
نحوه آموزش دیتاست های بسیار بزرگ با استفاده از یادگیری ترکیبی
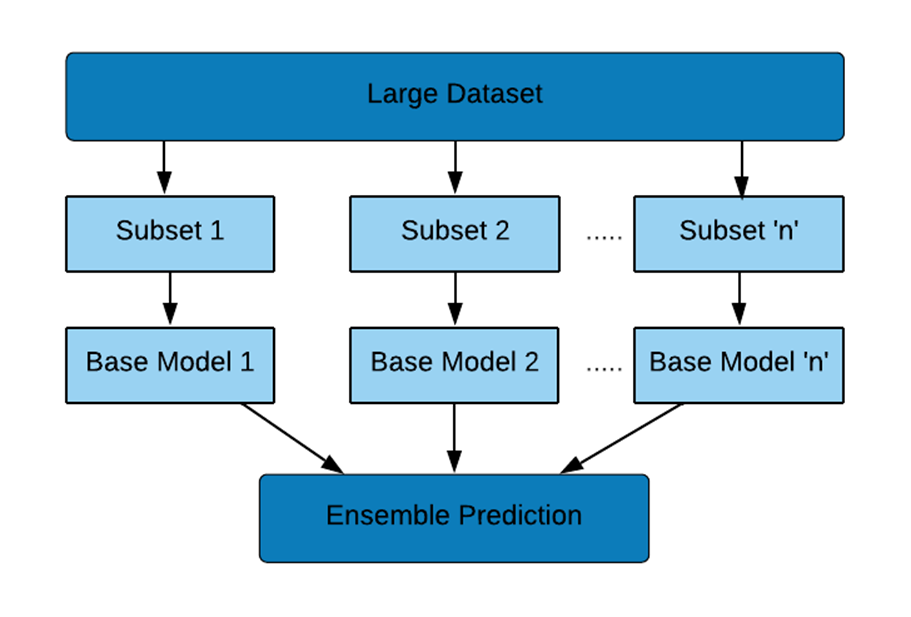
مشکل آموزش دیتاست های بسیار بزرگ در یادگیری ماشین
تا حالا ممکن است که برای شما اتفاق افتاده باشد که با یک دیتاست بسیار بزرگ روبرو شده باشید که بخواهید یک مدل یادگیری ماشین را روی آن آموزش دهید. اما متوجه میشوید که منابع سخت افزاری کافی برای این مسئله در اختیار ندارید. در این هنگام ممکن است راه حل های مختلفی به ذهن شما برسند. در این مقاله سعی میکنیم یک راه حل مبتنی بر مدل سازی ترکیبی یا یادگیری ترکیبی (ensemple learning) معرفی کنیم. در ابتدا با مفهوم یادگیری ترکیبی یا ensemble learning بیشتر آشنا می شویم.
یادگیری ترکیبی Ensemble Learning
مدلسازی جمعی، فرآیندی است که طی آن یک مدل یادگیری ماشینی مدلهای پایه مجزا را برای تولید پیشبینیهای تعمیمیافته با استفاده از ترکیبی از قدرت پیشبینی هر یک از اجزای آن ترکیب میکند. هر مدل پایه با توجه به داده های آموزشی مورد استفاده و معماری الگوریتم/مدل متفاوت است. هر یک از اینها ممکن است فقط چند جنبه را به تصویر بکشد یا فقط از بخشی از داده های آموزشی به طور موثر یاد بگیرد. مدلسازی جمعی این فرصت را برای ما فراهم میکند که همه این مدلها را برای به دست آوردن یک مدل برتر واحد که مبتنی بر آموختههای بیشتر یا همه بخشهای مجموعه داده آموزشی است، ترکیب کنیم.
میانگینگیری پیشبینیها همچنین به ریشهکن کردن مسئله تثبیت مدلهای فردی بر روی حداقلهای محلی کمک میکند. یکی از ویژگی های جالب مدل سازی جمعی این است که محدودیتی در تعداد مدل های پایه قابل استفاده وجود ندارد. ممکن است از هر چیزی از کمتر از 2 تا حداکثر 10 مدل پایه یا “اعضای گروه” متغیر باشد.
در حالی که مدلسازی مجموعه اساساً برای بهبود قدرت محاسباتی مدلهای مورد استفاده برای مسائل طبقهبندی یا پیشبینی انجام میشود، همانطور که میتوان از چندین مسابقه Kaggle مشاهده کرد که در آن برنده به سادگی چندین مدل پایه را برای تولید یک مدل قابل تعمیم با دقت بیشتر ترکیب کرده است. آنها را می توان برای انواع توابع دیگر استفاده کرد.
مزایای مدل سازی جمعی (یادگیری ترکیبی) برای شبکه های عصبی
مزایای آن را می توان در دو دسته کلی طبقه بندی کرد:
1) افزایش عملکرد – با ترکیب قدرت پیشبینی «اعضای گروه»، یک مدل مجموعه قادر است نتایجی با قابلیت تعمیم بیشتر و حتی دقت بیشتر در اکثر موارد تولید کند.
در هنگام برخورد با هر مشکل یادگیری ماشین، هدف اصلی ساخت مدلی است که خطای تعمیم (generalization) کم و دقت بالا ایجاد کند. با استفاده از ترکیبهای تجمیع مناسب مدلهای پایه یا «یادگیرندگان ضعیف»، یک مدل مجموعهای قادر است مدلی ایجاد کند که بتواند از دادههای آموزشی بهتر یاد بگیرد و در نتیجه نتایج بهتری تولید کند.
2) افزایش قابلیت اطمینان – مدل های تکی و پایه اغلب از مشکلات مربوط به واریانس، بایاس و نویز رنج می برند. با کاهش بایاس و واریانس و وزن دادن به تعداد بیشتری از ویژگی ها، مدل جمعی، به طور کلی قابلیت اطمینان و استحکام را افزایش می دهد. استحکام واریانس کم را نشان می دهد که نشان دهنده مدلی است که تحت تأثیر ناهماهنگی های کوچک در داده های آموزشی قرار ندارد. حتی اگر دقت مدل بهبود نیابد، مجموعه به کاهش واریانس یا گسترش پیشبینی دست مییابد.
بر اساس شکل زیر متوجه می شویم که میزان خطا برابر حاصلجمع دو مقدار بایاس و واریانس است. هر چه مدل پیچیده تر باشد، بایاس آن کمتر و واریانس آن بیشتر است. و بالعکس هر چه مدل ساده تر باشد میزان بایاس آن بیشتر و واریانس آن کمتر خواهد بود. اما انتخاب بهینه حالتی است که حد وسط این دو باشد. بنابراین مدل خیلی پیچیده هم خوب نیست. زیرا مدل خیلی پیچیده باعت overfitting و مدل خیلی ساده باعث underfitting می شود.
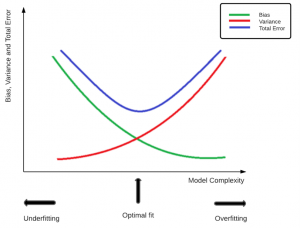
این امر به این دلیل اعمال می شود که یک مدل با واریانس بالا تمایل به پیچیده بودن بیش از حد دارد، بنابراین منجر به افزایش حساسیت می شود، که در نهایت منجر به تاثیر نامطلوب مدل توسط نویز و در نتیجه برازش بیش از حد داده ها می شود. در چنین حالتی، مدل میتواند روی دادههای آموزشی بسیار خوب عمل کند، اما وقتی با دادههای دیده نشده مواجه میشود، نمیتواند نتایج دقیقی تولید کند.
از طرف دیگر یک مدل underfit هم در تمرین و هم در دادههای دیده نشده یا آزمایش ضعیف عمل میکند. چنین مدل هایی به دلیل تعصب زیاد و واریانس کم، بیش از حد ساده شده اند و قادر به ثبت الگوهای موجود در مجموعه داده نیستند. یک مدل برازش بهینه هدف نهایی هر دانشمند داده است و این در مقادیر ایدهآل هم بایاس و هم واریانس به دست میآید.
بنابراین، یک مدل ترکیبی منجر به بهبود قابل توجهی در عملکرد مدل کلی می شود. علاوه بر این، با اجازه دادن به ترکیب های مختلف مدل های سازنده و همچنین تکنیک ها، انعطاف پذیری بیشتری را در ساخت مدل ها ارائه می دهد.
در حالی که درک نحوه استفاده از مدل سازی ترکیبی مهم است، به همان اندازه مهم است که بفهمیم چه زمانی و کجا باید از آن استفاده کنیم.
