
نحوه ایجاد یک Bagging Ensemble از مدل های یادگیری عمیق
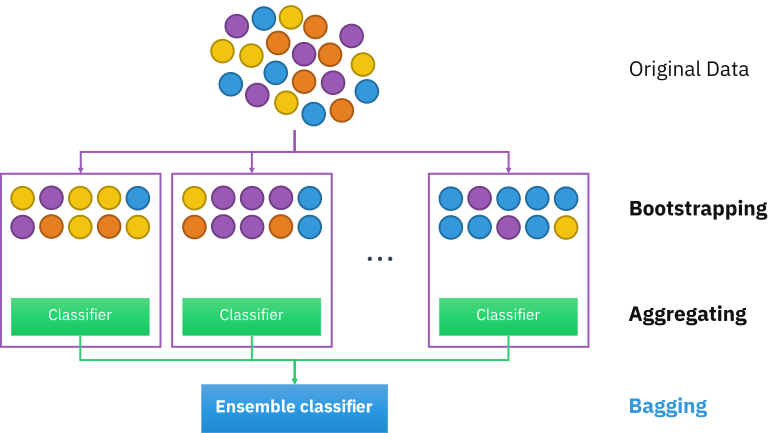
در این مطلب به شرح و توضیح نحوه ایجاد یک Bagging Ensemble خواهیم پرداخت.این روش گونهای از روشهای یادگیری عمیق میباشد.
Ensemble چیست؟
Ensemble یک مفهوم یادگیری ماشین است.که در آن چندین مدل با استفاده از الگوریتم یادگیری یکسان آموزش داده می شوند.
bagging راهی برای کاهش واریانس در پیشبینی است. که با ایجاد دادههای اضافی برای آموزش از مجموعه دادهها صورت میگیرد.و با استفاده از ترکیبات با تکرارها برای تولید چند مجموعه دادههای اصلی است.
Boosting یک تکنیک تکراری است. که وزن یک مشاهده را بر اساس آخرین طبقه بندی تنظیم می کند. اگر مشاهده ای به اشتباه طبقه بندی شده باشد، سعی میکند وزن این مشاهدات را افزایش دهد. به طور کلی Boosting، مدل های پیش بینی قوی ایجاد می کند.
وارد کردن کتابخانهها
from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from pandas import DataFrame
sklearn.datasets.make_blobs
sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=- 10.0, 10.0, shuffle=True, random_state=None, return_centers=False): Generate isotropic Gaussian blobs for clustering.
مولفهها
n_samples: int or array-like, default=100
اگر مقدار آن عدد باشد، تعداد کل نقاط به طور مساوی بین خوشهها تقسیم می شود. و اگر آرایه مانند باشد، هر عنصر دنباله تعداد نمونه در هر خوشه را نشان میدهد.
n_features: int, default=2
تعداد ویژگی ها برای هر نمونه را نشان میدهد.
centers: int or ndarray of shape (n_centers, n_features), default=None
تعداد مراکزی که باید تولید شوند یا مکانهای مرکز ثابت را نشان میدهد. اگر n_samples یک عدد صحیح و مراکز None باشد، 3 مرکز ایجاد می شود. اگر n_samples آرایه مانند باشد، مراکز باید یا None یا آرایه ای به طول برابر با طول n_samples باشند.
cluster_std: float or array-like of float, default=1.0
انحراف معیار خوشه هارا بیان میکند.
center_box: tuple of float (min, max), default=(-10.0, 10.0)
این مولفه زمانی استفاده میشود که برای هر مرکز خوشه مراکز به طور تصادفی تولید می شوند.
shuffle: bool, default=True
نمونه ها را با بُر میزند.
random_state: int, Random State instance or None, default=None
اعداد تصادفی را برای مجموعه داده ایجاد میکند.
return_centers: bool, default=False
اگر مقدار آن True باشد، مراکز هر خوشه را برمیگرداند.
Returns (خروجی)
X: ndarray of shape (n_samples, n_features)
این مولفه نمونه های تولید شده را نشان میدهد.
y: ndarray of shape (n_samples,)
برچسب های عدد صحیح برای عضویت در خوشه هر نمونه.
centers: ndarray of shape (n_centers, n_features)
مراکز هر خوشه فقط در صورتی برگردانده می شود که return_centers=True باشد.
مجموعه داده طبقه بندی دو بعدی را ایجاد کنید
X, y = make_blobs(n_samples=1000, centers=5, n_features=2, cluster_std=2, random_state=2)
print(X)

print(y)

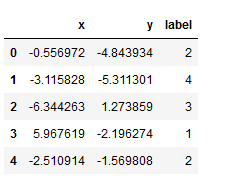
تبدیل X و y را به دیتافریم پاندا
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))df.head()
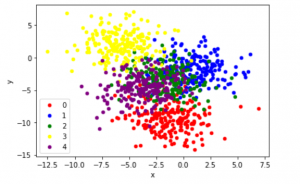
نمودارهای پراکندگی، نقطههای رنگی با مقدار کلاس
colors = {0:'red', 1:'blue', 2:'green', 3:'yellow', 4:'purple'}fig, ax = plt.subplots()
grouped = df.groupby('label')for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
plt.show()
from tensorflow.keras.utils import to_categoricaly = to_categorical(y) print(y)

تقسیم دادهها به ترین و تست
n_train = int(0.9 * X.shape[0]) trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:]
تعریف مدل
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense
Model instance
model = Sequential() model.add(Dense(50, input_dim=2, activation='relu')) model.add(Dense(5, activation='softmax')) model
Output: <tensorflow.python.keras.engine.sequential.Sequential at 0x7f0ac03e0150>
کامپایل کردن مدل
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
آموزش مدل
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=50, verbose=0)history
Output: <tensorflow.python.keras.callbacks.History at 0x7f0ac247e590>
ارزیابی مدل
train_loss, train_acc = model.evaluate(trainX, trainy, verbose=0)
test_loss, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
Output: Train: 0.749, Test: 0.750
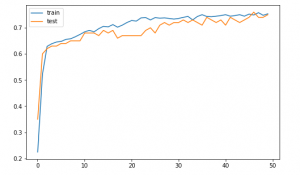
رسم منحنی های یادگیری دقت مدل
ترسیم خطی منحنی های یادگیری دقت مدل در مجموعه داده های آموزش و آزمون در هر دوره آموزشی
plt.figure(figsize=(8, 5))plt.plot(history.history['accuracy'], label='train') plt.plot(history.history['val_accuracy'], label='test') plt.legend() plt.show()
نحوه ایجاد یک Bagging Ensemble
bagging چیست؟
Bootstrap Aggregating که به آن bagging نیز میگویند، یک متاالگوریتم یادگیری ماشین است که برای بهبود پایداری و دقت الگوریتمهای یادگیری ماشینی مورد استفاده در طبقهبندی آماری و رگرسیون طراحی شده است.
در bagging، یک نمونه تصادفی از داده ها در یک مجموعه آموزشی با جایگزینی انتخاب می شود. به این معنی که نقاط داده منحصربه فرد را می توان بیش از یک بار انتخاب کرد. پس از تولید چندین نمونه داده، این مدلهای ضعیف به طور مستقل آموزش داده میشوند و بسته به نوع کار، به عنوان مثال، رگرسیون یا طبقهبندی، میانگین یا اکثریت آن پیشبینیها تخمین دقیقتری به دست میدهد.
همچنین واریانس را کاهش می دهد و به جلوگیری از برازش بیش از حد کمک می کند. اگرچه معمولاً برای روش های درخت تصمیم اعمال می شود، اما می توان آن را با هر نوع روشی استفاده کرد. bagging یک مورد خاص از رویکرد میانگین گیری مدل است.
Bootstrapping هر آزمون یا معیاری است که از نمونهگیری تصادفی با جایگزینی استفاده میکند و در دسته وسیعتری از روشهای نمونهگیری مجدد قرار میگیرد. Bootstrapping معیارهای دقت (بایاس، واریانس، فواصل اطمینان، خطای پیشبینی و غیره) را به تخمینهای نمونه اختصاص میدهد. این تکنیک امکان تخمین توزیع نمونهگیری تقریباً هر آماری را با استفاده از روشهای نمونهگیری تصادفی فراهم میکند.
در ادامه مطلب به نحوه ایجاد یک Bagging Ensemble با ذکر مثال خواهیم پرداخت.
اضافه کردن مجموعه داده
dataX, datay = make_blobs(n_samples=55000, centers=5, n_features=2, cluster_std=2, random_state=2) X, newX = dataX[:5000, :], dataX[5000:, :] y, newy = datay[:5000], datay[5000:
dataX.shape, datay.shape
Output: ((55000, 2), (55000,))
X.shape, newX.shape
Output:((5000, 2), (50000, 2))
y.shape, newy.shape
Output:((5000, 2), (50000, ))
اکنون 5000 نمونه برای آموزش مدل خود و تخمین عملکرد کلی آن داریم. ما همچنین 30000 نمونه داریم که میتوانیم از آنها برای تقریب بهتر عملکرد کلی واقعی یک مدل یا یک مجموعه استفاده کنیم.
ساخت تابع
این تابع متناسب با مدل روی مجموعه داده آموزشی است. این مدل متناسب را بر روی دادههای تست باز میگرداند.
import numpy as np from sklearn.metrics import accuracy_score
تابع ارزیابی مدل
def evaluateModel(trainX, trainy, testX, testy):
#Convert trainy and testy into categorical
trainy_enc = to_categorical(trainy)
testy_enc = to_categorical(testy)
# Create a model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu'))
model.add(Dense(5, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy_enc, epochs=50, verbose=0)
# evaluate the model
test_loss, test_acc = model.evaluate(testX, testy_enc, verbose=0)
# return the model and accuracy of test data
return model, test_acc
pass
یک تابع برای پیشبینی گروهی برای طبقهبندی چند کلاسه ایجاد کنید
def ensemblePredictions(members, testX):
# make predictions
yhats = [model.predict(testX) for model in members]
yhats = np.array(yhats)
# sum across ensemble members
summed = np.sum(yhats, axis=0)
# argmax across classes
result = np.argmax(summed, axis=1)
# return the result
return result
pass
یک تابع برای ارزیابی تعداد خاصی از مدل در یک گروه ایجاد کنید
def evaluateNMembers(members, n_members, testX, testy):
# select a subset of members
subset = members[:n_members]
# make prediction
yhat = ensemblePredictions(subset, testX)
# calculate accuracy
return accuracy_score(testy, yhat)
pass
با استفاده از نمونهبرداری مجدد، دادهها را به ترین و تست تقسیم کنید
from sklearn.utils import resample
sklearn.utils.resample(*arrays, replace=True, n_samples=None, random_state=None, stratify=None):
آرایهها یا ماتریسهای پراکنده را به روشی ثابت نمونهگیری مجدد کنید.
استراتژی پیشفرض یک مرحله از فرآیند راهاندازی را اجرا میکند.
n_splits = 10scores, members = list(), list()for m in range(n_splits):
# select indexes
ix = [i for i in range(len(X))]
train_ix = resample(ix, replace=True, n_samples=4500)
test_ix = [x for x in ix if x not in train_ix]
# select data
trainX, trainy = X[train_ix], y[train_ix]
testX, testy = X[test_ix], y[test_ix]
# evaluate model
model, test_acc = evaluateModel(trainX, trainy, testX, testy)
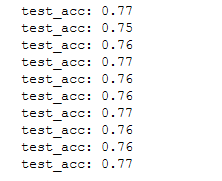
print(f'test_acc: {test_acc:.2f}')
scores.append(test_acc)
members.append(model)
دقت تخمینی
print(f'Estimated Accuracy {np.mean(scores): .2f} ({np.std(scores): .3f})')
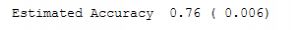
ارزیابی تعداد مختلف گروه
single_scores, ensemble_scores = list(), list()for i in range(1, n_splits+1):
ensemble_score = evaluateNMembers(members, i, newX, newy)
newy_enc = to_categorical(newy)
_, single_score = members[i-1].evaluate(newX, newy_enc, verbose=0)
print(f'{i}: single={single_score: .2f}, ensemble={ensemble_score: .2f}')
ensemble_scores.append(ensemble_score)
single_scores.append(single_score)
pass
print(ensemble_scores) print(single_scores)
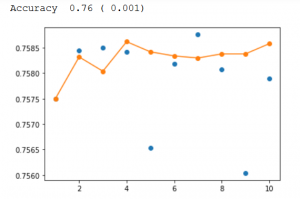
رسم امتیاز در مقابل تعداد اعضای گروه
print(f'Accuracy {np.mean(single_scores): .2f} ({np.std(single_scores): .3f})')x_axis = [i for i in range(1, n_splits+1)]
plt.plot(x_axis, single_scores, marker='o', linestyle='None')
plt.plot(x_axis, ensemble_scores, marker='o')
plt.show()
مطالب زیر را حتما مطالعه کنید

درک منحنی AUC – ROC

تشخیص جنسیت و سن افراد با کتابخانه OpenCV
ذخیره و بارگذاری مدل در پایتورچ
آموزش هرس در کتابخانه های Pytorch و Tensorflow

شبکه خودرمزنگار متغیر (variational autoencoder) چیست؟

دیدگاهتان را بنویسید