
الگوریتم AlphaZero
الگوریتم AlphaGo
اگر دنیای هوش مصنوعی را دنبال می کنید، احتمالا در مورد AlphaGo شنیده اید.
بازی باستانی چینی Go، زمانی تصور میشد که برای ماشینها غیرممکن است. موقعیت های تخته آن (17010170^10) بیشتر از اتم های موجود در جهان است. استادان بزرگ مرتباً بهترین برنامههای کامپیوتری Go را با نقصهای پوچ (10 یا 15 سنگ!) زیر پا میگذاشتند. و تصمیمات خود را بر اساس مفاهیم استراتژیک انتزاعی – جوزکی، فوسکی، سنته، تنوکی، تعادل – توجیه میکردند. که معتقد بودند رایانهها هرگز قادر به انجام آنها نیستند.
مسابقه AlphaGo و استاد لی سدول
دمیس حسابیس و تیمش در DeepMind اعتقاد دیگری داشتند. و آنها سه سال زحمت کشیدند تا این عقیده را ثابت کنند. جمعآوری دادههای Go از پایگاههای اطلاعاتی خبره، تنظیم معماری شبکههای عصبی عمیق، و توسعه استراتژیهای ترکیبی که علیه مردم و همچنین ماشینها طراحی شده است. در نهایت، تلاشهای آنها به برنامهای پیچیده و استراتژیک به اوج رسید که آنها AlphaGo نامیدند. و با استفاده از میلیونها ساعت زمان CPU و TPU آموزش دیدند. و قادر به رقابت با بهترین بازیکنان Go بودند. آنها مسابقه ای بین AlphaGo و استاد بزرگ لی سدول راه اندازی کردند.
الگوریتم AlphaZero
اما من اینجا نیستم که در مورد AlphaGo صحبت کنم. من اینجا هستم تا درباره AlphaZero، الگوریتمی که برخی از محققان DeepMind یک سال بعد منتشر کردند، صحبت کنم. الگوریتمی که از هیچ اطلاعات قبلی یا بازیهای انجامشده توسط انسان استفاده نمیکند. و با چیزی جز قوانین بازی شروع نمیشود. الگوریتمی که توانست نسخه اصلی AlphaGo را تنها در چهار ساعت زمان آموزشی به راحتی شکست دهد. الگوریتمی که می تواند بدون تغییر در شطرنج، شوگی و تقریباً هر بازی کلاسیک دیگری با اطلاعات کامل و بدون عناصر تصادفی اعمال شود.
اگر برنامههای رایانهای میتوانستند احساس تحقیر کنند. AlphaZero هر برنامه تجاری شطرنج هوش مصنوعی یا Go را مملو از شرم میکرد. هر یک از آنها (از جمله AlphaGo اصلی) از پایگاههای جدولی از پیش محاسبهشده خیلی بزرگ از حرکات. مجموعه دادههای حرفهای «بازیهای خوب» و توابع اکتشافی بهدقت ساختهشده استفاده میکنند.
جستجوی درخت مونت کارلو
بنابراین آیا این بدان معناست که ما همه بازی های کلاسیک دو نفره را حل کرده ایم؟ نه کاملا. اما باید تمام حالت های بازی ممکن را که از یک موقعیت معین قابل دسترسی هستند. بررسی کند تا مقدار یک حالت را محاسبه کند. بنابراین، اگرچه استراتژیهای بهینه برای بازیهای پیچیده مانند شطرنج و Go وجود دارد، درختهای بازی آنها آنقدر بزرگ هستند که یافتن آنها غیرممکن است.
دلیل پیشرفت آهسته DFS
دلیل پیشرفت آهسته DFS این است که هنگام تخمین مقدار یک حالت معین در جستجو، هر دو بازیکن باید به طور بهینه بازی کنند. و حرکتی را انتخاب کنند که بهترین ارزش را به آنها می دهد و نیاز به بازگشت پیچیده دارد. شاید، به جای انتخاب حرکات بهینه (که از نظر محاسباتی بسیار گران است)، بتوانیم با وادار کردن بازیکنان به انتخاب حرکات تصادفی از آنجا به بعد، ارزش یک حالت را محاسبه کنیم. و ببینیم چه کسی برنده می شود. یا شاید حتی میتوانیم از روشهای اکتشافی محاسباتی ارزان استفاده کنیم تا بازیکنان احتمال بیشتری برای انتخاب حرکات خوب داشته باشند.
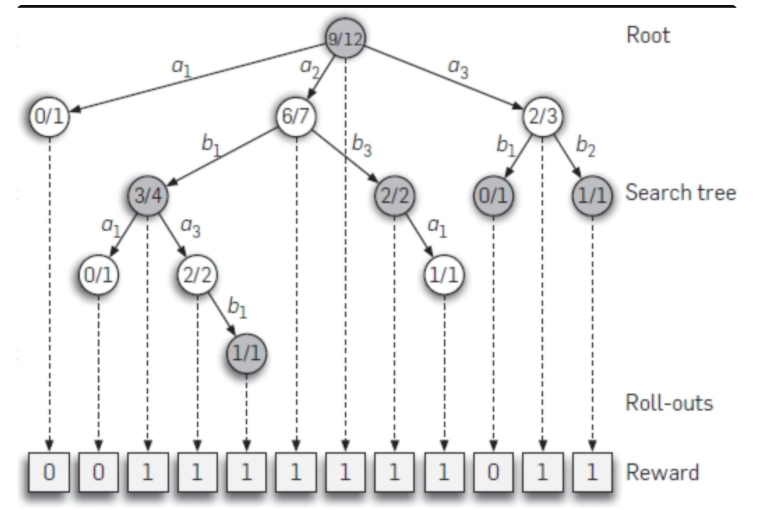
ایده درخت مونت کارلو
این ایده اصلی بین جستجوی درخت مونت کارلو است – از اکتشاف تصادفی برای تخمین ارزش یک حالت استفاده کنید. ما یک بازی تصادفی را “بازی” می نامیم. اگر 1000 بازی را از یک موقعیت مشخص X انجام دهید. و بازیکن 1 در 60 درصد مواقع برنده شود.به احتمال زیاد آن موقعیت X برای بازیکن 1 بهتر از بازیکن 2 است. بنابراین، ما می توانیم یک تابع monte_carlo_value() ایجاد کنیم که مقدار حالتی با استفاده از تعداد معینی از بازی های تصادفی است. تنها تفاوت این است که به جای تکرار در میان همه احتمالات حرکت و انتخاب “بهترین”، به طور تصادفی حرکات را انتخاب می کنیم.
مطالب زیر را حتما مطالعه کنید

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

ذخیره و بارگذاری مدل در پایتون

محل بررسی مدل های شبکه عصبی
شبکه خودرمزنگار متغیر (variational autoencoder) چیست؟

تجزیه و تحلیل داده با پایتون

آموزش Pytorch (قسمت سوم)
1 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
از اینکه درباره این موضوع مطلب گذاشتید مچکرم ، اما کاش کاملتر میبود
پیشنهاد من برای کسایی ک دنبال مطلب کاملتری هستن:
مقاله “جست جوی درخت مونته کارلو برای یادگیری تقویتی بیزی”