
آموزش Pytorch (قسمت سوم)

کتابخانه Pytorch
به قسمت سوم از مجموعه PyTorch خوش آمدين. در قسمت قبلی درباره PyTorch ، نقاط قوت و اینکه چرا باید آن را یاد بگیریم ، بحث کردیم. همچنین نگاهی اجمالی داشتیم به تنسور ها که درواقع ساختار داده اصلی مورد استفاده در PyTorch هستند. ما در این قسمت، به برخی نمونه های کاربردی استفاده از شبکه های از قبل آموزش دیده که در ماژول TorchVision برای کلاسه بندی تصویر وجود دارند، می پردازیم.
بسته TorchVision متشکل از مجموعه داده های رایج و متداول ، معماری مدل و تبدیلات رایج تصویر برای بینایی رایانه ای است. در واقع ، اگر شما علاقه مند به بینایی رایانه ای هستید و از PyTorch استفاده می کنید ، TorchVision بسیار به شما کمک خواهد کرد!
1- مدل هاي از قبل آموزش ديده براي كلاسه بندي تصوير
مدل های از قبل آموزش دیده ، مدل های شبکه عصبی هستند که روی مجموعه داده های بزرگ معیار مانند ImageNet آموزش داده شده اند. جامعه یادگیری عمیق از این مدل های متن باز بسیار بهره برده است. همچنین ، مدل های از قبل آموزش دیده ، عامل اصلی پیشرفت سریع در تحقیقات بینایی رایانه ای هستند. سایر محققان و متخصصان می توانند به جای اینکه همه چیز را از ابتدا دوباره بسازند ، از این مدل های پیشرفته استفاده کنند.
در جدول زمانی زیر خلاصه ای از چگونگی بهبود مدل های پیشرفته در طول زمان ارائه شده است. در اینجا فقط مدل هایی که در بسته TorchVision وجود دارد ، آورده شده است.
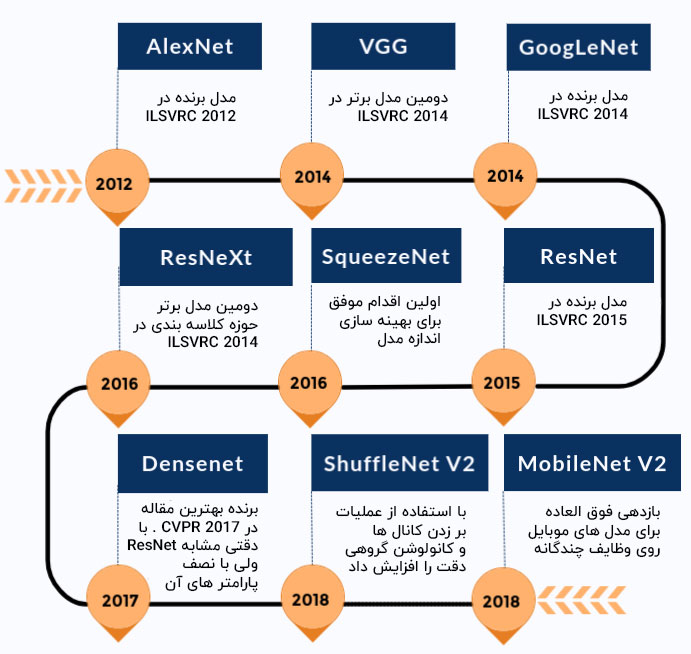
بیایید ببینیم مدل های مختلف از قبل آموزش دیده موجود چه مدل هایی هستند. ما درباره AlexNet و ResNet101 به عنوان دو مثال اصلی بحث خواهیم کرد، که هر دو شبکه روی مجموعه داده های ImageNet آموزش دیده اند.
