لایه های کانولوشن چگونه در یادگیری عمیق شبکه های عصبی کار می کنند؟
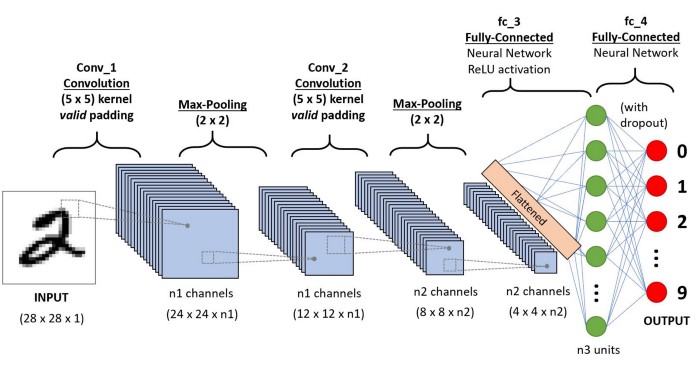
شبکه عصبی کانولوشنی
شبکه های عصبی کانولوشنی با عملکردهای برتر با ورودی های سیگنال تصویر، گفتار یا صدا از سایر شبکه های عصبی متمایز می شوند. هدف ما این این است که ماشین ها بتوانند جهان را مانند انسان ها ببینند، آن را به روشی مشابه درک کنند و حتی از از این دانش برای بسیاری از کارها مانند تشخیص تصویر و فیلم، تجزیه و تحلیل و طبقه بندی تصویر، سیستم های توصیه گر، پردازش زبان طبیعی، و غیره استفاده کنند. بینایی کامپیوتر با یادگیری عمیق در طول زمان ساخته و کامل شده است که مهمترین الگوریتم آن شبکه عصبی کانولوشن(Convolutional Neural Network) است.
انواع اصلی لایه ها عبارتند از:
- لایه کانولوشنی
- لایه pooling
- لایه کاملاً متصل Fully Vonnected (FC)
انواع لایه ها شبکه های کانولوشنی
لایه کانولوشن اولین لایه یک شبکه کانولوشن است. در حالی که لایه های کانولوشن را می توان با لایه های کانولوشن اضافی یا لایه های ترکیبی دنبال کرد ، لایه کاملاً متصل لایه نهایی است. با هر لایه ، CNN پیچیدگی خود را افزایش می دهد و قسمتهای بیشتری از تصویر را مشخص می کند. لایه های قبلی بر ویژگی های ساده مانند رنگ ها و لبه ها تمرکز می کنند. همانطور که داده های تصویر در لایه های CNN پیش می روند ، عناصر یا اشکال بزرگتر شیء را تشخیص می دهند تا در نهایت شی مورد نظر را شناسایی کنند.
شبکه عصبی کانولوشن (ConvNet/CNN) یک الگوریتم یادگیری عمیق است که می تواند یک تصویر را به عنوان ورودی گرفته، به اجزا مختلف در تصویر اهمیت (وزن و بایاس قابل یادگیری) اختصاص دهد و بتواند یکی را از دیگری متمایز کند. پیش پردازش مورد نیاز در شبکه عصبی کانولوشن در مقایسه با الگوریتم های طبقه بندی دیگر بسیار کمتر است.
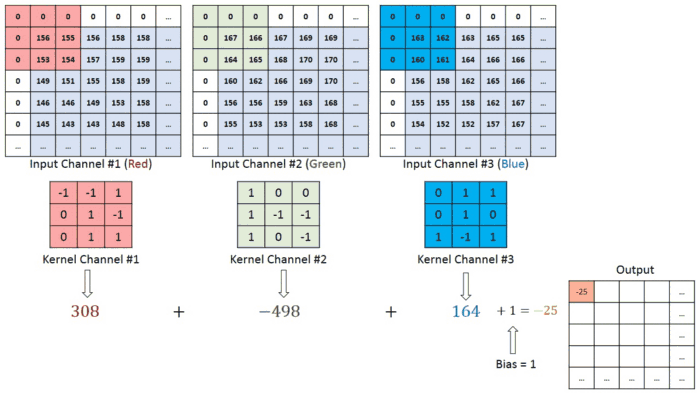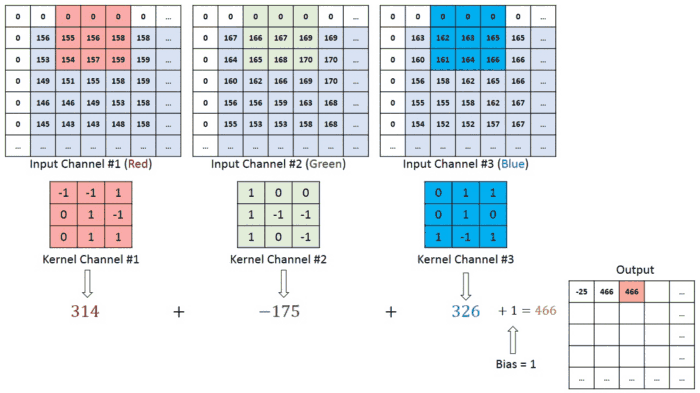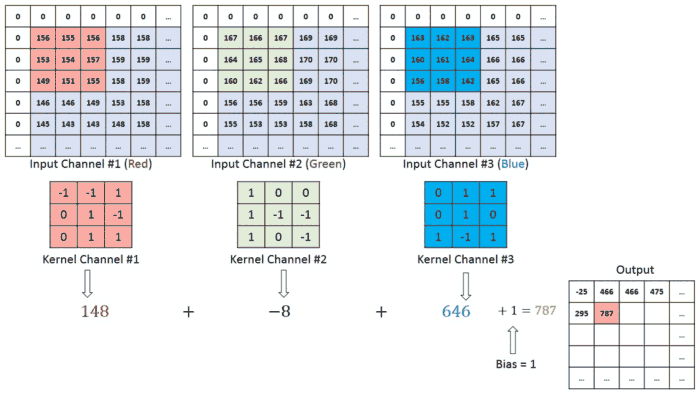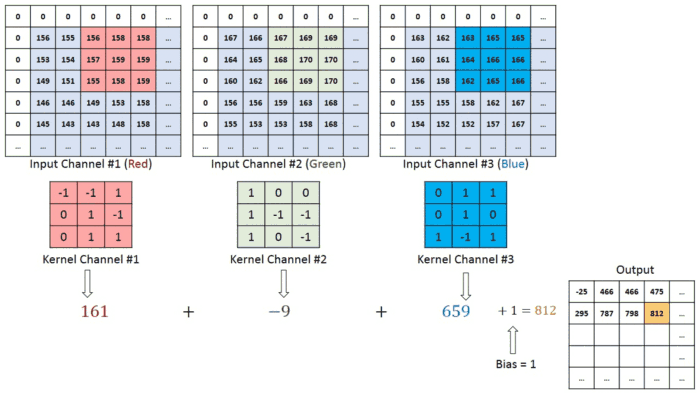
معماری CNN مشابه الگوی اتصال نورون ها در مغز انسان است و از قشر دیداری ( Visual Cortex )الهام گرفته است. هر نورون فقط در یک منطقه محدود از میدان دید که به عنوان میدان تاثیر (Receptive Field) شناخته می شود، به محرک ها پاسخ می دهند. با روی هم قرار گرفتن این منطقه ها کل تصویر پوشش داده می شود. لایه کانولوشن اصلی ساختمان اصلی CNN است و جایی است که اکثر محاسبات در آن اتفاق می افتد. به چند جزء که شامل داده های ورودی ، فیلتر و نقشه ویژگی است نیاز دارد. فرض کنیم ورودی یک تصویر رنگی باشد که از ماتریسی از پیکسل ها به صورت سه بعدی تشکیل شده است. این بدان معناست که ورودی دارای سه بعد – ارتفاع ، عرض و عمق – است که با RGB در تصویر مطابقت دارد.
