
منحنی AUC-ROC در یادگیری ماشین

فرض کنید،شما مدل یادگیری ماشینی خود را ساخته اید. پس قدم بعدی چیست؟ شما باید آن را ارزیابی کنید و میزان خوب (یا بد) بودن آن را تأیید کنید.بنابراین می توانید در مورد اجرای آن تصمیم بگیرید. اینجاست که منحنی AUC-ROC در یادگیری ماشین مورد استفاده قرار میگیرد.
در حال حاضر، فقط بدانید که منحنی AUC-ROC به ما کمک می کند تا میزان عملکرد طبقه بندی کننده یادگیری ماشین خود را تجسم کنیم. اگرچه فقط برای مسائل طبقهبندی باینری کار میکند، اما در پایان خواهیم دید که چگونه میتوانیم آن را برای ارزیابی مسائل طبقهبندی چند کلاسه نیز گسترش دهیم.
ما موضوعاتی مانند sensitivity و specificity را نیز پوشش خواهیم داد زیرا اینها موضوعات کلیدی در پشت منحنی AUC-ROC هستند.
sensitivity و specificity چیست؟
این چیزی است که یک confusion matrix به نظر می رسد:
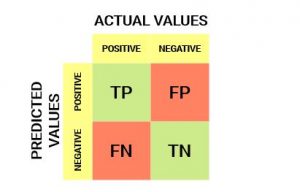
از confusion matrix ، میتوانیم برخی از معیارهای مهم را استخراج کنیم. بیایید در اینجا در مورد آنها صحبت کنیم.
Sensitivity / True Positive Rate / Recall
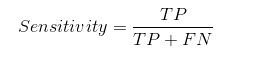
sensitivity به ما می گوید که چه نسبتی از طبقه مثبت به درستی طبقه بندی شده است.یک مثال ساده این است که مشخص شود چه نسبتی از افراد بیمار واقعی به درستی توسط مدل شناسایی شده اند.
False Negative Rate
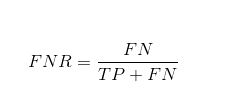
نرخ منفی کاذب (FNR) به ما می گوید که چه نسبتی از کلاس مثبت توسط طبقه بندی کننده به اشتباه طبقه بندی شده است.
TPR بالاتر و FNR پایین تر مطلوب است زیرا ما می خواهیم طبقه مثبت را به درستی طبقه بندی کنیم.
Specificity / True Negative Rate
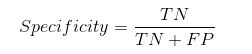
Specificity به ما می گوید که چه نسبتی از کلاس منفی به درستی طبقه بندی شده است.
با در نظر گرفتن مثال مشابه در Specificity ، Sensitivityبه معنای تعیین نسبت افراد سالمی است که به درستی توسط مدل شناسایی شده اند.
False Positive Rate
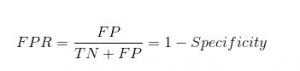
FPR به ما می گوید که چه نسبتی از کلاس منفی توسط طبقه بندی کننده به اشتباه طبقه بندی شده است.
یک TNR بالاتر و یک FPR کمتر مطلوب است زیرا ما می خواهیم طبقه منفی را به درستی طبقه بندی کنیم.
از بین این معیارها، Sensitivity و Specificity شاید مهمترین آنها باشد و بعداً خواهیم دید که چگونه از آنها برای ایجاد یک معیار ارزیابی استفاده می شود.
احتمال پیش بینیها
یک مدل طبقه بندی یادگیری ماشین می تواند برای پیش بینی کلاس واقعی داده به طور مستقیم، و یا پیش بینی احتمال تعلق آن به کلاس های مختلف استفاده شود. دومی به ما کنترل بیشتری بر نتیجه می دهد. ما می توانیم آستانه خود را برای تفسیر نتیجه طبقه بندی کننده تعیین کنیم. این گاهی اوقات عاقلانه تر از ساختن یک مدل کاملاً جدید است!