آیا ترکیب کلاسیفایرها یا مدل سازی ترکیبی همیشه بهترین انتخاب است؟
پاسخ سرراست به این سوال منفی است. وقتی صحبت از مدلسازی ترکیبی به میان میآید، در حالی که به نظر میرسد مزایا از معایب آن بیشتر است، همیشه ایده خوبی است که قبل از انتخاب یک مدل مجموعه، مشکل و الزامات آن را به درستی تجزیه و تحلیل کنید.
اجازه دهید یک مسئله پیشبینی ساده شامل مجموعه دادههای کوچک با ویژگیهای کمی را در نظر بگیریم. مدل سازی مجموعه شامل ترکیب چندین مدل است که به طور خودکار به آموزش و زمان محاسباتی بالاتر تبدیل می شود. در چنین سناریویی، انتخاب یک مدل واحد برای مثال. رگرسیون خطی ساده، ممکن است در واقع منجر به نتایج بهتر و مدل دقیق تر شود.
روشهای ترکیبی معمولاً زمانی انجام میشوند که نیاز به بهینهسازی عملکرد مدل وجود داشته باشد. در شرایطی که قبلاً یک مدل بسیار دقیق به دست آوردهایم، نیازی به مدل ترکیبی وجود ندارد. همچنین کاملاً ممکن است که یک مدل مجموعه نتواند دقت کلی را افزایش دهد. این در صورتی امکانپذیر است که فقط یکی از اعضا عملکرد خوبی داشته باشد و بقیه یا اصلاً مشارکتی نداشته باشند یا حتی منجر به کاهش میانگین دقت پیشبینی شود. مدلسازی ترکیبی همچنین منجر به کاهش قابل توجهی در توضیحپذیری مدل میشود.
از این رو، برای اینکه بهتر بگوییم چرا مدلسازی گروهی همیشه بهترین انتخاب نیست، اجازه دهید نگاهی به مزایا و معایب هر مدل گروه بیندازیم.
مزایا
1) تعمیم پذیری بیشتر و عملکرد کلی بهتر.
2) کاهش واریانس، بایاس و نویز.
3) یادگیری بهتر از مجموعه داده های بزرگ و انتخاب ویژگی های بهبود یافته.
معایب
1) افزایش پیچیدگی زیرا نیاز به ساخت و ترکیب بیش از یک مدل پایه وجود دارد.
2) از دست دادن قابلیت توضیح مدل.
بنابراین، دانستن اینکه چه زمانی و در کجا باید اعمال شود، ضروری است تا از افزونگی در مدلسازی جلوگیری شود. همچنین، به روشی مشابه اینکه ما با مدلهای مختلف قبل از انتخاب بهترین مدل آزمایش میکنیم، مهم است که تکنیک مجموعه صحیح را انتخاب کنیم و پارامترهای مختلف آن را متناسب با نیازهای مشکل تنظیم کنیم.
در این مقاله، استفاده از مدلسازی مجموعه برای غلبه بر محدودیتهای ایجاد شده توسط یک مجموعه داده بزرگ شرح داده شده است.
انگیزه مدلسازی گروهی برای شبکه های عصبی
اکثر IDE ها مانند Jupyter اندازه حافظه پیش فرض محدودی دارند، که می توان آن را افزایش داد، با این حال، سایر مشکلات مربوط به حافظه باقی می مانند. در حالی که یک CPU قوی تر یا RAM بزرگتر ممکن است راه حل های محتمل باشد، این ممکن است گران باشد. یک راه حل مقرون به صرفه، تقسیم مجموعه داده به زیرمجموعه های کوچکتر است و این زیرمجموعه های ایجاد شده را می توان به راحتی بارگیری کرد و توسط مدل های پایه فردی مورد استفاده قرار داد.
یک خطای رایج توسط مبتدیان با استفاده از مجموعه داده های بزرگ این است که بخشی از آن را دور می اندازند. این می تواند منجر به مدلی با دقت کمتر شود. زیرا ممکن است ویژگی های مهم همراه با بخشی از مجموعه داده از بین برود. به عنوان مثال، اجازه دهید مجموعه داده ای را در قالب اسکن مغزی بیماران در نظر بگیریم که برای ساختن یک طبقه بندی برای تشخیص وجود یک اختلال روانی استفاده می شود. طبقه بندی کننده، الگوهای هر تصویر را در نظر می گیرد تا نحوه طبقه بندی وجود یا عدم وجود اختلال را بیاموزد. دور انداختن بخشی از مجموعه داده ممکن است منجر به کاهش دقت شود زیرا ویژگیهای مهم (الگوها) ممکن است از بین بروند. بنابراین، مقرون به صرفه ترین و موثرترین روش استفاده از یک مجموعه داده بزرگ برای آموزش یک شبکه عصبی، مدلسازی ترکیبی است.