مجموعه داده ImageNet بیش از ۱۴ میلیون تصویر دارد که توسط دانشگاه استنفورد جمع آوری شده است و به طور گسترده برای طیف وسیعی از پروژه های یادگیری عمیق مربوط به تصویر مورد استفاده قرار می گیرد. این تصاویر متعلق به کلاس ها یا برچسب های مختلف هستند. با اینکه می توان از این دو اصطلاح به جای یکدیگر استفاده کرد ، اما ما از واژه کلاس استفاده می کنیم. هدف مدل های از قبل آموزش دیده مانند AlexNet و ResNet101 ، دریافت یک تصویر به عنوان یک ورودی و پیش بینی کلاس آن است.
کلمه از قبل آموزش دیده در اینجا به این معنی است که معماری یادگیری عمیق AlexNet و ResNet101 ، قبلاً در برخی از مجموعه داده های عظیم آموزش دیده اند و بنابراین وزن ها و بایاس های حاصل مشخص است. این تفاوت بین معماری و وزن و بایاس باید کاملاً واضح باشد زیرا همانطور که در بخش بعدی خواهیم دید ، TorchVision هم دارای معماری و مدل های از قبل آموزش دیده است.
1-1- فرآيند استنباط مدل
برای تغییر این متن بر روی دکمه ویرایش کلیک کنید. لورم ایپسوم متن ساختگی با تولید سادگی نامفهوم از صنعت چاپ و با استفاده از طراحان گرافیک است.
از آنجا که قصد داریم به نحوه استفاده از مدل های از قبل آموزش دیده برای پیش بینی کلاس (برچسب) ورودی بپردازیم ، اجازه دهید در مورد روند کار در این مورد نیز بحث کنیم. از این فرآیند به عنوان مدل استنباط یاد می شود. کل روند شامل مراحل اصلی زیر است.
- خواندن تصویر ورودی
- انجام تبدیلات روی تصویر. به عنوان مثال – تغییر اندازه ، برش مرکزی ، نرمال سازی و غیره
- Forward Pass : استفاده از وزن های از قبل آموزش دیده ، برای یافتن بردار خروجی. هر عنصر در این بردار خروجی، یک اطمینانی را توصیف می کند که مدل با آن تصویر ورودی متعلق به یک کلاس خاص است.
- نمایش پیش بینی ها ، بر اساس امتیازات به دست آمده (عناصر بردار خروجی که در مرحله ۳ ذکر کردیم).
2-1- بارگذاري شبكه آموزش ديده با استفاده از TorchVision
اکنون که با فرآیند استنباط مدل آشنا شدیم و می دانیم مدل از قبل آموزش دیده به چه معناست ، حالا بیایید ببینیم چگونه می توانیم با کمک ماژول TorchVision از این مدل ها استفاده کنیم.
ابتدا ماژول TorchVision را با استفاده از دستور زیر نصب می کنیم.
pip install torchvision
در مرحله بعدی ، مدل ها را از ماژول torchvision فراخوانی مي کنیم تا ببینیم مدل ها و معماری های مختلف موجود، چه مدل هایی هستند.
from torchvision import models import torch dir(models)
خروجی ای که در بالا به دست آوردیم را با دقت مشاهده کنید.
['AlexNet', 'DenseNet', 'GoogLeNet', 'Inception3', 'MobileNetV2', 'ResNet', 'ShuffleNetV2', 'SqueezeNet', 'VGG', ... 'alexnet', 'densenet', 'densenet121', 'densenet161', 'densenet169', 'densenet201', 'detection', 'googlenet', 'inception', 'inception_v3', ... ]
توجه داشته باشید که یک ورودی به نام AlexNet و دیگری به نام alexnet وجود دارد. نامی که با حروف بزرگ نوشته شده است به کلاس پایتون (AlexNet) اشاره دارد ،در حالی که alexnet یک تابع اطمینان است که مدل تهیه شده از کلاس AlexNet را برمی گرداند. همچنین ممکن است این توابع اطمینان دارای مجموعه پارامترهای مختلف باشند. به عنوان مثال، densenet121، densenet161، densenet169، densenet201، همه نمونه هایی از کلاس DenseNet هستند اما با تعداد لایه های مختلف – به ترتیب ۱۲۱، ۱۶۱، ۱۶۹ و ۲۰۱ .