تعیین آستانه های مختلف برای طبقه بندی کلاس مثبت برای نقاط داده، به طور ناخواسته Sensitivity و Specificity مدل را تغییر می دهد. و یکی از این آستانه ها احتمالاً نتیجه بهتری نسبت به بقیه خواهد داشت، بسته به این که آیا قصد داریم تعداد منفی های کاذب یا مثبت های کاذب را کاهش دهیم.
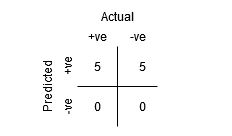
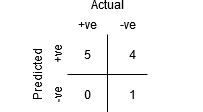
به جدول زیر دقت کنید:
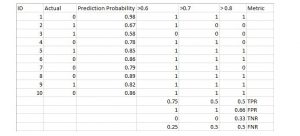
معیارها با تغییر مقادیر آستانه تغییر می کنند. ما میتوانیم confusion matrix مختلفی تولید کنیم و معیارهای مختلفی را که در بخش قبل مورد بحث قرار دادیم، مقایسه کنیم. اما این کار عاقلانه ای نخواهد بود. در عوض، کاری که میتوانیم انجام دهیم این است که یک نمودار بین برخی از این معیارها ایجاد کنیم تا بتوانیم به راحتی تصور کنیم که کدام آستانه نتیجه بهتری به ما میدهد.
منحنی AUC-ROC در یادگیری ماشین چیست؟
منحنی (ROC) یک معیار ارزیابی برای مسائل طبقه بندی باینری است. این یک منحنی احتمال است که TPR را در برابر FPR در مقادیر آستانه مختلف ترسیم می کند. و اساسا “سیگنال” را از “نویز” جدا می کند. منطقه زیر منحنی (AUC) اندازه گیری توانایی طبقه بندی کننده برای تمایز بین کلاس ها است و به عنوان خلاصه منحنی ROC استفاده می شود.
هر چه AUC بالاتر باشد، عملکرد مدل در تشخیص کلاس های مثبت و منفی بهتر است.
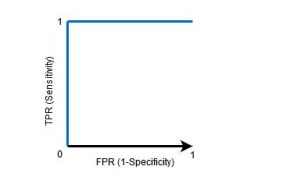
وقتی AUC = 1، طبقهبندیکننده میتواند کاملاً بین تمام نقاط کلاس مثبت و منفی به درستی تمایز قائل شود. با این حال، اگر AUC =0 بود، طبقهبندیکننده همه منفیها را بهعنوان مثبت و همه مثبتها را بهعنوان منفی پیشبینی میکرد.
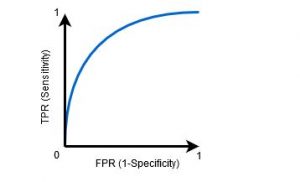
وقتی AUC بین 0.5 و 1 باشد، احتمال زیادی وجود دارد که طبقه بندی کننده بتواند مقادیر کلاس مثبت را از مقادیر کلاس منفی تشخیص دهد. این به این دلیل است که طبقهبندیکننده میتواند تعداد بیشتری از مثبتها و منفیهای درست را نسبت به منفیهای غلط و مثبتهای غلط تشخیص دهد.
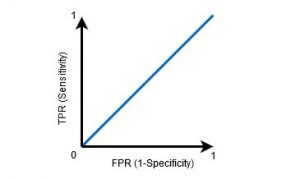
وقتی AUC=0.5 باشد، طبقه بند قادر به تشخیص نقاط کلاس مثبت و منفی نیست. به این معنی که طبقه بندی کلاس تصادفی یا کلاس ثابت را برای تمام نقاط داده پیش بینی می کند.
بنابراین، هر چه مقدار AUC برای یک طبقهبندیکننده بالاتر باشد، توانایی آن در تشخیص کلاسهای مثبت و منفی بهتر است.
منحنی AUC-ROC در یادگیری ماشین چگونه کار میکند؟
در منحنی ROC، مقدار بالاتر X نشاندهنده تعداد بیشتری از تشخیصهای مثبت کاذب نسبت به نقاط منفی حقیقی است. در حالی که مقدار محور Y بالاتر نشاندهنده تعداد بیشتری از تشخیصهای مثبت حقیقی نسبت به نقاط منفی کاذب است. بنابراین انتخاب آستانه به توانایی تعادل بین تشخیصهای مثبت کاذب و منفی کاذب بستگی دارد.