چرا از مدل سازی گروهی برای شبکه های عصبی استفاده کنیم؟
شبکه های عصبی مدل های بسیار پیچیده ای هستند و می توانند برای کاربردهای مختلفی استفاده شوند. با افزایش پیچیدگی مدل، توانایی آنها برای تطبیق بهتر با داده های آموزشی نیز افزایش می یابد. با این حال، این با خطر افزایش حساسیت همراه است. حساسیت بیش از حد منجر به تأثیر نامطلوب شبکه عصبی از حضور نویز در داده ها و نادیده گرفتن ویژگی ها و الگوهای مهم ضروری برای آموزش می شود. بنابراین، تقریباً تمام شبکههای عصبی از همان اشکال رنج میبرند، یعنی واریانس بالا یا تمایل به بیشبرازش.
مدلسازی مجموعهای از شبکههای عصبی، منجر به اضافه شدن بایاس میشود، که به نوبه خود، با کاهش ارزش واریانس بالای اعضای منفرد، منجر به بهبود مبادله بایاس واریانس مدل کلی میشود. علاوه بر افزایش قابلیت اطمینان و کاهش خطای تعمیم، ممکن است دقت پیشبینیها را نیز افزایش دهد.
چرا از مجموعه داده های بزرگ استفاده کنیم؟
یکی از عوامل اصلی که روشهای یادگیری عمیق مانند شبکههای عصبی را از سایر تکنیکهای یادگیری ماشین متمایز میکند، حجم انبوه دادههای مورد نیاز برای آموزش آنها به منظور دستیابی به عملکرد مناسب است. آموزش بر روی مجموعه داده های بزرگ تا حدی به مقابله با مشکل شبکه عصبی واریانس بالا کمک می کند. زمانی که مدل در معرض تعداد بیشتری از نمونه داده ها قرار می گیرد، شانس بیش از حد برازش داده های آموزشی (overfitting) به شدت کاهش می یابد. عملکرد اصلی مدل های یادگیری عمیق، تعیین بهترین مسیر از پارامترهای ورودی به خروجی است. برای این کار، باید ویژگی های مناسب را انتخاب کرده و الگوهای نامحسوس را در مجموعه داده شناسایی کند. یک مجموعه داده بزرگ با ارائه مزایای زیر این کار را امکان پذیر می کند:
1) انتخاب ویژگی – انتخاب ویژگی بهبود یافته به دلیل قرار گرفتن در معرض طیف گسترده ای از ویژگی ها و فرصت بیشتر برای شناسایی چنین الگوهایی.
2) کاهش نویز – به مبارزه با مشکل نویز در داده ها کمک می کند. هرچه داده ها بیشتر باشد، یافتن الگوهای اساسی و غلبه بر نویز آسان تر است.
3) دقت بهبود یافته – داده های آموزشی بیشتر نیز دقت و عملکرد مدل را بهبود می بخشد.
بنابراین، برای استفاده از این مزایا، مجموعه داده های بزرگتر برای آموزش شبکه های عصبی ترجیح داده می شوند.
روند مدلسازی جمعی برای شبکه های عصبی
در این مورد، مراحل زیر برای ایجاد مدل گروه انجام می شود:
1) مجموعه داده به دو یا چند زیر مجموعه تقسیم می شود (بسته به اندازه مجموعه داده)
2) مدل های پایه (شبکه های عصبی کانولوشن – CNN در اینجا) بر روی زیر مجموعه داده ها ساخته شده اند. CNN های منفرد با معماری مشابه (یا یکسان) می توانند مورد استفاده قرار گیرند زیرا عملکردی معادل در زیر مجموعه های مجموعه داده یکسان خواهند داشت. هر مدل با نام های منحصر به فرد ذخیره می شود.
3) مدل ها بارگذاری می شوند.
4) مدل های پایه با استفاده از روش های API عملکردی Keras ترکیب می شوند.
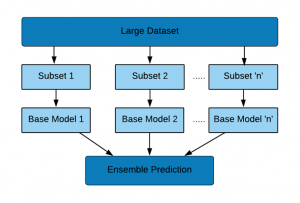
در فلوچارت بالا تعداد مناسب زیر مجموعه ها/مدل های پایه بسته به اندازه مجموعه داده آموزشی انتخاب می شود.
API عملکردی Keras در مقایسه با API متوالی Keras انعطاف پذیری بیشتری را در ایجاد مدل ها فراهم می کند. مشکلات پیچیده از جمله مواردی که دارای مدل های ورودی یا خروجی متعدد هستند را می توان با استفاده از این قابلیت Keras به راحتی حل کرد. در اینجا، از Keras sequential API برای ایجاد مدل های پایه و Keras از API کاربردی برای ترکیب آنها استفاده می کنیم.
خلاصه روش
مجموعه داده را به صورت دستی یا با استفاده از کد به دو یا چند زیر مجموعه تقسیم کنید.
مدل های پایه فردی را با استفاده از زیر مجموعه ها ایجاد کنید. مدل های پایه ممکن است برای زیرمجموعه های مربوطه با انتخاب پارامترهای مناسب بهینه شوند. با این حال، باید اطمینان حاصل شود که شکل ورودی برای همه ثابت است.
در زیر، کد نمونه برای ایجاد مدل گروه متوسط با استفاده از رابط کاربردی API عملکردی Keras، ارائه شده است. میانگینگیری مدل تکنیکی است که در آن از چندین مدل برای یک مسئله استفاده میشود و پیشبینیهای آنها را برای به دست آوردن یک مدل واحد و دقیقتر ترکیب میکند.
کد نمونه:
پس از ایجاد مدل های پایه فردی با استفاده از زیر مجموعه های داده های آموزشی، مدل ها را می توان به صورت زیر ذخیره کرد:
model.save("m1.tf")
print("Saved model to disk")
لود کردن مدل های پایه:
from tensorflow.keras.models import load_model
model1 = load_model('m1.tf')
model2 = load_model('m2.tf')
model3 = load_model('m3.tf')
import tensorflow.keras import tensorflow as tf
#Initiating the usage of individual models
keras_model = tensorflow.keras.models.load_model('m1.tf, compile=False)
keras_model._name = 'model1'
keras_model2 = tensorflow.keras.models.load_model('m2.tf', compile=False)
keras_model2._name = 'model2'
keras_model3 = tensorflow.keras.models.load_model('m3.tf', compile=False)
keras_model3._name = 'model3'
models = [keras_model, keras_model2, keras_model3] #stacking individual models in a list
model_input = tf.keras.Input(shape=(124, 124, 1)) #takes a list of tensors as input, all of the same shape
model_outputs = [model(model_input) for model in models] #collects outputs of models in a list
ensemble_output = tf.keras.layers.Average()(model_outputs) #averaging outputs
ensemble_model = tf.keras.Model(inputs=model_input, outputs=ensemble_output)
سایر توابع Keras که ممکن است به جای «میانگین» استفاده شوند (میانگین فهرست ورودیها را محاسبه میکند، از نظر عنصر) توابع «حداکثر» (حداکثر فهرست ورودیها را محاسبه میکند، از نظر عنصر) و « Add’ (لیستی از ورودی ها را اضافه می کند) بسته به نیاز مدل. کد ثابت می ماند، به سادگی کلمه “Average” را با “Maximum” یا “Add” جایگزین کنید.
نتیجه
ما اغلب با مشکلات حافظه یا محاسباتی در هنگام برخورد با مجموعه داده های بزرگ روبرو هستیم. شبکه های عصبی به عنوان مدل های پیچیده به مجموعه داده های بزرگی نیاز دارند تا عملکرد خود را افزایش دهند و بنابراین اغلب با چنین مسائلی مواجه می شوند. یک راه حل ساده برای این مشکل، تقسیم مجموعه داده به تعداد مناسبی از زیر مجموعه ها و ساخت مدل های پایه در هر زیر مجموعه است. سپس این زیر مجموعهها با استفاده از مدلسازی گروهی – با استفاده از API عملکردی Keras در اینجا ترکیب میشوند.
جدا از غلبه بر چالش مدیریت مجموعه داده های بزرگ، مدل سازی مجموعه به غلبه بر چندین مسئله دیگر مانند واریانس بزرگ و خطای تعمیم، با بهبود دقت کلی مدل کمک می کند. بنابراین، برای خلاصهای از مقاله، میتوان گفت که مدلسازی مجموعه راهحلی آسان و مقرونبهصرفه در بهبود عملکرد مدل ارائه میدهد و در عین حال استفاده از منابع محاسباتی و ذخیرهسازی را نیز بهینه میکند.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

دیدگاهتان را بنویسید