
تجزیه و تحلیل داده با پایتون

در این مطلب به بیان 10 نوع عملیات برای تجزیه و تحلیل داده با پایتون میپردازیم.این عملیات با کمک پایتون و pandas صورت میگیرد. که بخشی از نیازهای دانشمندان داده را برآورده میکند.
1-خواندن مجموعه داده برای تجزیه و تحلیل داده با پایتون:
داده ها جزئی از مراحل تجزیه و تحلیل هستند. دانستن نحوه خواندن داده ها از فرمت های مختلف فایل مانند: csv، excel، text و غیره یکی از اولین مراحلی است که باید به عنوان یک دانشمند داده در آن مهارت داشته باشید. در زیر مثالی از نحوه خواندن یک فایل CSV حاوی دادههای Covid-19 با استفاده از pandas آورده شده است.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
countries_df.head()
در زیر خروجی ()country_df.head است که با استفاده از آن می توانیم 5 ردیف اول یک دیتافریم را ببینیم:
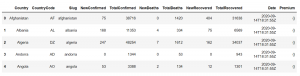
2- خلاصه آماری برای تجزیه و تحلیل داده با پایتون:
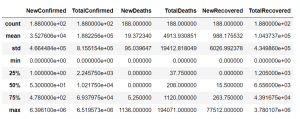
هنگامی که مجموعه داده را خواندید، گام بعدی این است که داده ها را با مشاهده خلاصه داده ها مانند تعداد دادهها، میانگین، انحراف استاندارد (std)، چارک و غیره از ستون های عددی مانند فرکانس، NewConfirmed، TotalConfirmed را درک کنید.
با استفاده از تابع زیر میتوانیم خلاصهای از متغیرهای پیوسته مجموعه داده را مطابق شکل بدست آوریم:
#get summary of continuous variables countries_df.describe()
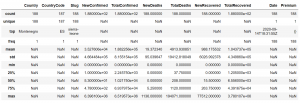
در تابع فوق، میتوانیم آرگومان “include = “all” را برای به دست آوردن خلاصهای از متغیرهای پیوسته و طبقهای تنظیم کنیم.
#get summary of continuous and categorical variables countries_df.describe(include = 'all')
3- انتخاب داده و فیلتر کردن برای تجزیه و تحلیل داده با پایتون:
تمام سطرها و ستون های یک مجموعه داده برای تجزیه و تحلیل مورد نیاز نیستند. شما باید ستون های مورد علاقه را انتخاب کنید و برخی از ردیف ها را بر اساس سوالی که می خواهید به آن پاسخ دهید فیلتر کنید.
برای مثال، میتوانیم ستونهای Country و NewConfirmed را با استفاده از کد زیر انتخاب کنیم:
# selecting Country and NewConfirmed columns countries_df[['Country','NewConfirmed']]

ما همچنین می توانیم داده های ایالات متحده آمریکا را به عنوان کشور فیلتر کنیم. با استفاده از loc، میتوانیم یک ستون را بر اساس مقداری مانند شکل زیر فیلتر کنیم:
# filtering USA using country column countries_df.loc[countries_df['Country'] == 'United States of America']
![]()
4- تجمیع:
یافتن خلاصه های عددی مانند تعداد، مجموع، میانگین و غیره در گروه بندی متغیرهای مختلف، تجمیع داده ها است. این یکی از متداول ترین وظایف یک دانشمند داده است.
ما میتوانیم مجموع موارد NewConfimed را در سراسر کشورها با استفاده از تجمیع پیدا کنیم. تجمیع با استفاده از توابع groupby و agg انجام میشود. در تابع groupby، سطحی را که میخواهیم تجمیع را انجام دهیم (ستون کشور) و در تابع aggregation نام ستون (NewConfirmed) و عملیات ریاضی (جمع) را که میخواهیم روی ستون انجام دهیم، ارائه میکنیم.
# total NewConfirmed cases across countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})

5-ترکیب:
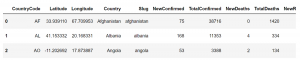
ترکیب 2 مجموعه داده برای ایجاد یک مجموعه داده با استفاده از عملیات Join انجام می شود. در بسیاری از مواقع، اطلاعات متفاوتی در مجموعه دادههای مختلف وجود دارد، برای مثال، یک مجموعه داده میتواند شامل تعداد موارد Covid-19 در کشورهای مختلف باشد و مجموعه داده دیگری میتواند حاوی اطلاعات طول و عرض جغرافیایی کشورهای مختلف باشد. حال، اگر نیاز به ترکیب این 2 اطلاعات داشته باشیم، میتوانیم عملیات Join را مطابق شکل زیر انجام دهیم:
#reading countires lat and lon data
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df
6- توابع داخلی:
دانستن توابع داخلی ریاضی مانند ()min()، max()، mean()، sum و غیره برای انجام تحلیل های مختلف بسیار مفید است. ما میتوانیم این توابع را به سادگی با فراخوانی آنها مستقیماً روی یک دیتافریم اعمال کنیم. این توابع را میتوان به صورت مستقل بر روی یک ستون یا در تابع تجمیع مطابق شکل زیر استفاده کرد:
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
# NewConfirmed
#Country
#Afghanistan 75
#Albania 168
#Algeria 247
#Andorra 0
#Angola 53
7- توابع تعریف شده توسط کاربر:
توابعی که خودمان مینویسیم توابع تعریف شده توسط کاربر هستند. ما میتوانیم کدهای درون این توابع را هر زمان که لازم باشد با فراخوانی آن تابع اجرا کنیم. به عنوان مثال، ما میتوانیم تابعی برای اضافه کردن 2 عدد مانند شکل زیر ایجاد کنیم:
# User defined function is created using 'def' keyword, followed by function definition - 'addition()'
# and 2 arguments num1 and num2
def addition(num1, num2):
return num1+num2
# calling the function using function name and providing the arguments
print(addition(1,2))
#output : 3
8- pivot
Pivoting تبدیل مقادیر منحصربهفرد درون ردیفهای یک ستون به چندین ستون جدید است. این تکنیک دستکاری داده های پیشرفته است. با استفاده از تابع ()pivot_table در مجموعه داده Covid-19، می توانیم نام کشورها را به ستون های جدید جداگانه تبدیل کنیم:
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df, columns = 'Country', values = 'NewConfirmed') pivot_df
![]()
9- تکرار بر روی دیتافریم:
بسیاری از اوقات لازم است که از طریق فهرست و ردیف های یک قاب داده تکرار شود. میتوانیم با استفاده از تابع iterrows از طریق dataframe تکرار کنیم:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......
10- عملیات بر روی رشته:
اغلب اوقات ما با ستون های رشته ای در مجموعه داده خود سر و کار داریم، در چنین مواردی دانستن برخی از عملیات های رشته ای اساسی مانند نحوه تبدیل یک رشته به حروف بزرگ، کوچک و چگونگی پیدا کردن طول یک رشته در یک ستون مهم است.
# country column to upper case countries_df['Country_upper'] = countries_df['Country'].str.upper() # country column to lower case countries_df['CountryCode_lower']=countries_df['CountryCode'].str.lower() # finding length of characters in the country column countries_df['len'] = countries_df['Country'].str.len() countries_df.head()
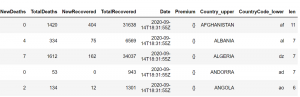
دانستن نحوه انجام این 10 عملیات تقریباً 70 درصد از نیازهای شما را برآورده می کند.که با کمک این عملیات قادر به تجزیه و تحلیل داده با پایتون میشوید.
مطالب زیر را حتما مطالعه کنید

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

ذخیره و بارگذاری مدل در پایتون

محل بررسی مدل های شبکه عصبی
شبکه خودرمزنگار متغیر (variational autoencoder) چیست؟

آموزش Pytorch (قسمت سوم)

دیدگاهتان را بنویسید