
ایجاد ربات اقدام پیوسته با استفاده از یادگیری تقویتی عمیق
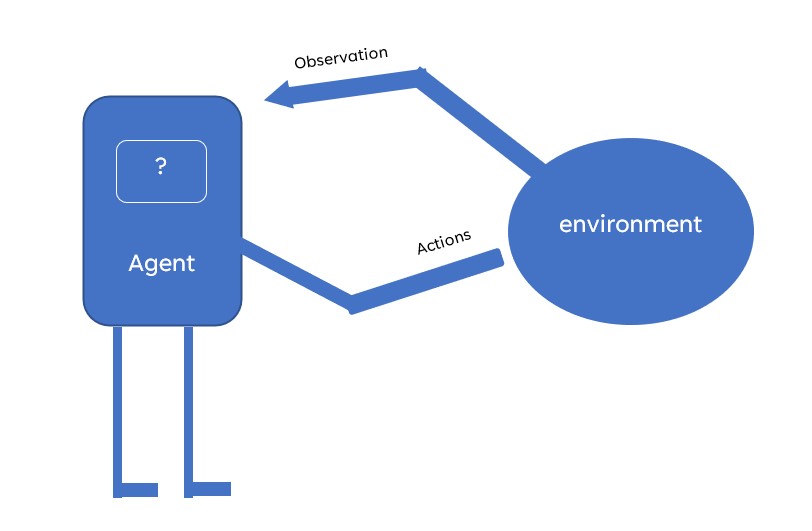
برای حل هر مسئلهای با استفاده از یادگیری تقویتی، به یک محیط کاملاً تعریف شده نیاز داریم که مسئله دنیای واقعی ما را شبیه سازی کند و عاملی که با در نظر گرفتن ورودی به عنوان مشاهدات، اقداماتی را در محیط ایجاد کند.
فهرست مطالب
– ایجاد یک محیط سفارشی با استفاده از محیط OpenAI
– ایجاد یک عامل با استفاده از DDPG (مفهوم MDP)
– تکنیک هایی برای افزایش عملکرد مدل
ایجاد یک محیط سفارشی با استفاده از محیط OPEN IA
قبل از ایجاد محیط خود، کتابخانه های مهم را فراخوانی کنیم.
import gym from gym import spaces import numpy as np
حالا بیایید محیطی بسازیم که در آن بودجه داشته باشیم و بخواهیم آن را در تبلیغات فیس بوک و اینستاگرام خرج کنیم. این هزینه ها فروش هایی را به ما می دهد که می خواهیم آن را به حداکثر برسانیم. بنابراین، در اینجا چیزی است که ما برای ایجاد یک محیط اولیه در پایتون نیاز داریم.

OurCustomEnv(gym.Env):
ef __init__(self, sales_function, obs_range, action_range):
self.budget = 1000 #fixing the budget
self.sales_function = sales_function #calculating sales based on spends
#we create an observation space with predefined range
self.observation_space = spaces.Box(low = obs_range[0], high = obs_range[1],
dtype = np.float32)
#similar to observation, we define action space
self.action_space = spaces.Box(low = action_range[0], high = action_range[1],
dtype = np.float32)
def step(self, action):
self.budget -= np.sum(action) #remaining budget will be old budget-sum of both spends
reward = 0.0
reward = self.sales_functions(action) #gives total sales based on spends
done = True #Condition for completion of episode
info = {}
return action, reward, done, info
def reset(self):
self.budget = 1000
return np.array([0,0])
حداقل الزامات برای اجرای env این است که شما باید یک مقدار دهی اولیه داشته باشید، یک تابع مرحله ای (همانطور که مدل باید در صورت انجام کاری چگونه رفتار کند) که دارای پاداش، اطلاعات (هر اطلاعاتی که نیاز دارید در طول آموزش اشکال زدایی یا ردیابی کنید، عامل از این استفاده نمی کند) و وضعیت پایان و یک تابع بازنشانی. اگر محیط ما خاتمه یابد، چه چیزی باید دوباره تنظیم شود. برای حفظ تکرارپذیری، می توانید یک تابع با مقداردهی تصادفی ایجاد کنید.
ایجاد یک عامل DDPG در یادگیری تقویتی
ما از پیاده سازی DDPG از Phil (Timothy P. Lillicrap 2015) استفاده خواهیم کرد. DDPG دارای اجزای اساسی مانند بافر پخش مجدد است (برای ذخیره تمام انتقال ها – وضعیت مشاهده، عمل، پاداش، انجام شده، وضعیت مشاهده جدید).
MDP (فرایند تصمیم مارکوف) مستلزم آن است که عامل بر اساس وضعیت فعلی بهترین اقدام را انجام دهد. این پاداش مرحله و حالت مشاهده جدید می دهد. به این مشکل MDP می گویند. ما این مقادیر را در بافری به نام replay buffer ذخیره می کنیم.
کاری که یک بافر پاسخ انجام می دهد چیزی است که این الگوریتم را از خط مشی خارج می کند. بنابراین، در ابتدا، عامل ما با اقدامات تصادفی شروع می کند و ما آن را در حافظه تغذیه می کنیم تا زمانی که به batch size برسد. سپس از این نقطه، عامل تمام اطلاعات (وضعیتها، اقدامات، پاداشها، خاتمه، وضعیت جدید) را از بافر پخش مجدد میگیرد و در این مورد یاد میگیرد. این یک الگوریتم خارج از سیاست نامیده می شود، زمانی که نماینده شما بر اساس تجربیات گذشته یاد می گیرد و نه بر اساس اقدامات فعلی که انجام می دهد. یک الگوریتم مبتنی بر سیاست به این معنی است یاد میگیرد، یک دسته میسازد، از آن یاد میگیرد و سپس آن دسته را تخلیه میکند. بنابراین، ما بافر پخش خود را ایجاد می کنیم.
قبل از شروع به ایجاد عامل خود، بیایید کتابخانه های مهم را فراخوانی کنیم.
import torch as T import torch.nn as nn import torch.nn.functional as F import torch.optim as optim
پاسخ بافر:
class ReplayBuffer():
def __init__(self, max_size, input_shape=2, n_actions=2):
self.mem_size = max_size
self.mem_cntr = 0
self.state_memory = np.zeros((self.mem_size, input_shape))
self.new_state_memory = np.zeros((self.mem_size, input_shape))
self.action_memory = np.zeros((self.mem_size, n_actions))
self.reward_memory = np.zeros(self.mem_size)
self.terminal_memory = np.zeros(self.mem_size, dtype=np.bool)
def store_transition(self, state, action, reward, state_, done):
index = self.mem_cntr % self.mem_size
self.state_memory[index] = state
self.new_state_memory[index] = state_
self.terminal_memory[index] = done
self.reward_memory[index] = reward
self.action_memory[index] = action
self.mem_cntr += 1
def sample_buffer(self, batch_size):
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, batch_size)
states = self.state_memory[batch]
states_ = self.new_state_memory[batch]
actions = self.action_memory[batch]
rewards = self.reward_memory[batch]
dones = self.terminal_memory[batch]
return states, actions, rewards, states_, dones
بازیگر-منتقد در یادگیری تقویتی:
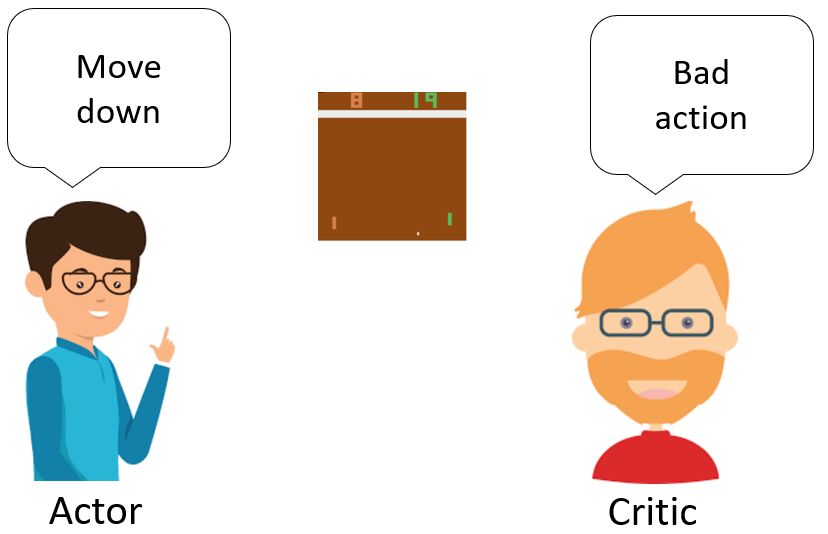