3-1- استفاده از AlexNet برای کلاسه بندی تصویر
اجازه دهید ابتدا با AlexNet که یکی از اولین شبکه های پیشرفت در شناسایی تصویر است ، شروع کنیم.
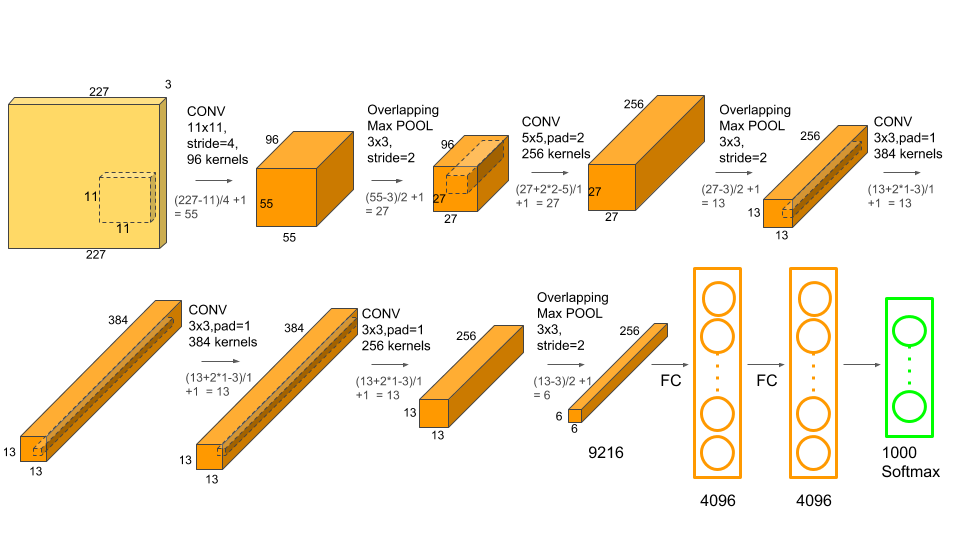
مرحله ۱: بارگذاری مدل از قبل آموزش دیده
در مرحله اول ، ما یک نمونه از شبکه را ایجاد خواهیم کرد. همچنین یک آرگومان ارسال خواهیم کرد تا تابع بتواند وزن های مدل را بارگیری کند.
alexnet = models.alexnet(pretrained=True) You will see a similar output as below # Downloading: "https://download.pytorch.org/models/alexnet-owt- 4df8aa71.pth" # to /home/hp/.cache/torch/checkpoints/alexnet-owt-4df8aa71.pth
توجه داشته باشید که معمولاً مدل های PyTorch دارای پسوند pt. یا pth. هستند
پس از بارگیری وزن ها ، می توانیم مراحل دیگر را ادامه دهیم. همچنین می توانیم جزئیات معماری شبکه را به شرح زیر بررسی کنیم.
print(alexnet)
نگران خروجی اضافی نباشید. این اساساً بخاطر عملیات و لایه های مختلف در معماری AlexNet است.
مرحله ۲: تعیین تبدیلات تصویر
هنگامی که ما مدل را داشته باشیم ، مرحله بعدی تبدیل یا تغییر شکل تصویر ورودی است تا به شکلی مناسب همراه با ویژگی هایی مانند میانگین و انحراف معیار برسیم. این مقادیر باید شبیه به مقادیری باشد که هنگام آموزش مدل استفاده شده است. این کار، اطمینان می دهد که شبکه، پاسخ های معقولی ارائه دهد.
ما می توانیم تصویر ورودی را با کمک تبدیل های موجود در ماژول TochVision پیش پردازش کنیم. در این حالت ، می توانیم از تغییرات زیر برای AlexNet و ResNet استفاده کنیم.
from torchvision import transforms transform = transforms.Compose([ #[1] transforms.Resize(256), #[2] transforms.CenterCrop(224), #[3] transforms.ToTensor(), #[4] transforms.Normalize( #[5] mean=[0.485, 0.456, 0.406], #[6] std=[0.229, 0.224, 0.225] #[7] )])
بیایید سعی کنیم آنچه در قطعه کد فوق رخ داده است را درک کنیم.