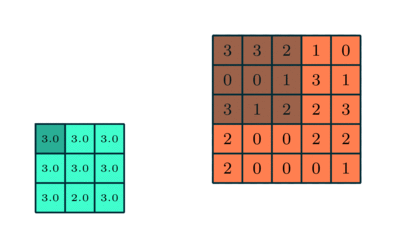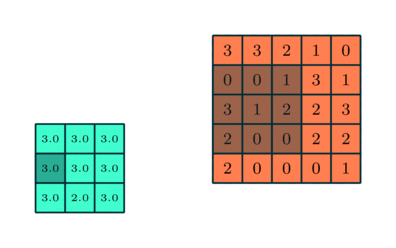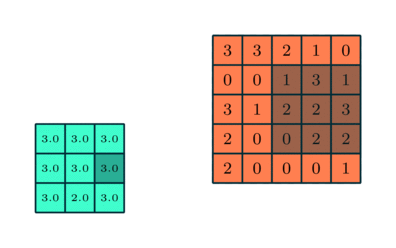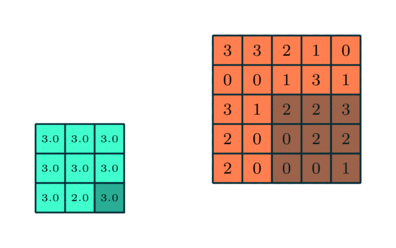
ما همچنین یک آشکارساز ویژگی داریم، که به عنوان هسته یا فیلتر نیز شناخته می شود که در سراسر زمینه های پذیرای تصویر حرکت می کند و بررسی می کند که آیا ویژگی موجود است یا خیر. این فرایند به عنوان کانولوشن شناخته می شود.آشکارساز ویژگی یک آرایه وزن دو بعدی (2 بعدی) است که بخشی از تصویر را نشان می دهد. در حالی که اندازه آنها می تواند متفاوت باشد ، اندازه فیلتر معمولاً یک ماتریس 3×3 است. این نیز اندازه میدان پذیرش را تعیین می کند. سپس فیلتر بر روی ناحیه ای از تصویر اعمال می شود و یک محصول نقطه بین پیکسل های ورودی و فیلتر محاسبه می شود. این محصول نقطه ای سپس در یک آرایه خروجی تغذیه می شود. پس از آن ، فیلتر به تدریج تغییر می کند و این روند را تکرار می کند تا زمانی که هسته روی کل تصویر جارو شود. خروجی نهایی از سری محصولات نقطه ای از ورودی و فیلتر به عنوان نقشه ویژگی ، نقشه فعال سازی یا ویژگی پیچیده شناخته می شود.
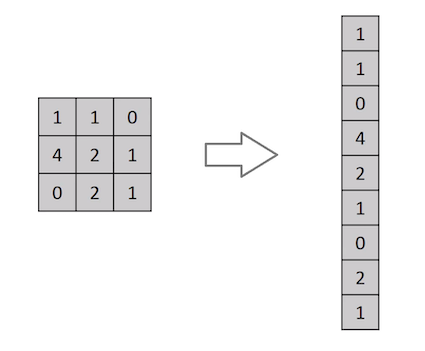
یک تصویر چیزی نیست جز ماتریسی از مقادیر پیکسل ، پس چرا فقط تصویر را مسطح نمی کنیم (به عنوان مثال ماتریس تصویر 3×3 در یک بردار 9×1) و آن را برای اهداف طبقه بندی به یک پرسپترون چند لایه ارائه نمی دهیم؟در موارد تصاویر باینری بسیارساده (مانند تصویر سیاه و سفید) ، این روش ممکن است هنگام انجام پیش بینی کلاس ها ، به یک نمره متوسط دست یابد ، اما در مورد تصاویر پیچیده ای که در کل وابستگی به پیکسل دارند ، دقت چندانی ندارد.CNN قادر است با استفاده از فیلترهای مربوطه وابستگی های مکانی و زمانی را در یک تصویر ثبت کند. این معماری به دلیل کاهش تعداد پارامترهای درگیر و قابلیت استفاده مجدد از وزن ها ، سازگاری بهتری با مجموعه داده های تصویر دارد. به عبارت دیگر ، می توان شبکه را آموزش داد تا پیچیدگی تصویر را بهتر درک کند.
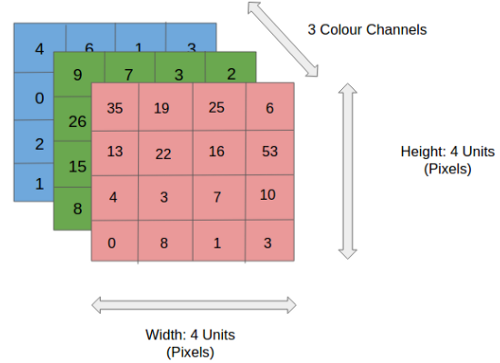
در شکل، ما یک تصویر RGB داریم که توسط سه صفحه قرمز – سبز و آبی جدا شده است. تعدادی از این فضاهای رنگی وجود دار – Grayscale, RGB, HSV, CMYK و غیره.نقش CNN کاهش تصاویر به شکلی است که پردازش آن آسان تر باشد ، بدون از دست دادن ویژگی هایی که برای بدست آوردن پیش بینی ضروری است. و همچنین هنگامی که می خواهیم معماری را طراحی کنیم که نه تنها در یادگیری ویژگی ها خوب باشد بلکه در مجموعه داده های عظیم نیز مقیاس پذیر باشد .
همانطور که در تصویر بالا مشاهده می کنید ، هر مقدار خروجی در نقشه ویژگی نیازی به اتصال به هر مقدار پیکسل در تصویر ورودی ندارد. فقط باید به میدان پذیرش ، جایی که فیلتر در حال اعمال است ، متصل شود. از آنجا که آرایه خروجی نیازی به نقشه مستقیم به هر مقدار ورودی ندارد ، لایه های کانولوشن (و تجمیع) معمولاً به عنوان لایه های “تا حدی متصل” نامیده می شوند. با این حال ، این ویژگی را می توان به عنوان اتصال محلی نیز توصیف کرد.
توجه داشته باشید که وزن های آشکارساز ویژگی هنگام حرکت بر روی تصویر ثابت می مانند ، که به عنوان اشتراک پارامتر نیز شناخته می شود. برخی از پارامترها ، مانند مقادیر وزن ، در حین تمرین از طریق فرایند انتشار مجدد و کاهش شیب تنظیم می شوند. با این حال ، سه پارامتر بزرگ وجود دارد که بر حجم حجم خروجی تأثیر می گذارد و باید قبل از شروع آموزش شبکه عصبی تنظیم شود. این شامل:
- 1. تعداد فیلترها بر عمق خروجی تأثیر می گذارد. به عنوان مثال ، سه فیلتر مجزا سه نقشه ویژگی مختلف را ایجاد می کند و عمق سه را ایجاد می کند.
- 2. Stride فاصله یا تعداد پیکسل هایی است که هسته بر روی ماتریس ورودی حرکت می کند. در حالی که مقادیر گام دو یا بیشتر نادر است ، گام بزرگتر خروجی کوچکتری را به همراه دارد.
- 3. معمولاً هنگامی که فیلترها با تصویر ورودی متناسب نیستند ، از پد صفر استفاده می شود. این امر همه عناصری را که خارج از ماتریس ورودی قرار دارند بر روی صفر قرار می دهد و خروجی بزرگتر یا با اندازه یکسان تولید می کند. سه نوع روکش وجود دارد:
بالشتک معتبر: این نیز به عنوان بدون پد شناخته می شود. در این حالت ، در صورت عدم همسویی ابعاد ، آخرین تحول کنار می افتد.
پر کردن یکسان: این پد اطمینان می دهد که اندازه لایه خروجی با لایه ورودی یکسان است
بالشتک کامل: این نوع پر کننده با افزودن صفر به حاشیه ورودی ، اندازه خروجی را افزایش می دهد.
پس از هر عملیات چرخش ، یک CNN یک تغییر واحد خطی تصحیح شده (ReLU) را روی نقشه ویژگی ها اعمال می کند و غیر خطی را به مدل معرفی می کند.
همانطور که قبلاً اشاره کردیم ، یک لایه پیچشی دیگر می تواند از لایه کانولوشن اولیه پیروی کند. هنگامی که این اتفاق می افتد ، ساختار CNN می تواند سلسله مراتبی شود زیرا لایه های بعدی می توانند پیکسل ها را در زمینه های پذیرش لایه های قبلی مشاهده کنند. به عنوان مثال ، فرض کنید ما در حال تلاش برای تعیین این هستیم که آیا یک تصویر شامل دوچرخه است یا خیر. می توانید دوچرخه را مجموعه ای از قطعات بدانید. این شامل یک قاب ، دسته ، چرخ ، پدال و غیره است. هر قسمت جداگانه از دوچرخه الگوی سطح پایین تری را در شبکه عصبی ایجاد می کند و ترکیب قطعات آن الگوی سطح بالاتری را نشان می دهد و سلسله مراتبی از ویژگی ها را در CNN ایجاد می کند.
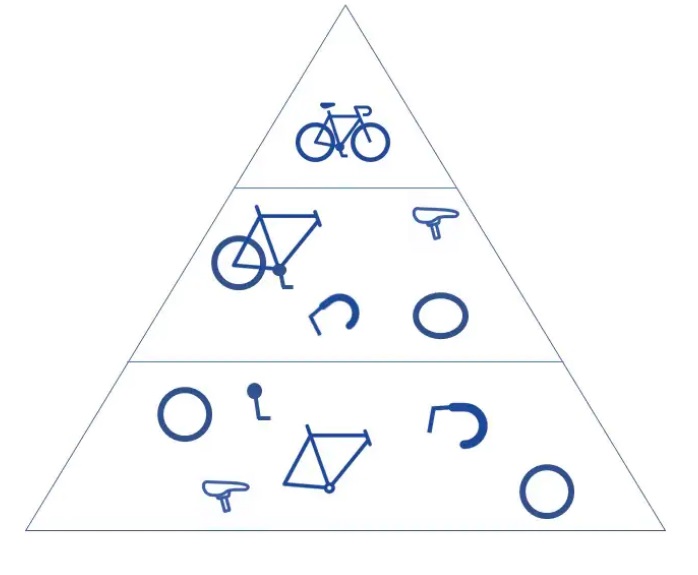
در نهایت ، لایه کانولوشن تصویر را به مقادیر عددی تبدیل می کند و به شبکه عصبی اجازه می دهد الگوهای مربوطه را تفسیر و استخراج کند.
لایه تجمع :
لایه های انباشتگی ، که به عنوان نمونه گیری کوچک نیز شناخته می شوند ، باعث کاهش ابعاد و کاهش تعداد پارامترهای ورودی می شود. مشابه لایه کانولوشن ، عملیات تجمع یک فیلتر را در کل ورودی جارو می کند ، اما تفاوت این است که این فیلتر هیچ وزنی ندارد. در عوض ، کرنل یک تابع تجمیع به مقادیر داخل میدان پذیرش اعمال می کند و آرایه خروجی را پر می کند. دو نوع اصلی تجمع وجود دارد:
حداکثر ترکیب: هنگامی که فیلتر در ورودی حرکت می کند ، پیکسل با حداکثر مقدار را برای ارسال به آرایه خروجی انتخاب می کند. به عنوان یک نکته ، این رویکرد بیشتر در مقایسه با جمع متوسط استفاده می شود.
ترکیب متوسط: با حرکت فیلتر در ورودی ، مقدار متوسط را در قسمت پذیرش برای ارسال به آرایه خروجی محاسبه می کند.
در حالی که اطلاعات زیادی در لایه جمع آوری از بین می رود ، اما مزایای زیادی نیز برای CNN دارد. آنها به کاهش پیچیدگی ، بهبود کارآیی و محدود کردن خطر اضافه وزن کمک می کنند.ایه Pooling وظیفه کاهش اندازه ویژگی های کانولود خورده را بر عهده دارد. این کار برای کاهش توان محاسباتی مورد نیاز برای پردازش داده ها از طریق کاهش ابعاد است. علاوه بر این برای استخراج ویژگی های برتر که از نظر دورانی و مکانی یکسان هستند ، مفید است و بنابراین روند آموزش موثر مدل را حفظ می کند.دو نوع Pooling وجود دارد: Max Pooling حداکثر مقدار از تصویر پوشانده شده را برمی گرداند. از طرف دیگر ، Average Pooling میانگین تمام مقادیر را از بخش تحت پوشش برمی گرداند.
پس از طی مراحل بالا ، ما با موفقیت مدل را قادر به درک ویژگی ها کردیم. درادامه ، ما قصد داریم خروجی نهایی را مسطح کرده و آن را به یک شبکه عصبی منظم برای اهداف طبقه بندی تغذیه کنیم.
لایه کاملاً متصل : (Fully Connected Layer)
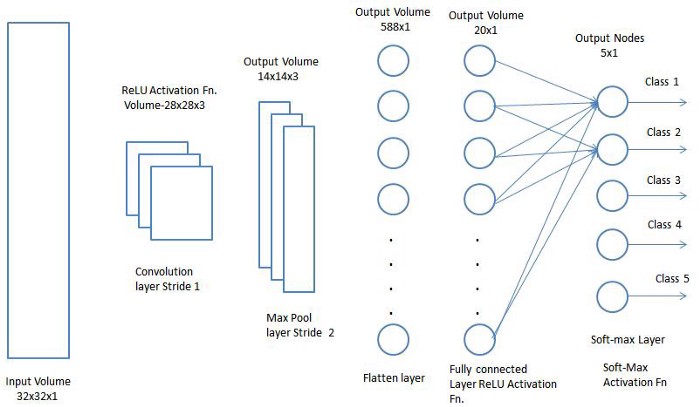
نام لایه کامل متصل به درستی خود را توصیف می کند. همانطور که قبلاً ذکر شد ، مقادیر پیکسل تصویر ورودی به طور مستقیم به لایه خروجی در لایه های تا حدی متصل نمی شوند. با این حال ، در لایه کاملاً متصل ، هر گره در لایه خروجی مستقیماً به یک گره در لایه قبلی متصل می شود.این لایه وظیفه طبقه بندی را بر اساس ویژگی های استخراج شده از لایه های قبلی و فیلترهای مختلف آنها انجام می دهد. در حالی که لایه های متقاطع و یکپارچه تمایل به استفاده از توابع ReLu دارند ، لایه های FC معمولاً از یک تابع فعال سازی softmax برای طبقه بندی مناسب ورودی ها استفاده می کنند و احتمال آن را از 0 تا 1 تولید می کنند.
موفق باشید
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید