
ساخت دیپفیک تنها با یک منبع ویدئو

دیپ فیک چیست؟
دیپفیکها ویدیوهای مصنوعی ساختهشده توسط هوش مصنوعی از هر شخص یا فرد مشهوری هستند که خود را جعل هویت میکنند. فرآیند ایجاد دیپفیک از نظر فنی پیچیده است. و به طور کلی به حجم وسیعی از داده نیاز دارد که سپس برای آموزش و تولید ویدئوی مصنوعی به یک شبکه عصبی داده می شود.
مزایای دیپفیکها:
دیپفیک می تواند به عنوان نوعی هنر برای بازگرداندن افراد از گذشته به زندگی استفاده شود. به عنوان مثال، نقاشی مونالیزا را می توان برای ایجاد یک تصویر مصنوعی از صحبت کردن مونالیزا به عنوان نوعی هنر استفاده کرد.
از فناوری دیپفیک می توان برای ایجاد آواتارهای هوش مصنوعی در فیلم های آموزشی استفاده کرد. استارتآپهایی مانند Synthesia مستقر در لندن در طول همهگیری کووید، توجه بیشتری را از سوی دنیای شرکتها به خود جلب کردهاند، زیرا قرنطینهها و نگرانیهای بهداشتی باعث شده است که فیلمبرداری ویدیویی با افراد واقعی بسیار دشوارتر شود.
دیپفیک را می توان برای ایجاد آواتارهای شخصی برای امتحان کردن لباس ها یا مدل موهای جدید قبل از امتحان واقعی آنها استفاده کرد.
معایب دیپفیکها:
می توان از دیپفیک برای انتشار اخبار جعلی با ویدیوهای تغییر شکل یافته افراد مشهور استفاده کرد.
همچنین میتوان از دیپفیکها برای ایجاد کمپینهای اطلاعات نادرست در رسانههای اجتماعی استفاده کرد که میتواند افکار عمومی را تغییر دهد و منجر به پیامدهای منفی شود.
ایجاد دیپفیک:
دیپفیکها را میتوان به روشهای مختلف مورد استفاده یا سوء استفاده قرار داد. هر روز که میگذرد، ایجاد آنها با پیشرفتهای بیشتر در هوش مصنوعی آسانتر میشود.
اکنون میتوانیم یک ویدیوی دیپفیک تنها با یک منبع کوچک ویدیویی از شخص ایجاد کنیم. بله، در حال حاضر با آخرین پیشرفتها در شبکههای عصبی به راحتی امکانپذیر است.
بیایید مسئله را به دو قسمت تقسیم کنیم :
شبیه سازی صدا
همگام سازی لب با ویدیو
شبیه سازی صوتی برای ساخت دیپفیک:
SV2TTS چارچوبی برای یادگیری عمیق است که می توان آن را آموزش داد تا صدا را به صورت اعداد و پارامترها بر اساس تنها چند ثانیه کمی از صدای یک فرد ارائه دهد.

گردش کار SV2TTS
Speaker Encoder صدای شخص مورد نظر را که از ویدیوی منبع استخراج شده است دریافت می کند و خروجی کدگذاری شده را به Synthesizer ارسال می کند.
Synthesizer در مورد صدای هدف و جفت رونوشت متن آموزش می بیند و ورودی را ترکیب می کند.
صداگذار عصبی طیف نگارهای تولید شده توسط Synthesizer را به شکل موج خروجی تبدیل می کند.
همگام سازی لب با ویدیو برای ساخت دیپفیک:
Wav2lip یک GAN همگامسازی لب است که یک نمونه صوتی و یک نمونه ویدیوی با طول مساوی از فردی که صحبت میکند را به عنوان ورودی میگیرد. و لب فرد را با صدای ورودی همگامسازی میکند. بنابراین، یک ویدیوی مصنوعی از همان شخص تولید می کند که صدای ورودی را به جای صدای واقعی در ویدیوی نمونه اصلی صحبت می کند.
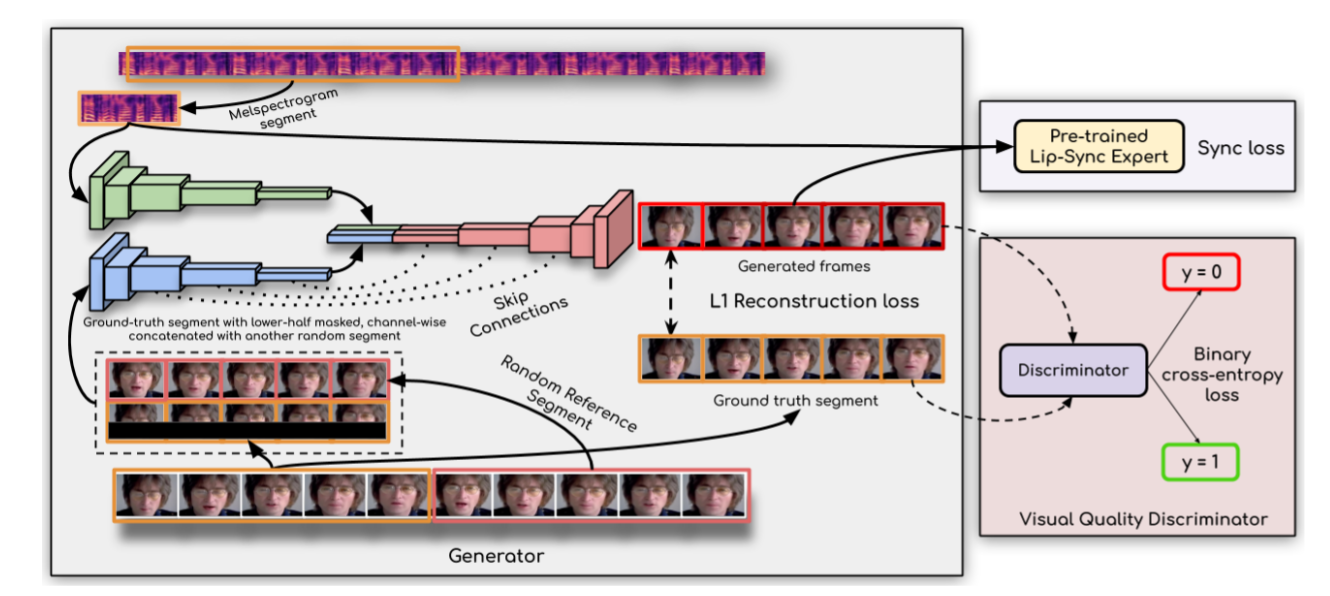
گردش کار همگام سازی لب با ویدیو:
مولد از یک رمزگذار هویت، رمزگذار گفتار و رمزگشای چهره برای تولید فریم های ویدیو استفاده می کند.
discriminator،ژنراتور را برای خطا در تولید در طول فرآیند آموزش، تحت نظر میگیرد.
رقابت بین ژنراتور-تمایزکننده به ویدیوی خروجی نهایی با بالاترین دقت ممکن منجر میشود.
نمونه فیلم مصنوعی:
این یک ویدیوی مصنوعی است که از باراک اوباما در حال صحبت ایجاد شده است. رونوشت متنی که برای ایجاد صدای شبیهسازی صوتی استفاده میشود، اینگونه است: «سلام بچهها، این باراک اوباما است. همانطور که می بینید، این یک ویدیو واقعی نیست. این ویدیوی مصنوعی با شبکه های Generative Adversarial ایجاد شده است.
مراحل انجام کار:
بیایید به مراحل و کدهای موجود در SV2TTS و Wav2Lip نگاهی عمیق بیندازیم.
ویدئو منبع:
ویدئوی منبع را انتخاب کنید . ویدئو می تواند هر طولی داشته باشد و باید فقط شخصیت مورد نظر با کمترین فاصله ممکن صحبت کند. توجه داشته باشید که ویدیوی مصنوعی نهایی تولید شده به اندازه ویدیوی ورودی خواهد بود، بنابراین میتوانید طبق نیاز ویدیو را برش دهید.
استخراج صدا:
صدا را از ویدیوی منبع استخراج کنید. این صدا به عنوان داده های آموزشی برای SV2TTS برای تولید کلون صوتی عمل می کند.
فراخوانی کتابخانه ها:
برای SV2TTS، کتابخانه های لازم را در یک نوت بوک وارد کنید.
import os from os.path import exists, join, basename, splitext import sys from IPython.display import display, Audio, clear_output from IPython.utils import io import ipywidgets as widgets import numpy as np from dl_colab_notebooks.audio import record_audio, upload_audio from synthesizer.inference import Synthesizer from encoder import inference as encoder from vocoder import inference as vocoder from pathlib import Path
Clone SV2TTS Repo :
صدای بلادرنگ را بر اساس SV2TTS کلون کنید و الزامات را نصب کنید.
sys.path.append(name_of_proj)
#url of svt2tts git_repo_url = 'https://github.com/CorentinJ/Real-Time-Voice-Cloning.git' name_of_proj = splitext(basename(git_repo_url))[0]
# clone repo recursively and install dependencies
if not exists(name_of_proj):
# clone and install
!git clone -q --recursive {git_repo_url}
# install dependencies
!cd {name_of_proj}
!pip install -q -r requirements.txt !pip install -q gdown !apt-get install -qq libportaudio2 !pip install -q https://github.com/tugstugi/dl-colab-notebooks/archive/colab_utils.zip
بارگذاری مدل از پیش آموزش دیده:
مدل و synthesizer از قبل آموزش دیده را دانلود و بارگذاری کنید.
# load pretrained model
encoder.load_model(project_name / Path("encoder/saved_models/pretrained.pt"))
# create synthesizer object
synthesizer = Synthesizer(project_name / Path("synthesizer/saved_models/pretrained/pretrained.pt"))
# load model to vocoder
vocoder.load_model(project_name / Path("vocoder/saved_models/pretrained/pretrained.pt"))
صوت را آپلود کنید.
نرخ نمونه، تعبیههای رمزگذار و گزینه آپلود یا ضبط صدا را تنظیم کنید. در این صورت ما صوت را آپلود خواهیم کرد.
# choose appropriate sample rate
SAMPLE_RATE = 22050
# create option to upload or record audio, enter audio duration
rec_upl = "Upld (.mp3 or .wav)" #@param ["Recrd", "Upld (.mp3 or .wav)"]
record_seconds = 600#@param {type:"number", min:1, max:10, step:1}
embedding = None
# compute embeddings def _compute_embedding(audio): display(Audio(audio, rate=SAMPLE_RATE, autoplay=True)) global embedding embedding = None embedding = encoder.embed_utterance(encoder.preprocess_wav(audio, SAMPLE_RATE))
#function for recording your own voice and computing embeddings def _record_audio(b): clear_output() audio = record_audio(record_seconds, sample_rate=SAMPLE_RATE) _compute_embedding(audio)
#function for uploading audio and computing embeddings def _upload_audio(b): clear_output() audio = upload_audio(sample_rate=SAMPLE_RATE) _compute_embedding(audio)
if record_or_upload == "Record":
button = widgets.Button(description="Record Your Voice")
button.on_click(_record_audio)
display(button)
else:
#button = widgets.Button(description="Upload Voice File")
#button.on_click(_upload_audio)
_upload_audio("")
تولید کلون صوتی :
در نهایت، صدا را سنتز کرده و شکل موج خروجی را تولید کنید.
# text for the voice clone to read out in the synthetically generated audio
text = "Hey guys this is Barack Obama. As you can see, this is not a real video. My creator, Suvojit generated this synthetic video with Generative Adversarial Networks. Like and share this video, and message Suvojit if you want to know more details. Bye" #@param {type:"string"}
def synthesize(embed, text):
print("Synthesizing new audio...")
# synthesize the spectrograms
specs = synthesizer.synthesize_spectrograms([text],
) generated_wav = vocoder.infer_waveform(specs[0])
# generate output waveform generated_wav = np.pad(generated_wav, (0, synthesizer.sample_rate), mode="constant") clear_output() display(Audio(generated_wav, rate=synthesizer.sample_rate, autoplay=True))
if embedding is None: print(“upload the audio”) else: synthesize(embedding, text)
Lip-Sync: Clone Wav2Lip Repo :
اکنون زمان تولید ویدیوی همگام سازی لب است. مخزن Wav2Lip را کلون کنید و مدل از پیش آموزش دیده را برای همگام سازی لب بسیار دقیق دانلود کنید. و محتویات را از گول داریو آپلود و کپی کنید.
#download: https://github.com/Rudrabha/Wav2Lip#training-on-datasets-other-than-lrs2 !git clone https://github.com/Rudrabha/Wav2Lip.git
# copy checkpoints from google drive to session storage
!cp -ri "/content/gdrive/MyDrive/Files/Wav2lip/wav2lip_gan.pth" /content/Wav2Lip/checkpoints/ !cp -ri "/content/gdrive/MyDrive/Files/Wav2lip/wav2lip.pth" /content/Wav2Lip/checkpoints/ !cd Wav2Lip && pip install -r requirements.txt !wget "https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth" -O "Wav2Lip/face_detection/detection/sfd/s3fd.pth"
پیش پردازش داده های صوتی و تصویری:
اکنون فایل ها را برای پردازش تنظیم کنید.
%cd sample_data/ %rm input_audio.wav %rm input_video.mp4 from google.colab import files uploaded = files.upload() %cd ..
!cd Wav2Lip && python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face "/content/sample_data/input_video.mp4" --audio "/content/sample_data/input_audio.wav" from google.colab import files
# download the voice generated in previous steps to session storage
files.download('/content/Wav2Lip/results/result_voice.mp4')
from IPython.display import HTML
from base64 import b64encode
# read binary of the audio file
mp4 = open('/content/Wav2Lip/results/result_voice.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML(f"""
<video width="50%" height="50%" controls>
<source src="{data_url}" type="video/mp4">
</video>
""")
آپلود فایل های ورودی برای Wav2Lip:
فایلهای input_video.mp4 و input_audio.wav را آپلود کنید. صدای ورودی در مرحله قبل از SV2TTS تولید شد.
%cd sample_data/ from google.colab import files uploaded = files.upload() %cd ..
ویدیوی Lip-Sync را ایجاد کنید.
ویدیو wav2lip را با مدل از پیش آموزش دیده ایجاد کنید.
# set the args for checkpoint and input files and generate the lip sync video
!cd Wav2Lip && python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face "/content/sample_data/input_video.mp4" --audio "/content/sample_data/input_audio.wav"
دیپفیک را در رایانه شخصی خود دانلود کنید:
اکنون می توانید دیپ فیک را در درایو گوگل و کامپیوتر خود دانلود کنید.
files.download('/content/Wav2Lip/results/result_voice.mp4')
مطالب زیر را حتما مطالعه کنید

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

ذخیره و بارگذاری مدل در پایتون

محل بررسی مدل های شبکه عصبی
شبکه خودرمزنگار متغیر (variational autoencoder) چیست؟

تجزیه و تحلیل داده با پایتون

دیدگاهتان را بنویسید