
احراز هویت اسکناس با استفاده از مدل ترتیبی کراس kears

شبکه های عصبی مصنوعی را می توان برای حل طیف وسیعی از مسائل استفاده کرد. کزاس یک کتابخانه منبع باز است که می تواند برای پیاده سازی شبکه های عصبی مصنوعی استفاده شود. کراس دارای تمام ویژگی های اصلی مورد نیاز برای ساخت و آموزش شبکه های عصبی مصنوعی است. ما از مدل ترتیبی کراس برای احراز هویت اسکناس ها استفاده خواهیم کرد. مجموعه داده از UCI Machine Learning گرفته شده است. مجموعه داده دارای اطلاعات استخراج شده از اسکناس های واقعی و جعلی است. ویژگی های تصاویر با استفاده از ابزار Wavelet Transform استخراج شده اند.
داده ها شامل ویژگی های زیر است:
1. واریانس تصویر تبدیل شده موجک (پیوسته)
2. چولگی تصویر تبدیل شده موجک (پیوسته)
3. کشیدگی تصویر تبدیل شده موجک (پیوسته)
4. آنتروپی تصویر (پیوسته)
5. کلاس (عدد صحیح)
بنابراین، اساساً 4 ویژگی دارای داده های عددی هستند و یک ویژگی کلاسی است که قرار است آموزش داده شود/پیش بینی شود.
داده ها از نمونه اسکناس های واقعی و جعلی استخراج شده است. مشکلی که وجود دارد طبقه بندی اسکناس به عنوان اصل یا جعلی است. تمایز یک اسکناس اصل از یک اسکناس جعلی بسیار مهم است. تشخیص دستی اسکناس های جعلی کار بسیار دشواری است. یادگیری عمیق می تواند در این مورد کمک کند. مشکل تمایز اسکناس واقعی از اسکناس جعلی با استفاده از شبکه های عصبی مصنوعی قابل حل است.
کراس (Keras) چیست؟
کراس یک چارچوب یادگیری عمیق منبع باز است که می تواند در پایتون استفاده شود. این پلتفرم توسط فرانسوا شولت، مهندس گوگل نوشته شده است. کراس از اجرای سریع و ساده شبکه های عصبی عمیق پشتیبانی می کند. کراس از استفاده از شبکه های کانولوشنی و همچنین شبکه های بازگشتی و همچنین ترکیبات آنها پشتیبانی می کند. بسیاری از شرکت های بزرگ مانند گوگل، مایکروسافت، نتفلیکس، هواوی و اوبر از کراس استفاده می کنند و آنها نیز در توسعه کراس مشارکت دارند.
استفاده از کراس بسیار آسان و ساده است زیرا بر تجربه کاربر تمرکز دارد. کراس در صنعت پذیرفته شده است و از نمونه سازی ساده و سریع پشتیبانی می کند. برای اجرا لزوماً به GPU نیاز ندارد و می تواند روی CPU نیز اجرا شود. شروع کار با کراس بسیار آسان است و مبتدیان می توانند آن را به راحتی یاد بگیرند. ساخت و اجرای مدل ها با کراس آسان است.
API کلی کراس را می توان به 3 بخش تقسیم کرد:
- Model
- Layer
- Core Modules
مدلهای کراس نشاندهنده شبکههای عصبی مصنوعی هستند. هر مدل متوالی کراس ترکیبی از لایههای کراس است. لایه های ANN مانند لایه ورودی، لایه خروجی، لایه پیچیدگی و غیره نشان داده می شوند.
مدلهای کراس عمدتاً مدلهای متوالی هستند. یک ترکیب خطی از لایههای کراس یک مدل متوالی را تشکیل میدهد. اجرای آن ساده و آسان است.