یک تغییر متغیر تعریف می کنیم که ترکیبی از تمام تبدیلات تصویر است که باید روی تصویر ورودی اعمال شود.
اندازه تصویر را به ۲۵۶ × ۲۵۶ پیکسل تغییر می دهد.
تصویر را به ۲۲۴ × ۲۲۴ پیکسل از مرکز برش می دهد.
تصویر را به نوع داده Pythorch Tensor تبدیل می کند.
با تنظیم میانگین و انحراف معیار آن روی مقادیر مشخص شده ، تصویر را نرمال می کند.
مرحله ۳: بارگذاری و پیش پردازش تصویر ورودی
در مرحله بعد ، تصویر ورودی را بارگیری کرده و تبدیلات تصویری را که در بالا مشخص کردیم انجام مي دهیم. توجه داشته باشید که ما از ماژول Pillow (PIL) به طور گسترده با TorchVision استفاده خواهیم کرد زیرا این تصویر پیش فرض است که توسط TorchVision پشتیبانی می شود.
Import Pillow#
from PIL import Image
img = Image.open("dog.jpg")

در مرحله بعد ، تصویر را پیش پردازش کرده و دسته ای را برای انتقال از شبکه آماده می کنیم.
img_t = transform(img) batch_t = torch.unsqueeze(img_t, 0)
مرحله ۴: استنباط مدل
سرانجام وقت آن رسیده است که از مدل آموزش دیده استفاده کنیم تا ببینیم مدل، برای تصویر چه پیش بینی انجام می دهد.
ابتدا باید مدل خود را در حالت eval قرار دهیم.
()alexnet.eval
بعد ، استنباط را انجام دهیم.
out = alexnet(batch_t) print(out.shape)
با این بردار خروجی که دارای ۱۰۰۰ عنصر است چه می کنیم؟ ما هنوز کلاس ( یا برچسب ) تصویر را نگرفته ایم. برای این منظور ، ابتدا برچسب ها را از یک فایل متنی که لیستی از تمام ۱۰۰۰ برچسب را دارد ، فراخوانی و ذخیره می کنیم. توجه داشته باشید که شماره خط ، شماره کلاس را مشخص کرده است ، بنابراین بسیار مهم است که ترتیب را تغییر ندهید.
:with open('imagenet_classes.txt') as f
classes = [line.strip() for line in f.readlines()]
از آنجا که AlexNet و ResNet روی یک مجموعه داده ImageNet آموزش دیده اند ، می توانیم از لیست کلاس های یکسان برای هر دو مدل استفاده کنیم.
حال ، باید شاخصی را که دارای حداکثر امتیاز در بردار خروجی است، پیدا کنیم. ما از این شاخص برای پیش بینی استفاده خواهیم کرد.
index = torch.max(out, 1),_ percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100 print(labels[index[0]], percentage[index[0]].item())
این مدل با اطمینان ۴۱٫۵۸٪ پیش بینی می کند که تصویر تعلق به یک Labrador Retriever می باشد.
اما این درصد اطمینان، خیلی کم به نظر می رسد. بیایید ببینیم که این مدل چه کلاس های دیگری را برای این تصویر پیش بینی کرده است.
indices = torch.sort(out, descending=True),_
labels[idx], percentage[idx].item()) for idx in indices[0][:5])]
و در اینجا خروجی ها وجود دارند :
,('Labrador retriever', 41.585166931152344)]
, ('golden retriever', 16.59166145324707)
, ('Saluki, gazelle hound', 16.286880493164062)
, ('whippet', 2.8539133071899414)
[ ('Ibizan hound, Ibizan Podenco', 2.3924720287323)
اگر در این باره اطلاعاتی ندارید ، باید بگویم همه این ها نژادهای سگ هستند. بنابراین مدل موفق شد با اطمینان نسبتاً بالایی پیش بینی کند که تصویر متعلق به سگ است اما در مورد نژاد سگ اطمینان بالایی ندارد.
بیایید همین کار را برای تصویر توت فرنگی و خودرو امتحان کنیم و خروجی هایی را که می گیریم ببینیم.

در اینجا خروجی بدست آمده برای تصویر توت فرنگی فوق وجود دارد. همانطور که می بینیم ، کلاس با بالاترین امتیاز ” توت فرنگی ” با نمره نزدیک به ۹۹٫۹۹٪ بود.
[('strawberry', 99.99365997314453),
('custard apple', 0.001047826954163611),
('banana', 0.0008201944874599576),
('orange', 0.0007371827960014343),
('confectionery, confectionary, candy store', 0.0005758354091085494)]

به همین ترتیب ، برای تصویر خودروی داده شده در بالا ، خروجی به شرح زیر است.
[('cab, hack, taxi, taxicab', 33.30569839477539),
('sports car, sport car', 14.424001693725586),
('racer, race car, racing car', 10.685123443603516),
('beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon',
۷٫۸۴۶۵۳۲۸۲۱۶۵۵۲۷۳),
('passenger car, coach, carriage', 6.985556125640869)]
برای فرآیند کلاسه بندی تصویر با استفاده از مدل های از قبل آموزش دیده ، تمام این ۴ مرحله طی می شود.
چطور همین کار را با ResNet انجام دهیم؟
۴-۱- استفاده از ResNet برای کلاسه بندی تصویر
ما از resnet101 که یک شبکه عصبی کانولوشنی دارای ۱۰۱ لایه است، استفاده خواهیم کرد. resnet101 حدود ۴۴٫۵ میلیون پارامتر دارد که در طی مراحل آموزش تنظیم شده است. این تعداد خیلی زیادی است!
بیایید سریع مراحل مورد نیاز برای استفاده از resnet101 برای کلاسه بندی تصویر را مرور کنیم.
# First, load the model resnet = models.resnet101(pretrained=True) # Second, put the network in eval mode resnet.eval() # Third, carry out model inference out = resnet(batch_t) # Forth, print the top 5 classes predicted by the model _, indices = torch.sort(out, descending=True) percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100 [(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]
و این چیزی است که resnet101 پیش بینی کرده است.
[('Labrador retriever', 48.25556945800781),
('dingo, warrigal, warragal, Canis dingo', 7.900787353515625),
('golden retriever', 6.916920185089111),
('Eskimo dog, husky', 3.6434383392333984),
('bull mastiff', 3.0461232662200928)]
دقیقاً مانند AlexNet ، ResNet نیز با اطمینان بسیار بالایی موفق به پیش بینی سگ شد و با اطمینان ۴۸٫۲۵٪ پیش بینی کرد که این یک سگ Labrador Retriever است!
۲- مقایسه مدل
تاکنون بحث کرده ایم که چگونه می توان از مدل های از قبل آموزش دیده برای کلاسه بندی تصویر استفاده کرد ، اما سوالی که هنوز به آن پاسخ نداده ایم این است که چگونه تصمیم می گیریم کدام مدل را برای یک کار خاص انتخاب کنیم. در این بخش مدل های از قبل آموزش دیده را بر اساس معیارهای زیر مقایسه خواهیم کرد :
- خطای Top-1: اگر کلاس پیش بینی شده توسط یک مدل با بالاترین اطمینان ، با کلاس صحیح یکسان نباشد ، خطای top-1 رخ می دهد.
- خطای Top-5: هنگامی رخ می دهد که کلاس صحیح در میان ۵ کلاس برتر پیش بینی شده توسط یک مدل نباشد (از نظر اطمینان مرتب شده باشد).
- زمان استنباط در CPU : زمان استنباط زمانی است که برای مرحله استنباط مدل صرف می شود.
- زمان استنباط در GPU
- اندازه مدل : در اینجا منظور از اندازه ، فضای فیزیکی اشغال شده توسط فایل .pth از مدل آموزش دیده ارائه شده توسط PyTorch است.
در یک مدل خوب، خطای Top-1 ، خطای Top-5 ، زمان استنباط روی CPU و GPU و اندازه مدل ، مقادیر کمی دارند.
همه آزمایشات روی تصویر ورودی یکسان و چندین بار انجام شده است تا بتوان برای تجزیه و تحلیل، میانگین نتایج را برای یک مدل خاص در نظر گرفت. آزمایشات در Google Colab انجام شده است. حال ، بیایید نگاهی به نتایج به دست آمده بیندازیم.
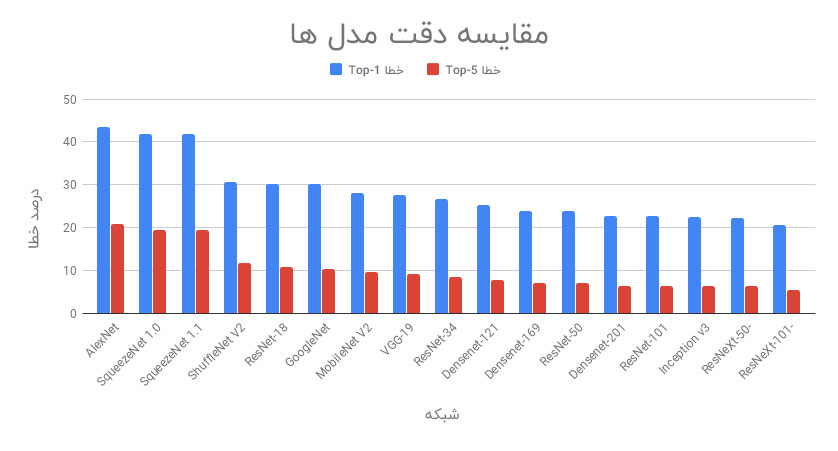
۱-۲- مقایسه دقت مدل ها
اولین معیاری که ما در مورد آن بحث خواهیم کرد ، خطاهای Top-1 و Top-5 هستند. خطای Top-1 به خطاهایی اطلاق می شود که کلاس پیش بینی شده برتر با درستی مبنا متفاوت باشد. از آنجا که این اولین پیش بینی درست، بسیار دشوار است، لذا معیار خطای دیگری نیز وجود دارد که خطای Top-5 نامیده می شود. در این معیار، یک پیش بینی زمانی دچار یک خطای کلاسه بندی می شود که هیچ یک از ۵ کلاس برتر پیش بینی شده صحیح نباشد.
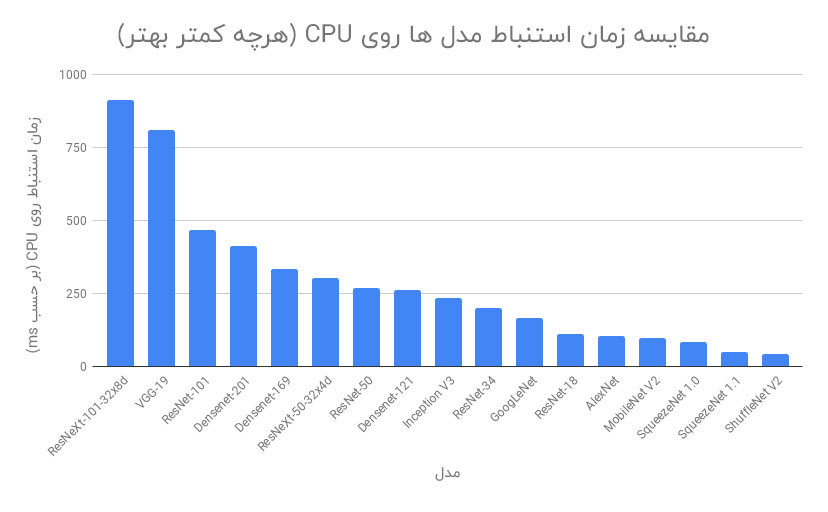
۲-۲- مقایسه زمان استنباط
در مرحله بعدی ، ما مدل ها را بر اساس مدت زمان استنباط مدل مقایسه خواهیم کرد. یک تصویر را چندین بار به هر مدل دادیم و زمان استنباط برای همه تکرارها را متوسط گیری کردیم. برای CPU و سپس برای GPU ، فرآیند مشابهی در Google Colab انجام شد. می توانیم ببینیم که SqueezeNet ، ShuffleNet و ResNet-18 زمان استنباط بسیار کمی دارند ، دقیقاً همان چیزی که ما می خواهیم.
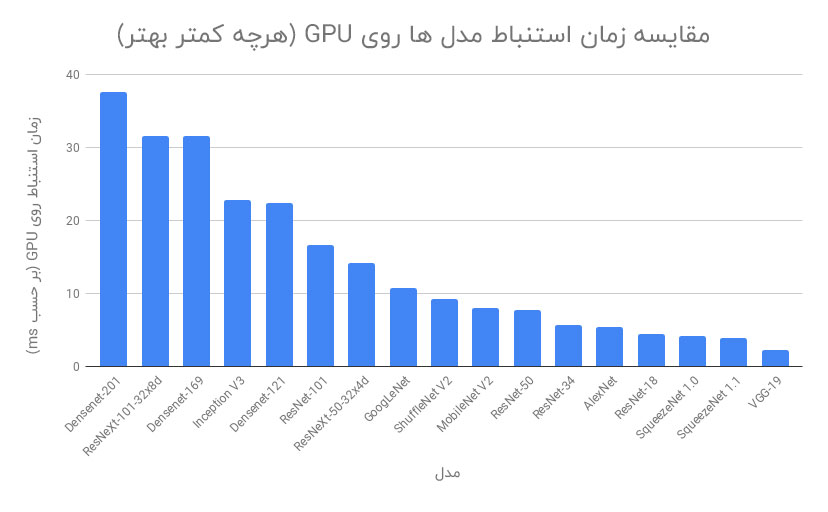
۳-۲- مقایسه اندازه مدل
بسیاری از مواقع که ما از یک مدل یادگیری عمیق در یک دستگاه اندروید یا iOS استفاده می کنیم ، اندازه مدل به یک عامل تعیین کننده تبدیل می شود ، گاهی اوقات حتی از دقت مدل نیز مهم تر است. SqueezeNet دارای حداقل اندازه مدل (۵ مگابایت) و پس از آن ShuffleNet V2 (6 مگابایت) و MobileNet V2 (14 مگابایت) هستند. واضح است که چرا این مدل ها در برنامه های گوشی همراه با استفاده از یادگیری عمیق ترجیح داده می شوند.
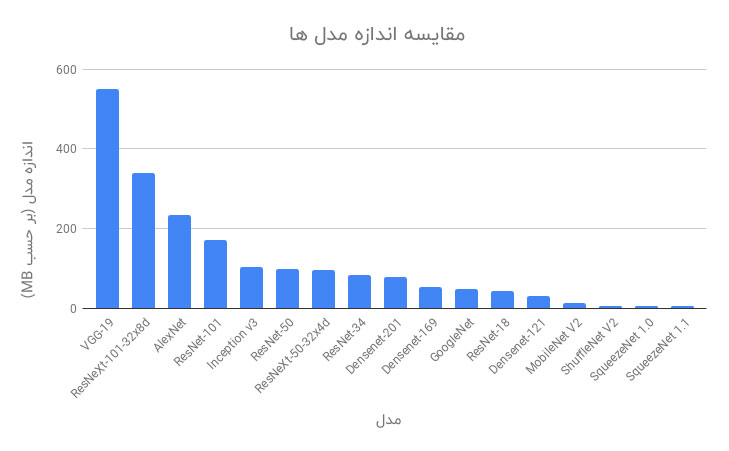
۴-۲- مقایسه کلی
ما در مورد اینکه کدام مدل بر اساس یک معیار خاص عملکرد بهتری دارد بحث کردیم. می توانیم تمام جزئیات مهم را در یک نمودار حبابی خلاصه کنیم تا برای تصمیم گیری در مورد مدل مورد نظر خود به آن مراجعه کنیم.
مختصات x ، خطای Top-1 است (خطای کمتر بهتر است). مختصات y زمان استنباط در GPU بر حسب میلی ثانیه است (کمتر بهتر است). اندازه حباب نشان دهنده اندازه مدل است (خطای کمتر بهتر است).
توجه داشته باشید :
- حباب های کوچکتر از نظر اندازه مدل بهتر هستند.
- حباب های نزدیک به مبدا از نظر دقت و سرعت بهتر هستند.
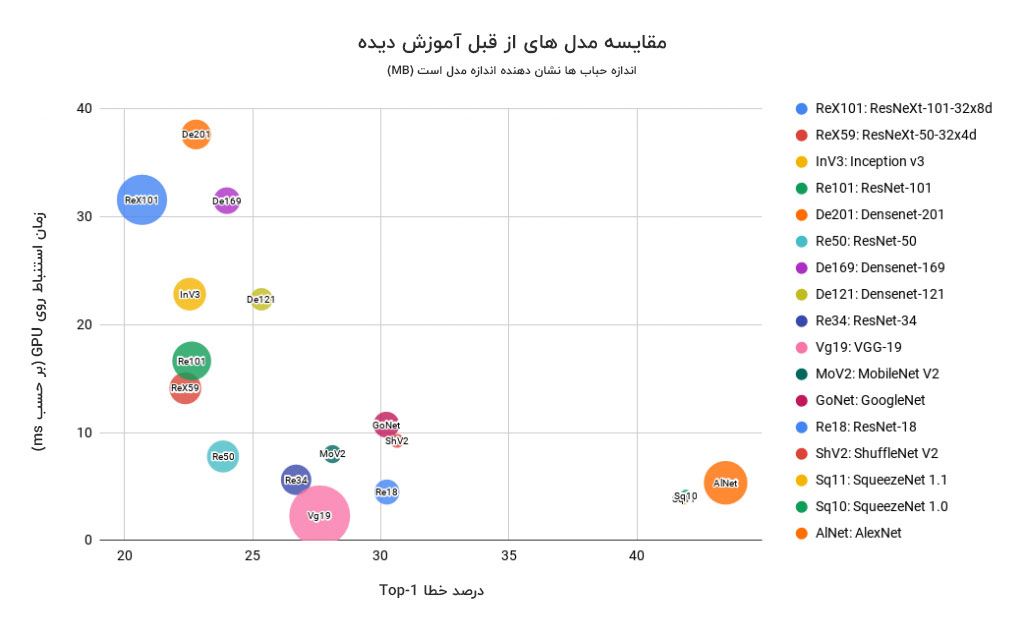
۳- نتیجه نهایی
از نمودار فوق مشخص است که ResNet50 از نظر هر سه پارامتر (اندازه کوچک و نزدیکتر به مبدا) بهترین مدل است.
DenseNets و ResNext101 زمان استنباط زیادی دارند.
AlexNet و SqueezeNet نرخ خطای بسیار بالایی دارند.
خب ، به پایان این سری از آموزش رسیدیم ! در این پست ما چگونگی استفاده از ماژول TorchVision را برای انجام کلاسه بندی تصویر با استفاده از مدل های از پیش آموزش دیده شده ( تنها با یک فرایند ۴ مرحله ای ) بیان کردیم. ما همچنین مقایسه مدل را برای تصمیمگیری در مورد اینکه بسته به الزامات پروژه ، کدام مدل انتخاب شود انجام دادیم. در پست بعدی ، قصد داریم نحوه استفاده از یادگیری انتقالی را برای آموزش مدل روی مجموعه داده های سفارشی با استفاده از PyTorch آموزش دهیم.
دیدگاهتان را بنویسید