بیایید کمی عمیقتر کنیم و درک کنیم که نمودار ROC چگونه به مقادیر آستانه مختلف و این که چگونه Sensitivity و Specificity تغییر میکند، نگاه میکند.
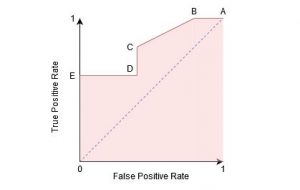
ما میتوانیم با ایجاد یک confusion matrix برای هر نقطه مربوط به آستانه، سعی کنیم این نمودار را درک کنیم و در مورد عملکرد طبقهبند خود صحبت کنیم:
نقطه A جایی است که Sensitivity بالاترین و Specificity کمترین است. این بدان معناست که تمام نقاط کلاس مثبت به درستی طبقه بندی شدهاند و تمام نقاط کلاس منفی به اشتباه طبقه بندی شدهاند.
در واقع، هر نقطه از خط آبی با وضعیتی مطابقت دارد که در آن نرخ مثبت واقعی برابر با نرخ مثبت نادرست است.
تمام نقاط بالای این خط با وضعیتی مطابقت دارد که در آن نسبت نقاط طبقهبندی شده به درستی متعلق به کلاس مثبت بیشتر از نسبت نقاط طبقهبندی نادرست متعلق به کلاس منفی است.
اگر چه نقطه B دارای Sensitivity یکسانی با نقطه A است، اما دارای Specificity بالاتری است. به این معنی که تعداد امتیازهای کلاس منفی نادرست در مقایسه با آستانه قبلی کمتر است. این نشان میدهد که این آستانه بهتر از آستانه قبلی است.

بین نقاط C و D، حساسیت در نقطه C بالاتر از نقطه D برای همان Specificity است. این بدان معناست که برای همان تعداد امتیاز کلاس منفی طبقهبندی شده اشتباه، طبقهبند تعداد بیشتری از امتیازهای کلاس مثبت را پیش بینی کرده است. بنابراین، آستانه در نقطه C بهتر از نقطه D است.
حالا، بسته به این که چه تعداد از نکاتی را که میخواهیم برای طبقهبندمان انتخاب کنیم، انتخاب میکنیم، بین نقطه B یا C برای پیشبینی اینکه آیا شما میتوانید مرا در PUBG شکست دهید یا خیر انتخاب میکنیم.

نقطه E جایی است که Specificity به بالاترین حد خود می رسد. به این معنی که هیچ مثبت کاذب طبقه بندی شده توسط مدل وجود ندارد. مدل می تواند به درستی تمام نقاط کلاس منفی را طبقه بندی کند!
با توجه به این منطق، آیا می توانید حدس بزنید که نقطه مربوط به یک طبقه بندی کننده کامل در کجای نمودار قرار دارد؟
آره! این در گوشه سمت چپ بالای نمودار ROC مربوط به مختصات (0، 1) در صفحه دکارتی خواهد بود. اینجاست که هر دو، Sensitivity و Specificity ، بالاترین هستند و طبقهبندیکننده به درستی تمام نقاط کلاس مثبت و منفی را طبقهبندی میکند.
آشنایی با منحنی AUC-ROC در یادگیری ماشین با پایتون
اکنون به جای این که به صورت دستی Sensitivity و Specificity را برای هر آستانه آزمایش کنیم،اجازه میدهیم sklearn این کار را برای ما انجام دهد.
عملکرد دو طبقهبندی کننده را روی این مجموعه داده آزمایش خواهیم کرد:
# train models from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier # logistic regression model1 = LogisticRegression() # knn model2 = KNeighborsClassifier(n_neighbors=4) # fit model model1.fit(X_train, y_train) model2.fit(X_train, y_train) # predict probabilities pred_prob1 = model1.predict_proba(X_test) pred_prob2 = model2.predict_proba(X_test)
Sklearn یک روش بسیار قدرتمند roc_curveدارد که ROC را برای طبقهبندی کننده شما در عرض چند ثانیه محاسبه میکند! مقادیر FPR، TPR و آستانه را برمیگرداند:
from sklearn.metrics import roc_curve # roc curve for models fpr1, tpr1, thresh1 = roc_curve(y_test, pred_prob1[:,1], pos_label=1) fpr2, tpr2, thresh2 = roc_curve(y_test, pred_prob2[:,1], pos_label=1) # roc curve for tpr = fpr random_probs = [0 for i in range(len(y_test))] p_fpr, p_tpr, _ = roc_curve(y_test, random_probs, pos_label=1)
امتیاز AUC را می توان با استفاده از روش roc_auc_score() sklearn محاسبه کرد:
from sklearn.metrics import roc_auc_score # auc scores auc_score1 = roc_auc_score(y_test, pred_prob1[:,1]) auc_score2 = roc_auc_score(y_test, pred_prob2[:,1]) print(auc_score1, auc_score2)
0.9761029411764707 0.9233769727403157
ما همچنین می توانیم منحنی های ROC را برای دو الگوریتم با استفاده از matplotlib رسم کنیم:
# matplotlib
import matplotlib.pyplot as plt
plt.style.use('seaborn')
# plot roc curves
plt.plot(fpr1, tpr1, linestyle='--',color='orange', label='Logistic Regression')
plt.plot(fpr2, tpr2, linestyle='--',color='green', label='KNN')
plt.plot(p_fpr, p_tpr, linestyle='--', color='blue')
# title
plt.title('ROC curve')
# x label
plt.xlabel('False Positive Rate')
# y label
plt.ylabel('True Positive rate')
plt.legend(loc='best')
plt.savefig('ROC',dpi=300)
plt.show();
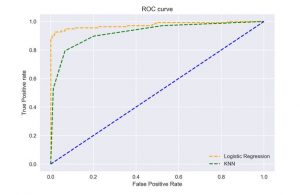
از نمودار مشخص است که AUC برای منحنی ROC رگرسیون لجستیک بالاتر از منحنی ROC KNN است. بنابراین، می توان گفت که رگرسیون لجستیک کار بهتری را در طبقه بندی کلاس مثبت در مجموعه داده انجام داده است.
AUC-ROC برای طبقه بندی چند کلاسه:
همانطور که قبلاً گفتم، منحنی AUC-ROC فقط برای مسائل طبقه بندی باینری است. اما میتوانیم آن را با استفاده از تکنیک One vs All به مسائل طبقهبندی چند کلاسه تعمیم دهیم.
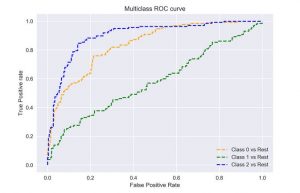
منحنی ROC برای مدل های طبقه بندی چند کلاسه را می توان به صورت زیر تعیین کرد:
# multi-class classification
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
# generate 2 class dataset
X, y = make_classification(n_samples=1000, n_classes=3, n_features=20, n_informative=3, random_state=42)
# split into train/test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
# fit model
clf = OneVsRestClassifier(LogisticRegression())
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
pred_prob = clf.predict_proba(X_test)
# roc curve for classes
fpr = {}
tpr = {}
thresh ={}
n_class = 3
for i in range(n_class):
fpr[i], tpr[i], thresh[i] = roc_curve(y_test, pred_prob[:,i], pos_label=i)
# plotting
plt.plot(fpr[0], tpr[0], linestyle='--',color='orange', label='Class 0 vs Rest')
plt.plot(fpr[1], tpr[1], linestyle='--',color='green', label='Class 1 vs Rest')
plt.plot(fpr[2], tpr[2], linestyle='--',color='blue', label='Class 2 vs Rest')
plt.title('Multiclass ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive rate')
plt.legend(loc='best')
plt.savefig('Multiclass ROC',dpi=300);
دیدگاهتان را بنویسید