شروع کار با کد برای احراز هویت اسکناس:
در اولین گام کتابخانه های لازم را فراخوانی می کنیم.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline
اکنون داده ها را می خوانیم. تمام کدها در یک نوت بوک Kaggle به اشتراک گذاشته خواهند شد.
banknotes= pd.read_csv('/kaggle/input/banknote-authentication-uci/BankNoteAuthentication.csv' )
اکنون اجازه دهید نگاهی به داده ها بیندازیم.
banknotes.head()
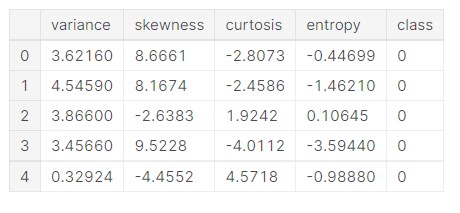
داده ها همانطور که قبلاً بحث کردیم، 4 ویژگی داده پیوسته و یک متغیر کلاس وجود دارد.
- واریانس – واریانس مقداری است که در آن چیزی تغییر می کند یا با چیز دیگری متفاوت است
- چولگی – چولگی مقداری است که در آن چیزی تغییر می کند یا با چیز دیگری متفاوت است
- کشیدگی – کشیدگی اشاره به نوک تیز بودن یک قله در منحنی توزیع دارد.
- آنتروپی – آنتروپی معیار بی نظمی یا عدم قطعیت است.
اکنون، اجازه دهید برخی از معیارهای توزیع داده را برای درک داده ها پیاده سازی کنیم.
# Use pairplot and set the hue to be our class
sns.pairplot(banknotes,hue='class')
# Describe the data
print('Dataset stats: n', banknotes.describe())
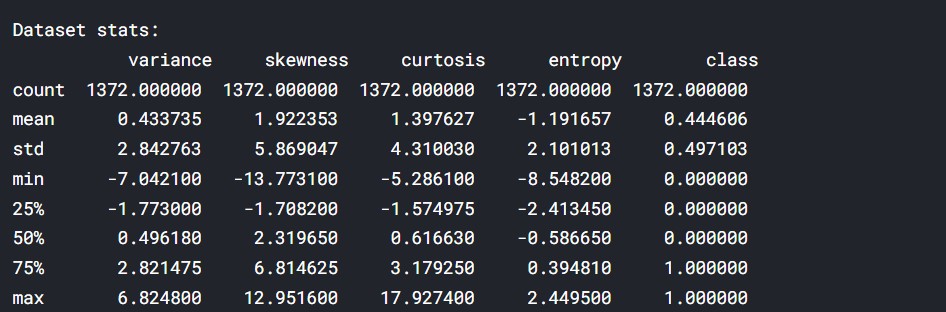
در اینجا میتوان میانگین و توزیع دادهها را تحلیل کرد. میانگین کلاس نزدیک به 0.5 است که مشخص می کند داده ها متعادل هستند.
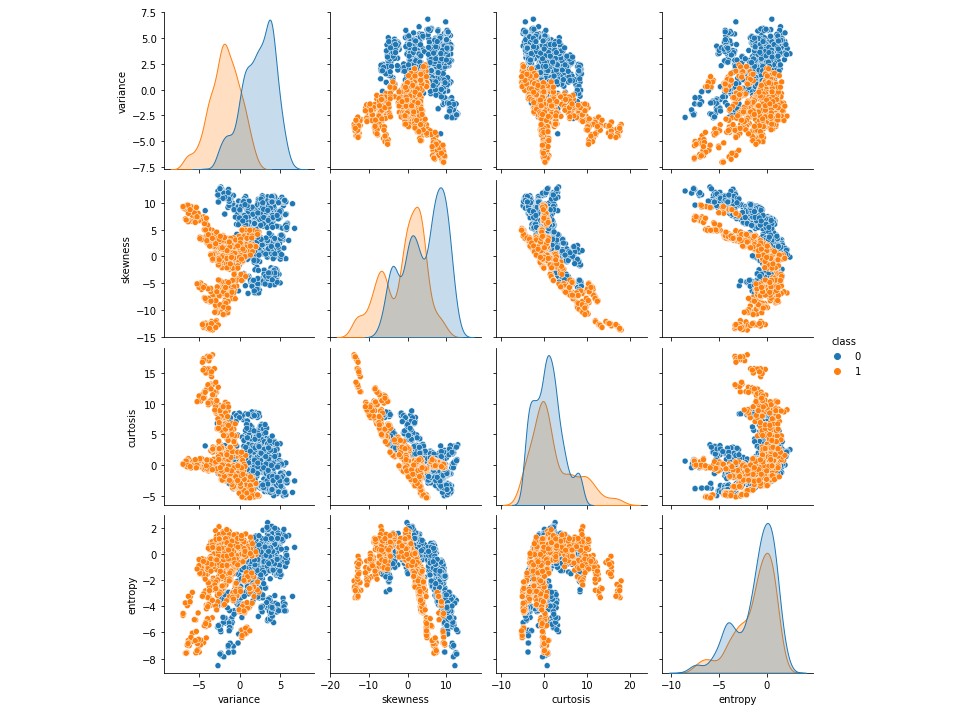
نمودارهای پراکندگی نشان می دهد که طبقات متمایز و مجزا هستند.
یک نقشه همبستگی نشان می دهد که کدام ویژگی ها به یکدیگر مرتبط هستند.
sns.heatmap(banknotes.corr(),annot=True,cmap='mako',linewidths=0.2) fig=plt.gcf() fig.set_size_inches(12,6) plt.show()
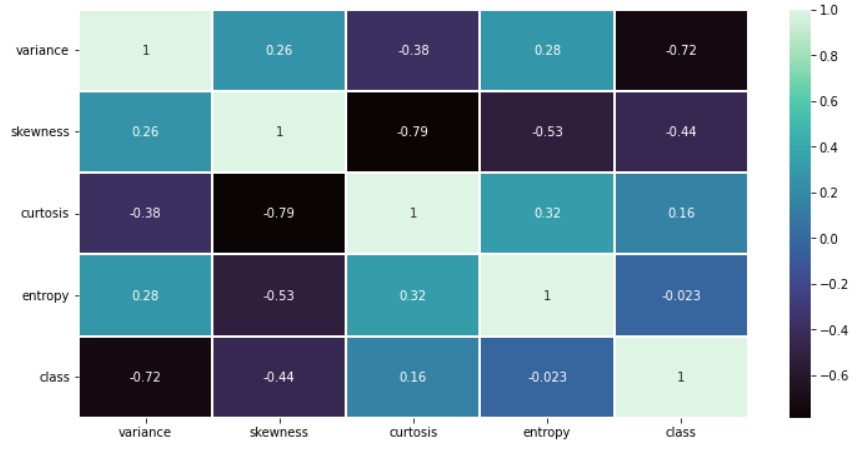 بین کشیدگی و چولگی همبستگی منفی بالایی وجود دارد. رابطه متوسط بالا بین کشیدگی و آنتروپی وجود دارد. همبستگی ها در همه جا وجود دارد، اما این نشان می دهد که داده ها برای آموزش یک شبکه عصبی مناسب هستند.
بین کشیدگی و چولگی همبستگی منفی بالایی وجود دارد. رابطه متوسط بالا بین کشیدگی و آنتروپی وجود دارد. همبستگی ها در همه جا وجود دارد، اما این نشان می دهد که داده ها برای آموزش یک شبکه عصبی مناسب هستند.
نمودارهای توزیع داده برای احراز هویت اسکناس:
اجازه دهید توزیع داده ها را برای هر یک از متغیرها رسم کنیم.
sns.displot(banknotes["variance"], height= 5, aspect=1.8)
plt.xlabel("Variance")
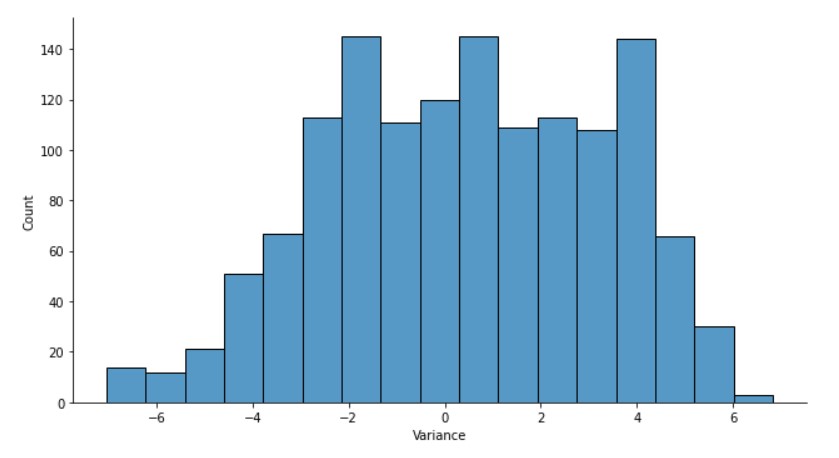 به نظر می رسد که واریانس از توزیع تا حدودی نرمال پیروی می کند.
به نظر می رسد که واریانس از توزیع تا حدودی نرمال پیروی می کند.
sns.displot(banknotes["skewness"], height= 5, aspect=1.8)
plt.xlabel("Skewness")
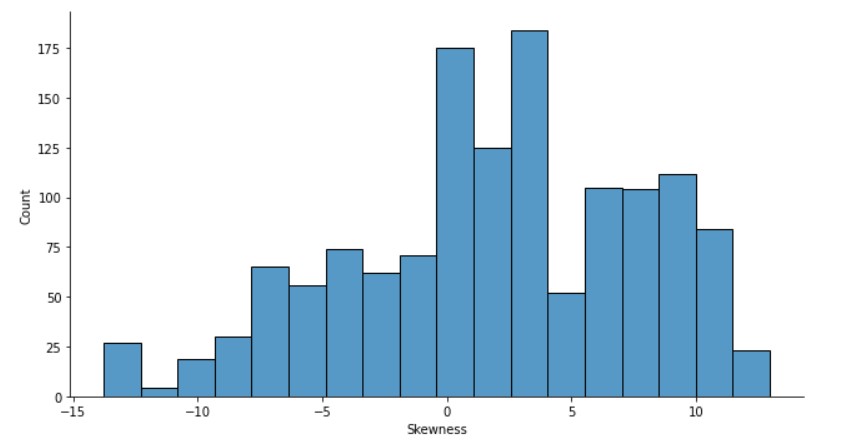 چولگی بیشتر به جنبه مثبت تقسیم می شود.
چولگی بیشتر به جنبه مثبت تقسیم می شود.
sns.displot(banknotes["curtosis"], height= 5, aspect=1.8)
plt.xlabel("Curtosis")
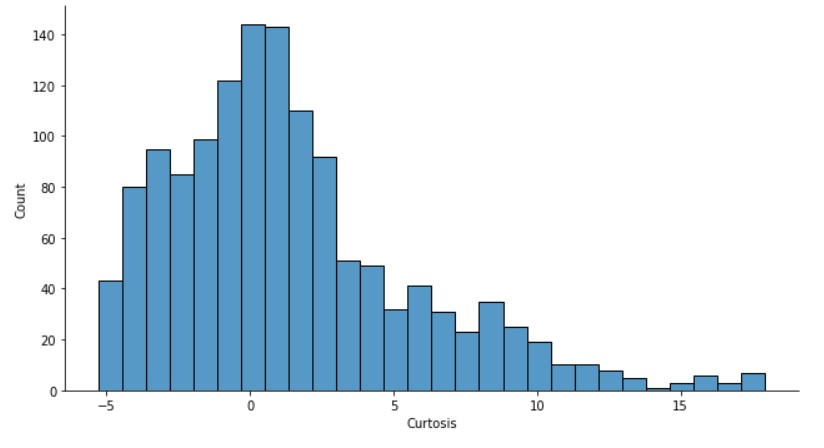 کورتوز بیشتر به سمت منفی منحرف می شود و حداکثر نقاط داده نزدیک به صفر است.
کورتوز بیشتر به سمت منفی منحرف می شود و حداکثر نقاط داده نزدیک به صفر است.
sns.displot(banknotes["entropy"], height= 5, aspect=1.8)
plt.xlabel("Entropy")
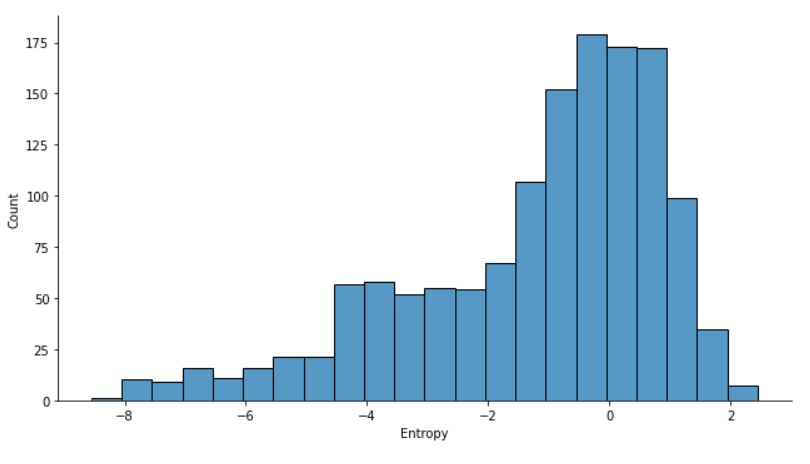 به نظر می رسد توزیع داده های آنتروپی برعکس Kurtosis باشد.
به نظر می رسد توزیع داده های آنتروپی برعکس Kurtosis باشد.
بیایید توزیع کلاس را ببینیم.
sns.countplot(data= banknotes, y="class")
plt.xlabel("Class")
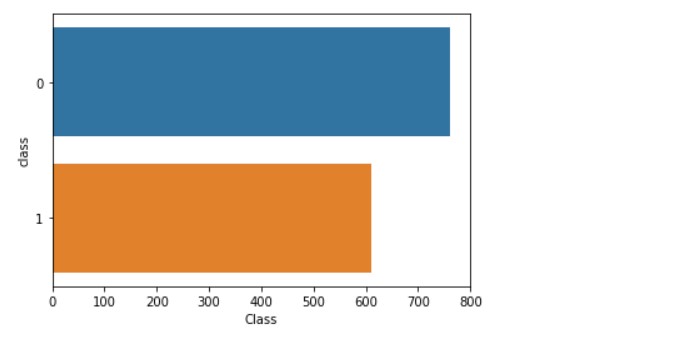
بنابراین، می توانیم تأیید کنیم که کلاس ها متعادل هستند.
ساخت مدل برای احراز هویت اسکناس:
حال اجازه دهید به ساخت مدل ادامه دهیم.
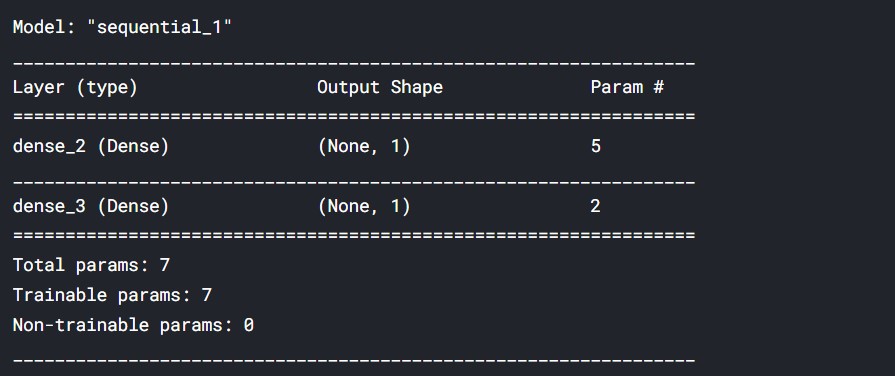
# Import the sequential model and dense layer from keras.models import Sequential from keras.layers import Dense from keras.callbacks import EarlyStopping # Create a sequential model model = Sequential() # Add a dense layer model.add(Dense(1, input_shape=(4,), activation='sigmoid')) model.add(Dense(1, input_shape=(3,), activation='sigmoid')) # Compile your model model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
حال اجازه دهید نگاهی به summary مدل بیندازیم.
# Display a summary of your model model.summary()
اجازه دهید متغیرهای ورودی و خروجی را در نظر بگیریم.
X=banknotes[['variance','skewness', 'curtosis','entropy']] y=banknotes[["class"]]
اکنون داده ها را به مجموعه های تست و آموزش تقسیم می کنیم.
#splitting the data into test and train sets from sklearn.model_selection import train_test_split train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.35, random_state = 7)
اکنون مدل را آموزش می دهیم و آن را ارزیابی می کنیم.
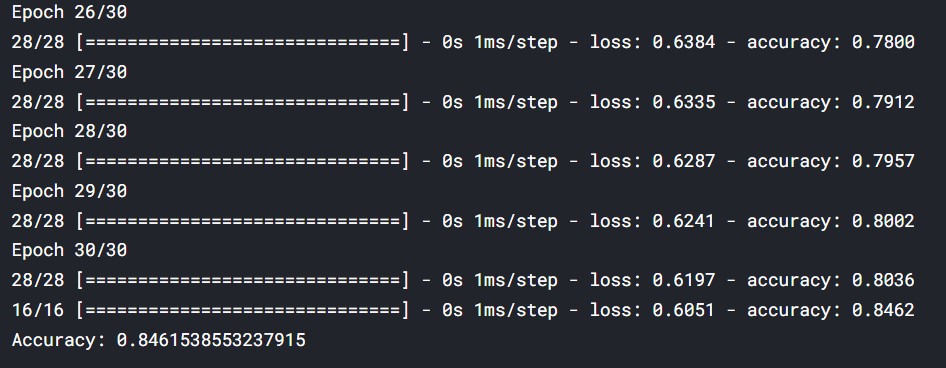
# Train your model
model.fit(train_X, train_y, epochs=30)
# Evaluate your model accuracy on the test set
accuracy = model.evaluate(test_X, test_y)[1]
# Print accuracy
print('Accuracy:',accuracy)
early stopping callback یک ویژگی مفید است. این به ما این امکان را می دهد که اگر بعد از تعداد معینی از دوره ها دیگر بهبود نیافت، آموزش مدل را متوقف کنیم. برای استفاده از آن، باید callback را در یک لیست به پارامتر callback مدل در متد ()fit ارسال کنیم.
monitor_val_acc = EarlyStopping(monitor='accuracy', mode="max",
patience=6)
# Train your model using the early stopping callback
model.fit(train_X, train_y,
epochs=100, validation_data=(test_X, test_y),
callbacks=[monitor_val_acc])
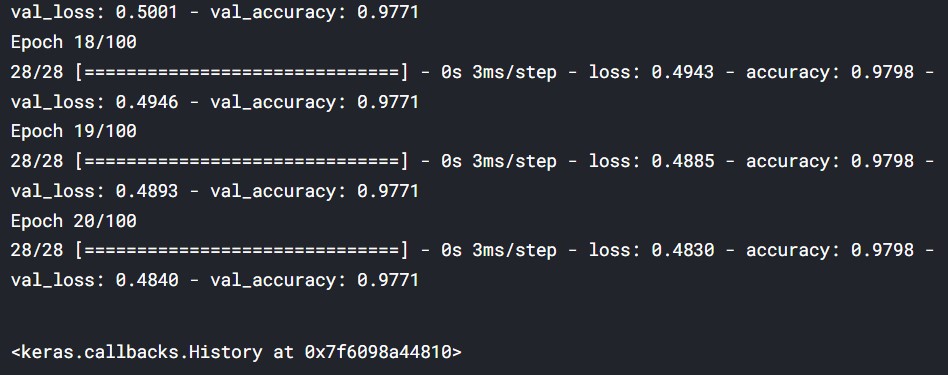 ما مدل را تا 100 دوره داده بودیم، اما آموزش در 20 دوره متوقف شد.
ما مدل را تا 100 دوره داده بودیم، اما آموزش در 20 دوره متوقف شد.
اجازه دهید برای آخرین بار دوباره آن را ارزیابی کنیم.
print(model.evaluate(test_X, test_y)[1])

میتوانیم ببینیم که استفاده از شبکههای عصبی برای انجام پیشبینیها نتایج بسیار خوبی داشت.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید