
تاثیر نرخ یادگیری بر عملکرد شبکه عصبی
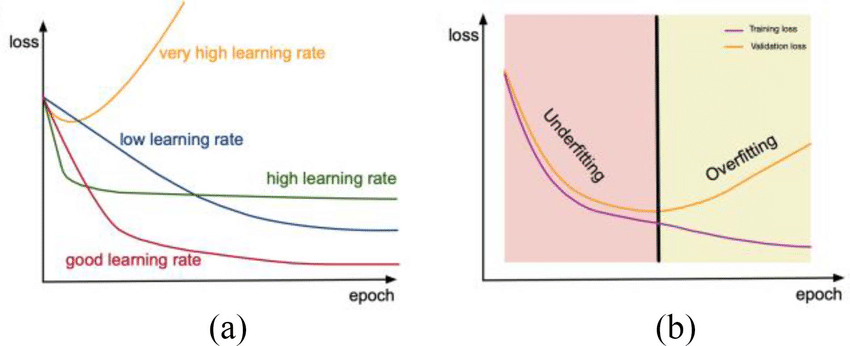
شبکههای عصبی یادگیری عمیق با استفاده از الگوریتم بهینهسازی گرادیان نزولی تصادفی آموزش داده میشوند.نرخ یادگیری یک هایپرپارامتر است که کنترل میکند هر بار که وزنهای مدل بهروزرسانی میشوند چقدر مدل را در پاسخ به خطای تخمینی تغییر دهیم. انتخاب نرخ یادگیری چالش برانگیز است زیرا یک مقدار بسیار کوچک ممکن است منجر به یک فرآیند آموزشی طولانی شود که ممکن است گیر کند، در حالی که یک مقدار بیش از حد بزرگ ممکن است منجر به یادگیری سریع مجموعه ای از وزنه های غیربهینه یا یک فرآیند آموزشی ناپایدار شود.در این مطلب میخوهیم به بررسی تاثیر نرخ یادگیری بر روی عملکرد شبکه عصبی بپردازیم.
نرخ یادگیری ممکن است مهمترین هایپرپارامتر در هنگام پیکربندی شبکه عصبی شما باشد. بنابراین بسیار مهم است که بدانیم چگونه اثرات آن را بر عملکرد مدل بررسی کنیم.
در این آموزش، درباره اثرات نرخ یادگیری، زمانبندی نرخ یادگیری و نرخهای یادگیری تطبیقی بر عملکرد مدل صحبت خواهیم کرد.
تاثیر نرخ یادگیری و گرادیان نزولی
شبکه های عصبی یادگیری عمیق با استفاده از الگوریتم گرادیان نزولی تصادفی آموزش داده می شوند.
گرادیان نزولی تصادفی یک الگوریتم بهینهسازی است که خطای گرادیان را برای وضعیت فعلی مدل با استفاده از مثالهایی از مجموعه داده آموزشی تخمین میزند، سپس وزنهای مدل را با استفاده از الگوریتم پس انتشار خطاها بهروزرسانی میکند.
مقداری که وزنها در طول آموزش به روز می شوند، اندازه گام یا “نرخ یادگیری” نامیده می شود.
به طور خاص، نرخ یادگیری یک هایپرپارامتر قابل تنظیم است که در آموزش شبکههای عصبی استفاده میشود که مقدار مثبت کمی دارد، اغلب در محدوده بین 0.0 و 1.0.همچنین این هایپرپارامتر سرعت انطباق مدل با مسئله را کنترل می کند.
تاثیر نرخ یادگیری را میتوان از طریق مقدار انتخابی برای آن سنجید.مقادیر کوچکتر آن به دورههای آموزشی بیشتری نیاز دارند، با توجه به تغییرات کوچکتری که در وزنها در هر بهروزرسانی ایجاد میشود، در حالی که مقادیر بزرگتر منجر به تغییرات سریع و نیاز به دورههای آموزشی کمتری میشود.مقادیر خیلی زیاد نیز میتواند باعث شود که مدل خیلی سریع به یک راهحل غیربهینه همگرا شود، در حالی که مقادیر بسیار کوچک میتواند باعث گیرکردن فرآیند شود.
چالش آموزش شبکه های عصبی یادگیری عمیق شامل انتخاب دقیق نرخ یادگیری است. ممکن است مهمترین هایپرپارامتر برای مدل باشد.اکنون که با مفاهیم اولیه آشنا شدیم، بیایید ببینیم چگونه میتوانیم نرخ یادگیری را برای شبکههای عصبی مدیریت کنیم.
مدیریت نرخ یادگیری با کمک کتابخانه کراس
کتابخانه یادگیری عمیق کراس به شما این امکان را می دهد که به راحتی میزان یادگیری را برای تعدادی از تغییرات مختلف الگوریتم بهینه سازی شیب نزولی تصادفی مدیریت کنید.
گرادیان نزولی تصادفی
کراس کلاس SGD را ارائه می دهد که بهینه ساز گرادیان نزولی تصادفی را با نرخ یادگیری و حرکت پیاده سازی می کند.ابتدا، یک نمونه از کلاس باید ایجاد و پیکربندی شود. سپس هنگام فراخوانی تابع fit() در مدل، به آرگومان “بهینه ساز” مشخص شود.نرخ یادگیری پیش فرض 0.01 است.
from keras.optimizers import SGD ... opt = SGD() model.compile(..., optimizer=opt)
نرخ یادگیری را می توان از طریق آرگومان “lr” و تکانه را می توان از طریق آرگومان “تکانه” مشخص کرد.
from keras.optimizers import SGD ... opt = SGD(lr=0.01, momentum=0.9) model.compile(..., optimizer=opt)
با کاهش نرخ یادگیری، نرخ یادگیری در هر به روز رسانی (به عنوان مثال پایان هر دسته کوچک) به صورت زیر محاسبه می شود:
lrate = initial_lrate * (1 / (1 + decay * iteration))
در جایی که lrate نرخ یادگیری برای دوره فعلی است، initial_lrate نرخ یادگیری مشخص شده به عنوان آرگومان برای SGD است، decay نرخ decay است که بیشتر از صفر است و تکرار عدد بهروزرسانی فعلی است.
from keras.optimizers import SGD ... opt = SGD(lr=0.01, momentum=0.9, decay=0.01) model.compile(..., optimizer=opt)
زمانبندی نرخ یادگیری
کراس از برنامههای نرخ یادگیری از طریق callbacks پشتیبانی میکند.
فراخوانها جدا از الگوریتم بهینهسازی عمل میکنند. اگرچه نرخ یادگیری مورد استفاده توسط الگوریتم بهینهسازی را تنظیم میکنند. استفاده از SGD هنگام استفاده از زمانبندی نرخ یادگیری callback توصیه می شود.
Callback ها نمونه سازی و پیکربندی می شوند. سپس در یک لیست به آرگومان “callbacks” تابع fit() در هنگام آموزش مدل مشخص می شوند.
ReduceLROnPlateau را کراس ارائه میکند. که نرخ یادگیری را هنگامی که یک فلات در عملکرد مدل شناسایی میشود، تنظیم میکند.این callbackبرای کاهش نرخ یادگیری پس از توقف بهبود مدل با امید به تنظیم دقیق وزن های مدل طراحی شده است.
ReduceLROnPlateau از شما میخواهد که معیاری را برای نظارت در طول آموزش از طریق آرگومان «monitor» مشخص کنید. مقداری که نرخ یادگیری از طریق آرگومان «factor» ضرب میشود . آرگومان «patience» که تعداد دورههای آموزشی را قبل از ایجاد تغییر در میزان یادگیری مشخص میکند.
# snippet of using the ReduceLROnPlateau callback from keras.callbacks import ReduceLROnPlateau ... rlrop = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=100) model.fit(..., callbacks=[rlrop])
# snippet of using the LearningRateScheduler callback from keras.callbacks import LearningRateScheduler ... def my_learning_rate(epoch, lrate): return lrate lrs = LearningRateScheduler(my_learning_rate) model.fit(..., callbacks=[lrs])
گرادیان نزولی نرخ یادگیری تطبیقی
کراس همچنین مجموعهای از گرادیان تصادفی ساده را ارائه میکند که از نرخهای یادگیری تطبیقی پشتیبانی میکنند.
از آنجا که هر روش سرعت یادگیری را تطبیق می دهد، اغلب یک نرخ یادگیری به ازای هر وزن مدل، پیکربندی نیاز است.
سه روش متداول نرخ یادگیری تطبیقی مورد استفاده عبارتند از:
RMSProp Optimizer
from keras.optimizers import RMSprop ... opt = RMSprop() model.compile(..., optimizer=opt)
Adagrad Optimizer
from keras.optimizers import Adagrad ... opt = Adagrad() model.compile(..., optimizer=opt)
Adam Optimizer
from keras.optimizers import Adam ... opt = Adam() model.compile(..., optimizer=opt)
دیدگاهتان را بنویسید