اکنون به سراغ روش اصلی منتقد عامل می رویم. عامل بر اساس یک خط مشی تصمیم می گیرد، منتقد جفت حالت-عمل را ارزیابی می کند و به آن مقدار Q می دهد. اگر جفت حالت-عمل از نظر منتقدان خوب باشد، مقدار Q بالاتری خواهد داشت و بالعکس.
شبکه منتقد در یادگیری تقویتی:
class CriticNetwork(nn.Module):
def __init__(self, beta):
super(CriticNetwork, self).__init__()
self.input_dims = 2 #fb, insta
self.fc1_dims = 256 #hidden layers
self.fc2_dims = 256 #hidden layers
self.n_actions = 2 #fb, insta
self.fc1 = nn.Linear(2 + 2, self.fc1_dims) #state + action
self.fc2 = nn.Linear(self.fc1_dims, self.fc2_dims)
self.q1 = nn.Linear(self.fc2_dims, 1)
self.optimizer = optim.Adam(self.parameters(), lr=beta)
self.device = T.device('cuda' if T.cuda.is_available() else 'cpu')
self.to(self.device)
def CriticNetwork(self, state, action):
q1_action_value = self.fc1(T.cat([state, action], dim=1 ))
q1_action_value = F.relu(q1_action_value)
q1_action_value = self.fc2(q1_action_value)
q1_action_value = F.relu(q1_action_value)
q1 = self.q1(q1_action_value)
return q1
اکنون به شبکه عامل میرویم، شبکهای مشابه ایجاد کردهایم، اما در اینجا چند نکته کلیدی وجود دارد که هنگام ساخت عامل باید به خاطر بسپارید.
مقدار اولیه وزن ضروری نیست، اما به طور کلی، اگر مقداری ابتدایی به آن بدهیم، سریعتر یاد می گیرد.
انتخاب بهینه ساز بسیار مهم است، بهینه سازهای مختلف می توانند تفاوت های زیادی ایجاد کنند.
اکنون، نحوه انتخاب آخرین تابع فعال سازی واقعاً به نوع فضای عملی که استفاده می کنید بستگی دارد، به عنوان مثال، اگر کوچک باشد و همه مقادیر مانند [-1,-2,-3] تا [1,2,3] باشند. می توانید ادامه دهید و tanh ، اگر [-2,-4000,-230] تا [2,6000,560] دارید، ممکن است بخواهید عملکرد فعال سازی را تغییر دهید.
شبکه عامل در یادگیری تقویتی:
class ActorNetwork(nn.Module):
def __init__(self, alpha):
super(ActorNetwork, self).__init__()
self.input_dims = 2
self.fc1_dims = fc1_dims
self.fc2_dims = fc2_dims
self.n_actions = 2
self.fc1 = nn.Linear(self.input_dims, self.fc1_dims)
self.fc2 = nn.Linear(self.fc1_dims, self.fc2_dims)
self.mu = nn.Linear(self.fc2_dims, self.n_actions)
self.optimizer = optim.Adam(self.parameters(), lr=alpha)
self.device = T.device('cuda' if T.cuda.is_available() else 'cpu')
self.to(self.device)
def forward(self, state):
prob = self.fc1(state)
prob = F.relu(prob)
prob = self.fc2(prob)
prob = F.relu(prob)
#fixing each agent between 0 and 1 and transforming each action in env
mu = T.sigmoid(self.mu(prob))
return mu
توجه: ما از 2 لایه مخفی استفاده کردیم زیرا فضای عمل ما کوچک بود و محیط خیلی پیچیده نبود.
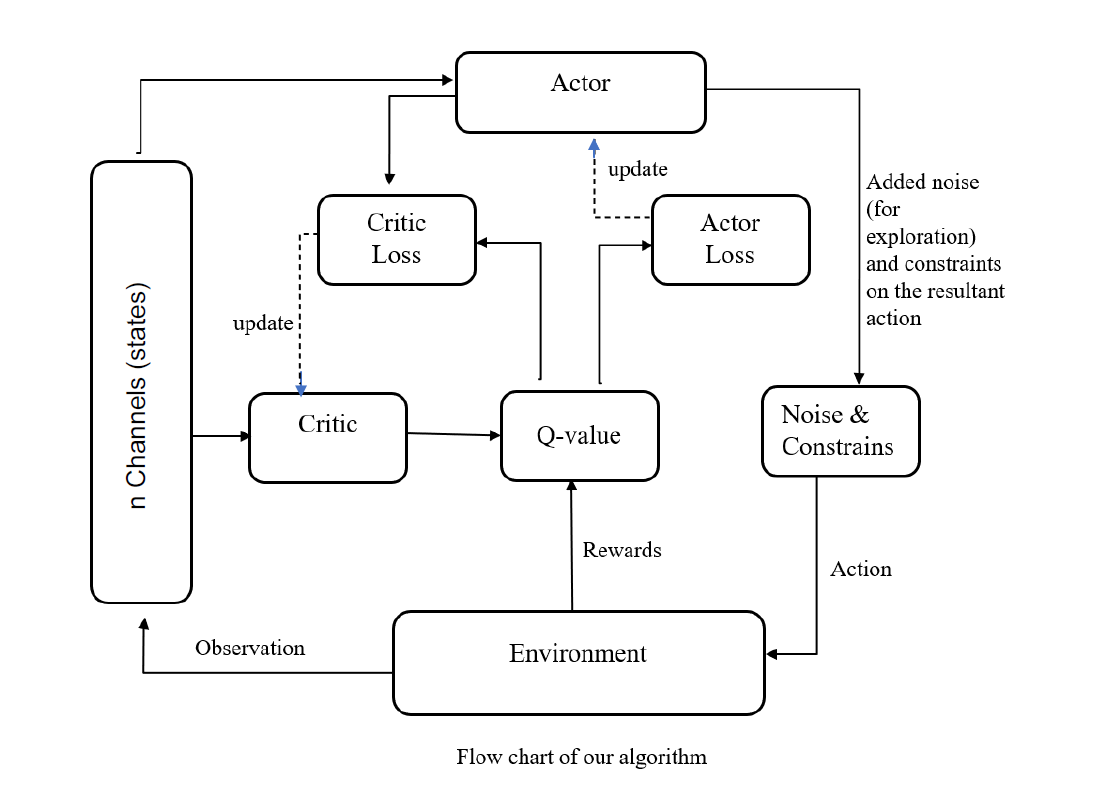
درست مانند gym env، عامل نیز شرایطی دارد. ما شبکههای هدف خود را با همان وزن شبکههای اصلی (A-C) اولیهسازی کردیم. از آنجایی که ما در حال تعقیب یک هدف متحرک هستیم، شبکه های هدف ثبات ایجاد می کنند و به آموزش شبکه های اصلی کمک می کنند.
ما با تمام الزامات مقداردهی اولیه می کنیم، همانطور که ممکن است متوجه شده باشید ما یک پارامتر تابع ضرر نیز داریم. ما میتوانیم از توابع ضرر مختلف استفاده کنیم و هر کدام را که برای ما بهتر کار میکند را انتخاب میکنیم.
در اینجا ما انتخاب تابع عمل را شامل میشویم، میتوانید یک تابع ارزیابی نیز ایجاد کنید، که فضای عمل را بدون نویز خروجی میدهد.
بههنگامسازی تابع پارامتر، حالا این جایی است که ما شبکههای نرم (هدف)و به روزرسانی های سخت (شبکههای اصلی)را انجام میدهیم. اکنون در اینجا تنها یک پارامتر برای Tau, در نظر گرفته شدهاست.
از آن برای به روز رسانی نرم شبکههای هدف مان استفاده میشود، آنها بهترین Tau هستند که ۰.۰۰۱ باشد و معمولا در میان مقالات مختلف بهتر است (شما میتوانید سعی کنید با آن بازی کنید).
class Agent(object):
def __init__(self, alpha, beta, input_dims=2, tau, env, gamma=0.99,
n_actions=2, max_size=1000000, batch_size=64):
self.gamma = gamma
self.tau = tau
self.memory = ReplayBuffer(max_size)
self.batch_size = batch_size
self.actor = ActorNetwork(alpha)
self.critic = CriticNetwork(beta)
self.target_actor = ActorNetwork(alpha)
self.target_critic = CriticNetwork(beta)
self.scale = 1.0
self.noise = np.random.normal(scale=self.scale,size=(n_actions))
self.update_network_parameters(tau=1)
def choose_action(self, observation):
self.actor.eval()
observation = T.tensor(observation, dtype=T.float).to(self.actor.device)
mu = self.actor.forward(observation).to(self.actor.device)
mu_prime = mu + T.tensor(self.noise(),
dtype=T.float).to(self.actor.device)
self.actor.train()
return mu_prime.cpu().detach().numpy()
def remember(self, state, action, reward, new_state, done):
self.memory.store_transition(state, action, reward, new_state, done)
def learn(self):
if self.memory.mem_cntr < self.batch_size:
return
state, action, reward, new_state, done =
self.memory.sample_buffer(self.batch_size)
reward = T.tensor(reward, dtype=T.float).to(self.critic.device)
done = T.tensor(done).to(self.critic.device)
new_state = T.tensor(new_state, dtype=T.float).to(self.critic.device)
action = T.tensor(action, dtype=T.float).to(self.critic.device)
state = T.tensor(state, dtype=T.float).to(self.critic.device)
self.target_actor.eval()
self.target_critic.eval()
self.critic.eval()
target_actions = self.target_actor.forward(new_state)
critic_value_ = self.target_critic.forward(new_state, target_actions)
critic_value = self.critic.forward(state, action)
target = []
for j in range(self.batch_size):
target.append(reward[j] + self.gamma*critic_value_[j]*done[j])
target = T.tensor(target).to(self.critic.device)
target = target.view(self.batch_size, 1)
self.critic.train()
self.critic.optimizer.zero_grad()
critic_loss = F.mse_loss(target, critic_value)
critic_loss.backward()
self.critic.optimizer.step()
self.critic.eval()
self.actor.optimizer.zero_grad()
mu = self.actor.forward(state)
self.actor.train()
actor_loss = -self.critic.forward(state, mu)
actor_loss = T.mean(actor_loss)
actor_loss.backward()
self.actor.optimizer.step()
self.update_network_parameters()
def update_network_parameters(self, tau=None):
if tau is None:
tau = self.tau
actor_params = self.actor.named_parameters()
critic_params = self.critic.named_parameters()
target_actor_params = self.target_actor.named_parameters()
target_critic_params = self.target_critic.named_parameters()
critic_state_dict = dict(critic_params)
actor_state_dict = dict(actor_params)
target_critic_dict = dict(target_critic_params)
target_actor_dict = dict(target_actor_params)
for name in critic_state_dict:
critic_state_dict[name] = tau*critic_state_dict[name].clone() +
(1-tau)*target_critic_dict[name].clone()
se
lf.target_critic.load_state_dict(critic_state_dict)
for name in actor_state_dict:
actor_state_dict[name] = tau*actor_state_dict[name].clone() +
(1-tau)*target_actor_dict[name].clone()
self.target_actor.load_state_dict(actor_state_dict)
مهم ترین بخش، عملکرد یادگیری است. ابتدا شبکه را با نمونه ها تغذیه می کنیم تا به batch size برسد و سپس نمونه برداری از دسته ها را برای به روز رسانی شبکه های خود آغاز می کنیم. ضررهای منتقد وعامل را محاسبه کنید. سپس فقط نرم افزار تمام پارامترها را به روز کنید.
The most crucial part is the learning function. First, we feed the network with samples until it reaches batch size and then start sampling from batches to update our networks. Calculate critic and actor losses. Then just soft update all the parameters.
env = OurCustomEnv(sales_function, obs_range, act_range)
agent = Agent(alpha=0.000025, beta=0.00025, tau=0.001, env=env,
batch_size=64, n_actions=2)
score_history = []
for i in range(10000):
obs = env.reset()
done = False
score = 0
while not done:
act = agent.choose_action(obs)
new_state, reward, done, info = env.step(act)
agent.remember(obs, act, reward, new_state, int(done))
agent.learn()
score += reward
obs = new_state
score_history.append(score)
نتایج:
فقط در چند دقیقه، ما نتایج آموزش را آماده می کنیم. عامل تقریباً بودجه کامل خود را تخلیه می کند و ما یک نمودار در طول آموزش داریم .
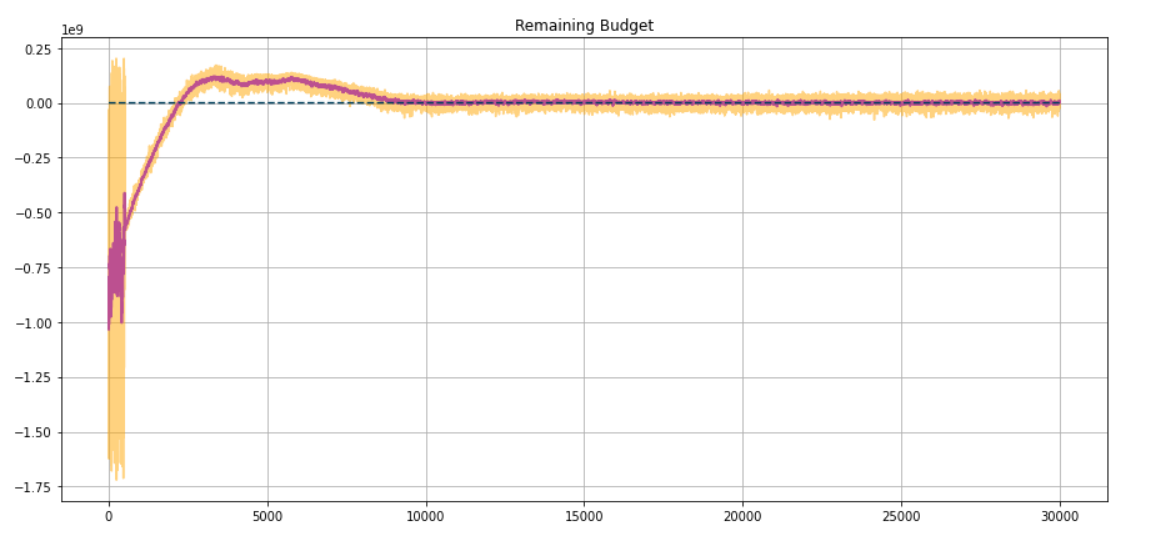
اگر تغییراتی در هایپرپارامترها و توابع پاداش ایجاد کنیم، میتوان به این نتایج حتی سریعتر دست یافت.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید