
واقعا شبکه های عصبی چگونه کار می کنند؟
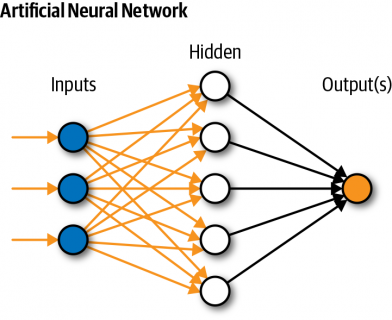
واقعا شبکه های عصبی چگونه کار می کنند؟
ریاضیات پشت شبکه های عصبی
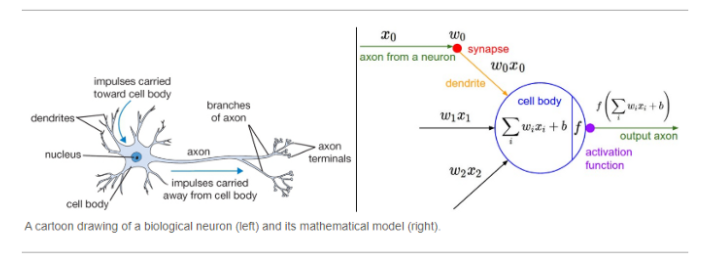
شبکه های عصبی هسته یادگیری عمیق را تشکیل می دهند، زیر مجموعه ای از یادگیری ماشینی که در مقاله قبلی خود معرفی کردم. افرادی که در معرض هوش مصنوعی قرار میگیرند
عموماً ایده سطح بالایی از نحوه عملکرد یک شبکه عصبی دارند – دادهها از یک لایه شبکه عصبی به لایه بعدی منتقل میشوند و این دادهها از بالاترین لایه به لایه پایین منتشر میشوند
تا اینکه به نحوی ، این الگوریتم پیش بینی تصویری شبیه چیهواهوا یا مافین را به دست می دهد.

به نظر جادویی می رسد، اینطور نیست؟ با کمال تعجب، شبکه های عصبی برای مدل بینایی کامپیوتری را می توان با استفاده از ریاضی دبیرستان درک کرد .
این فقط نیاز به توضیح صحیح به ساده ترین روش دارد تا همه بفهمند که چگونه شبکه های عصبی زیر پوشش کار می کنند. در این مقاله، من از پایگاه داده رقمی دستنویس
MNIST برای توضیح روند ایجاد یک مدل با استفاده از شبکههای عصبی از پایه استفاده خواهم کرد .قبل از غواصی، مهم است که مشخص چراما باید بدانیم که چگونه شبکه های
عصبی زیر پوشش کار می کنند. هر توسعهدهندهی مشتاق یادگیری ماشینی میتواند به سادگی از 10 خط کد  برای تمایز بین سگها و گربهها استفاده کند – پس چرا به خود
برای تمایز بین سگها و گربهها استفاده کند – پس چرا به خود
زحمت یاد گرفتن آنچه در زیر میگذرد، میشود؟
برداشت من این است: بدون درک کامل شبکه های عصبی در یادگیری ماشینی، 1) هرگز نمی توانیم کد مورد نیاز را به طور کامل سفارشی کنیم ، و آن را برای مشکلات مختلف
در دنیای واقعی تطبیق دهیم، و 2) اشکال زدایی یک کابوس خواهد بود. به زبان ساده، یک مبتدی که از یک ابزار پیچیده استفاده میکند بدون اینکه بفهمد این ابزار چگونه کار میکند،
هنوز مبتدی است تا زمانی که به طور کامل بفهمد که بیشتر کارها چگونه کار میکنند.
در این مقاله موارد زیر را پوشش خواهیم داد:
شبکه عصبی: پیش بینی تولید شده توسط کامپیوتر
برای درک کامل این موضوع، باید به جایی برگردیم که اصطلاح “یادگیری ماشین” برای اولین بار رایج شد.

به گفته آرتور ساموئل ، یکی از پیشگامان اولیه هوش مصنوعی، و خالق یکی از اولین برنامه های خودآموز موفق در جهان، او یادگیری ماشین را اینگونه تعریف کرد:
فرض کنید ابزارهای خودکاری برای آزمایش اثربخشی هر تخصیص وزن فعلی از نظر عملکرد واقعی ترتیب می دهیم و مکانیزمی برای تغییر تخصیص وزن به گونه ای ارائه
می دهیم که عملکرد را به حداکثر برسانیم. لازم نیست وارد جزئیات چنین رویهای شویم تا ببینیم که میتوان آن را کاملاً خودکار ساخت و ببینیم که ماشینی که به این ترتیب برنامهریزی شده است از تجربهاش «یاد میگیرد».
از این نقل قول، ما می توانیم 7 مرحله اساسی در یادگیری ماشین را شناسایی کنیم. در چارچوب شناسایی بین هر دو رقم دست نویس “2” یا “9” گرفته شده است:
- وزنه ها را اولیه کنید
- برای هر تصویر، از این وزن ها برای پیش بینی 2 یا 9 بودن آن استفاده کنید.
- از بین همه این پیش بینی ها، دریابید که مدل چقدر خوب است.
- محاسبه گرادیان، که برای هر وزن اندازه گیری می کند، تغییر وزن چگونه کاهش را تغییر می دهد
- همه وزن ها را بر اساس محاسبه تغییر دهید
- به مرحله 2 برگردید و تکرار کنید
- تکرار کنید تا زمانی که تصمیم به توقف بگیرید.
میتوانیم جریان این 7 مرحله را در نمودار زیر تجسم کنیم:

بله، نگاه کردن به این موضوع می تواند کمی طاقت فرسا باشد، زیرا هزاران اصطلاح فنی جدید وجود دارد که ممکن است ناآشنا باشد. وزن ها چیست؟ دوره ها چیست؟
فقط با من همراه باشید، من اینها را به صورت گام به گام در زیر توضیح خواهم داد . این مراحل ممکن است چندان منطقی نباشند، اما فقط محکم بمانید!
fastai.vision.all import *
دوم، بیایید تصاویر را از مجموعه داده MNIST بگیریم . برای این مثال خاص، باید داده ها را از دایرکتوری های آموزشی اعداد دست نویس 2 و 9 بازیابی کنیم.

برای اینکه بفهمیم پوشه حاوی چه چیزی است، میتوانیم از تابع .ls() در fast.ai استفاده کنیم . سپس، ما تصاویر را باز می کنیم تا ببینیم چگونه به نظر می رسد-

همانطور که می بینید، این فقط یک تصویر از عدد دست نویس ‘2’ است!
با این حال، رایانهها نمیتوانند تصاویری را که به آنها منتقل میشود، تشخیص دهند – دادههای موجود در رایانه به عنوان مجموعهای از اعداد نشان داده میشوند. ما می توانیم
آن را در مثال اینجا نشان دهیم:
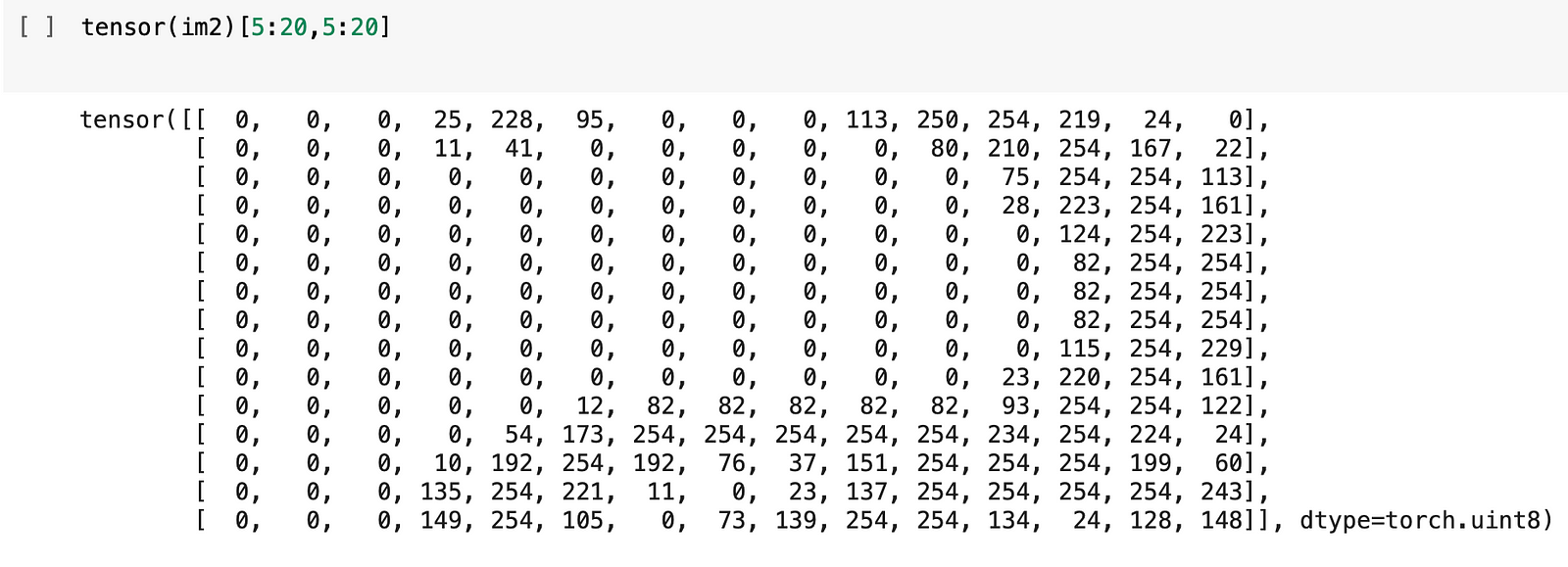
حال، همه این اعداد نشان دهنده چیست؟ بیایید با استفاده از یک تابع مفید که پانداها در اختیار ما قرار می دهند به آن نگاهی بیندازیم:

0 برای سفید و 254 برای سیاه. همانطور که در بالا نشان داده شد، روش اصلی که کامپیوترها تصاویر را تفسیر می کنند، از طریق شکل پیکسل ها است که کوچکترین
بلوک های سازنده هر نمایشگر کامپیوتری هستند . این پیکسل ها به صورت اعداد ثبت می شوند.
اکنون که درک بهتری از نحوه تفسیر واقعی تصاویر توسط رایانه داریم، بیایید به نحوه دستکاری داده ها برای ارائه پیش بینی خود بپردازیم.
ساختارهای داده و مجموعه داده ها
حتی قبل از محاسبه پیشبینیها، باید مطمئن شویم که دادهها به یک شکل ساختار یافتهاند تا برنامه بتواند تمام تصاویر مختلف را پردازش کند. بیایید مطمئن شویم که دو
تانسور متفاوت داریم، هر کدام برای همه «نه» و «دو» در مجموعه داده.

قبل از پیشرفت بیشتر، باید بحث کنیم که تانسور دقیقا چیست . من برای اولین بار کلمه tensor را در نام TensorFlow شنیدم که یک کتابخانه (کاملاً!) مجزا است که ما از آن استفاده
می کنیم. یک PyTorch Tensor در این مورد یک جدول چند بعدی از داده ها است که همه اقلام داده از یک نوع دارند . تفاوت بین لیست ها یا آرایه ها و PyTorch Tensor
در این است که این تانسورها می توانند محاسبات را بسیار (هزاران بار) سریعتر از استفاده از آرایه های پایتون معمولی به پایان برسانند. تجزیه همه دادههایی که بهعنوان دادههای
آموزشی جمعآوری کردهایم به مدل نمیتواند آن را کاهش دهد . فقط به این دلیل که ما به چیزی برای بررسی مدل خود نیاز داریم. ما نمی خواهیم مدل ما به overtrain یا overfit
داده های آموزشی ما، انجام به خوبی در آموزش، تنها به شکست زمانی که آن چیزی است که قبل از آن هرگز دیده می شود، در خارج از داده های آموزشی مواجه است.
بنابراین، ما باید داده ها را به مجموعه داده آموزشی و مجموعه داده اعتبار سنجی تقسیم کنیم .
برای انجام این کار، ما انجام می دهیم:

علاوه بر این، ما باید متغیرهایی ایجاد کنیم – هم متغیرهای مستقل و هم متغیرهای وابسته تا امکان ردیابی چنین دادههایی را فراهم کنیم.
train_x = torch.cat([stacked_twos, stacked_nines]). view(-1, 28*28)
این متغیر train_x همه تصاویر ما را به عنوان متغیرهای مستقل نگه می دارد (یعنی آنچه می خواهیم اندازه گیری کنیم، فکر کنیم: علوم پایه پنجم!).
سپس متغیر وابسته را ایجاد می کنیم و مقدار ‘1’ را برای نشان دادن دو دست نویس اختصاص می دهیم، با مقدار ‘0’ برای نشان دادن 9 های دست نویس در داده ها.
train_y = تانسور([1]*len(دو) + [0]*len(نه)). unsqueeze(1)

سپس یک مجموعه داده بر اساس متغیرهای مستقل و وابسته ایجاد می کنیم و آنها را در یک تاپل، شکلی از لیست های تغییرناپذیر، ترکیب می کنیم.
سپس فرآیند را برای مجموعه داده اعتبار سنجی تکرار می کنیم:

سپس هر دو مجموعه داده را در یک DataLoader با اندازه دسته ای یکسان بارگذاری می کنیم.
اکنون که تنظیمات داده های خود را تکمیل کرده ایم، می توانیم این داده ها را با مدل خود پردازش کنیم.
ایجاد یک مدل خطی لایه
ما تنظیمات داده های خود را تکمیل کرده ایم. با چرخش به هفت مرحله یادگیری ماشینی، اکنون می توانیم به آرامی از آنها عبور کنیم.
مرحله 1: مقدار دهی اولیه وزنه ها
چه وزن ؟ وزن ها متغیر هستند و تخصیص وزن انتخاب خاصی از مقادیر برای آن متغیرها است. می توان به تاکیدی که به هر نقطه داده برای کارکرد برنامه داده می شود فکر کرد.
به عبارت دیگر، تغییر این مجموعه وزن ها، مدل را تغییر می دهد تا برای یک کار متفاوت رفتار متفاوتی داشته باشد.
در اینجا، وزن ها را به طور تصادفی برای هر پیکسل مقداردهی اولیه می کنیم –
لطفاً، بررسی کنید که آیا چیزی از اینجا گم شده است -؟
چیزی وجود داشت که مرا آزار می داد . آیا راه بهتری برای مقداردهی اولیه وزن ها در مقایسه با ریختن یک عدد تصادفی وجود داشت؟
به نظر می رسد که مقداردهی اولیه تصادفی در شبکه های عصبی یک ویژگی خاص است، نه یک اشتباه . در این مورد، الگوریتمهای بهینهسازی تصادفی
(که در زیر توضیح داده خواهد شد) از تصادفی بودن در انتخاب نقطه شروع در جستجو قبل از پیشرفت در جستجو استفاده میکنند.
مرحله ۲: پیشبینیها – برای هر تصویر، پیشبینی کنید که آیا این ۲ یا ۹ است.
سپس می توانیم پیش برویم و اولین پیش بینی خود را محاسبه کنیم:

به دنبال آن، پیشبینیهای بقیه دادهها را با استفاده از مینی دستهها محاسبه میکنیم :

 این مرحله است دلیل داشتن قابلیت محاسبه پیش بینی ها بسیار مهم و یکی از دو معادله اساسی هر شبکه عصبی است.
این مرحله است دلیل داشتن قابلیت محاسبه پیش بینی ها بسیار مهم و یکی از دو معادله اساسی هر شبکه عصبی است.
مرحله 3: استفاده از تابع ضرر برای درک اینکه مدل ما چقدر خوب است
برای اینکه بفهمیم مدل چقدر خوب است، باید از یک تابع ضرر استفاده کنیم . این بند «آزمایش اثربخشی هر تخصیص وزن فعلی از نظر عملکرد واقعی» است و پیشفرض این است
که چگونه مدل وزنهای خود را برای پیشبینی بهتر بهروزرسانی میکند.
به یک تابع ضرر اساسی فکر کنید. ما نمیتوانیم از دقت بهعنوان تابع از دست دادن استفاده کنیم، زیرا دقت تنها در صورتی تغییر میکند که پیشبینیهای «2» یا «9» بودن یک تصویر
بهطور کامل تغییر کند – از این نظر، دقت بهروزرسانیهای کوچک را نمیگیرد. اطمینان یا اطمینانی که مدل با آن نتایج را پیش بینی می کند.
با این حال، کاری که میتوانیم انجام دهیم این است که تابعی ایجاد کنیم که تفاوت بین پیشبینیهایی را که مدل ارائه میکند ثبت کند (به عنوان مثال – برای یک پیشبینی
نسبتاً مشخص 0.2 میدهد که تصویری که تفسیر میکند نزدیکتر به 2 است نه 9). و برچسب واقعی مرتبط با آن (در این مورد، 0 خواهد بود، بنابراین تفاوت خام، ضرر
بین پیش بینی و مدل 0.2 خواهد بود).اما صبر کنید! همانطور که شما می توانید از خروجی را مشاهده کنید. همه پیش بینی های W بیمار دروغ در محدوده بین 0 و 1،
برخی از آنها ممکن است دور. آنچه ما می خواهیم تابع دیگری است که می تواند مقادیر بین 0 و 1 را به هم بزند.
خوب، یک عملکرد مفید برای این وجود دارد – آن تابع Sigmoid نام دارد . این یک تابع ریاضی است که با (1/ 1+e^(-x)) داده می شود که شامل همه اعداد مثبت و منفی بین 0 و 1 است.
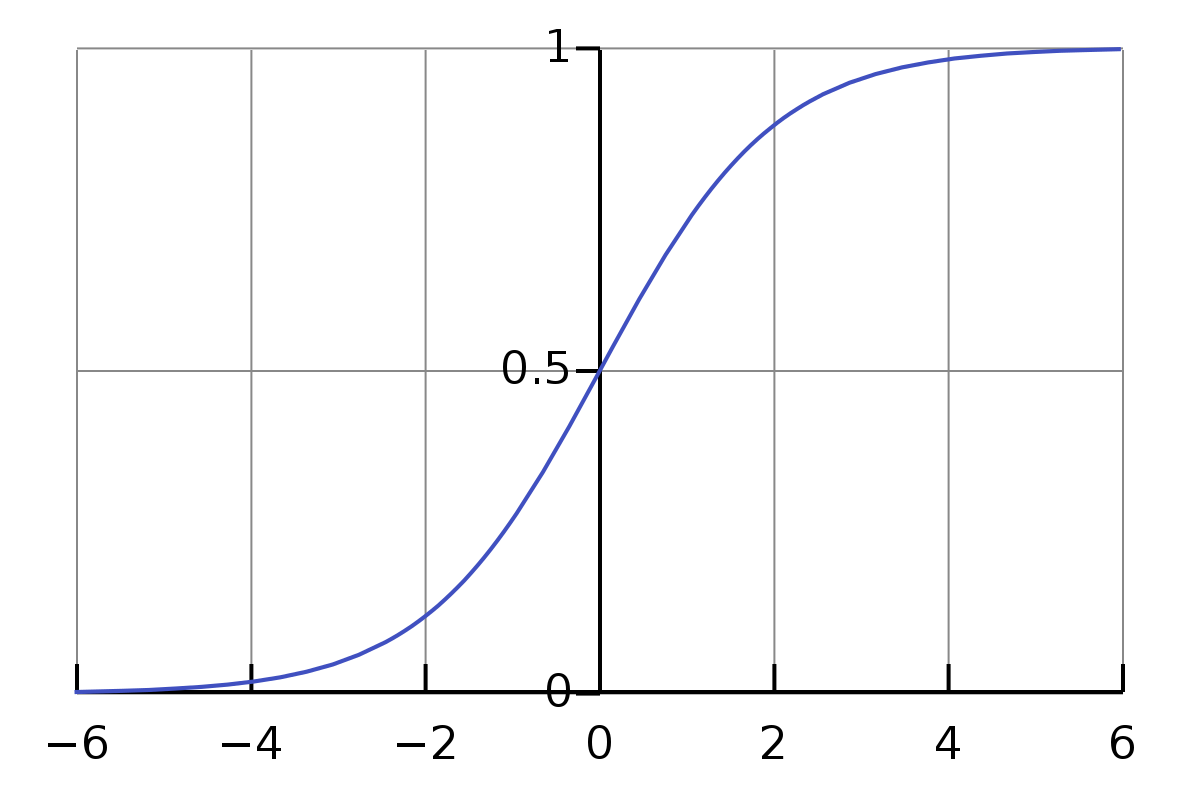
اکنون، ممکن است تصور اشتباهی وجود داشته باشد که برخی افراد هنگام یادگیری یادگیری ماشینی از طریق ویدیوهای مقدماتی دارند . من مطمئناً برخی
از آنها را داشتم. اگر به صورت آنلاین در گوگل جستجو می کنید، تابع Sigmoid عموماً مورد انتقاد قرار می گیرد. اما مهم است که قبل از انتقاد از تابع Sigmoid در
چه زمینه ای استفاده می شود. در این مورد، صرفاً به عنوان راهی برای فشرده سازی اعداد بین 0 و 1 برای تابع ضرر استفاده می شود. ما از Sigmoid به عنوان
یک تابع فعال سازی استفاده نمی کنیم، که بعداً مورد بحث قرار خواهد گرفت.
بنابراین می توانیم ضرر را برای مینی بچ خود محاسبه کنیم :

مرحله 4: محاسبه گرادیان – اصل نزول گرادیان تصادفیاز آنجایی که ممکن است با هر وزن معین (وزن تصادفی) شروع کنیم، هدف مدل یادگیری ماشین رسیدن به کمترین ضرر ممکن در محدوده آموزشی مدل است.
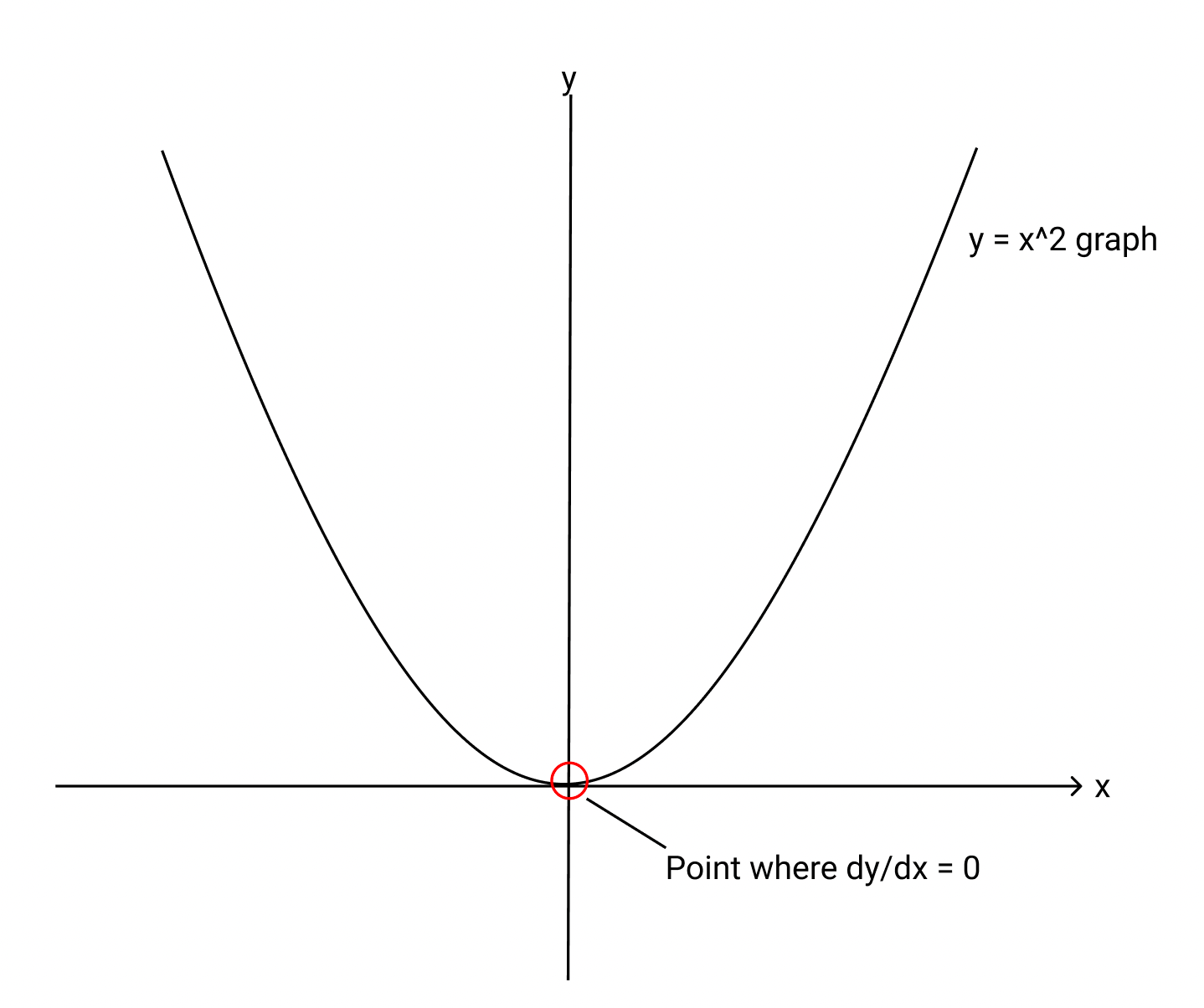
این ممکن است پیچیده به نظر برسد، اما برای درک خوب این مفهوم فقط به ریاضی دبیرستان نیاز دارد. تصور کنید که تابع ضرر ما یک تابع درجه دوم دلخواه y = x² است و میخواهیم
این تابع ضرر را به حداقل برسانیم. ما بلافاصله به نقطه ای فکر می کنیم که مشتق یا گرادیان این تابع صفر است، که اتفاقاً در پایین ترین نقطه (یا “دره”) است. رسم خطی
مماس بر منحنی در آن نقطه به ما یک خط مستقیم می دهد. ما می خواهیم برنامه به طور مداوم خود را به روز کند تا به آن حداقل برسد.
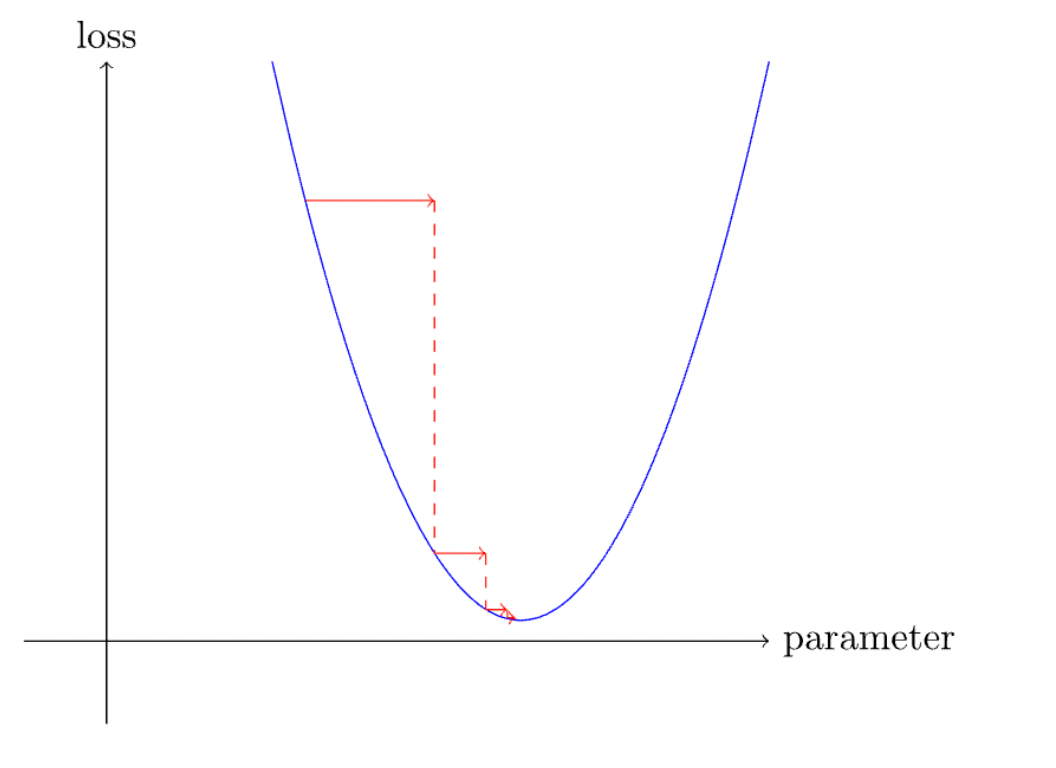
این یکی از راههای اصلی کاهش ضرر در یادگیری ماشینی است و یک نمای کلی از چگونگی سرعت بخشیدن سریع به آموزش مدلها ارائه میکند.
برای محاسبه گرادیان ها (نه، ما مجبور نیستیم این کار را به صورت دستی انجام دهیم، بنابراین نیازی نیست یادداشت های ریاضی دبیرستان خود را بیرون بیاورید)، تابع زیر را می نویسیم:
مرحله 5: تغییر وزن ها بر اساس گرادیان محاسبه شده (بالا بردن وزن ها)
اکنون، برای سادگی، همه توابع دیگر (اعتبارسنجی، دقت) را که نوشتهایم در توابع سطح بالاتر ادغام میکنیم و دستههای مختلف را با هم میچینیم:
مرحله 6: از مرحله 2 تکرار کنید

آری ما بهتازگی یک شبکه خطی (یک لایه) ساختهایم که میتواند در مدت زمان بسیار کوتاهی با دقت بسیار بالایی آموزش ببیند.
برای بهینه سازی این فرآیند و کاهش تعداد توابع سطح پایین (و البته برای اینکه کد ما کمی زیباتر به نظر برسد) – از توابع از پیش ساخته شده (مثلا کلاسی به نام Learner ) استفاده می کنیم که عملکردی مشابه با خطوط کد قبل
ایجاد چندین لایه با استفاده از تابع فعال سازی
چگونه از یک برنامه لایه ای خطی به یکی از لایه های چندگانه پیشرفت کنیم؟ کلید در یک خط کد ساده نهفته است –
به طور خاص، این تابع res.max همچنین به عنوان یک واحد خطی اصلاحشده (ReLU) شناخته میشود ، که روشی فانتزی برای گفتن «تمام اعداد منفی را به صفر تبدیل کنید و اعداد مثبت را همانطور که هستند بگذارید» است. این یکی از این تابعهای فعالسازی است، در حالی که بسیاری دیگر در آنجا وجود دارند – مانند Leaky ReLU، Sigmoid (که به طور خاص به عنوان یک تابع فعالسازی استفاده میشود )، tanh و غیره.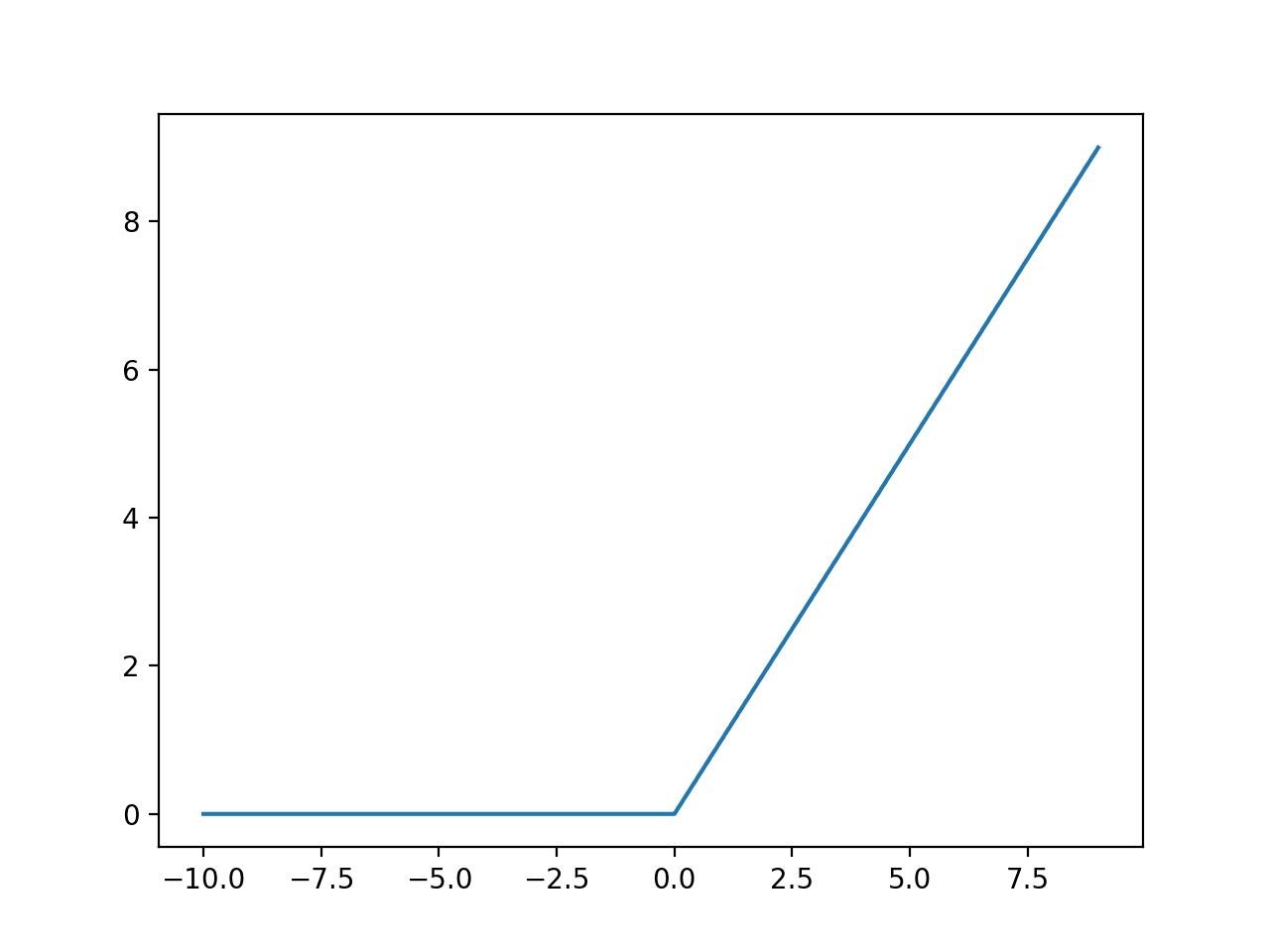
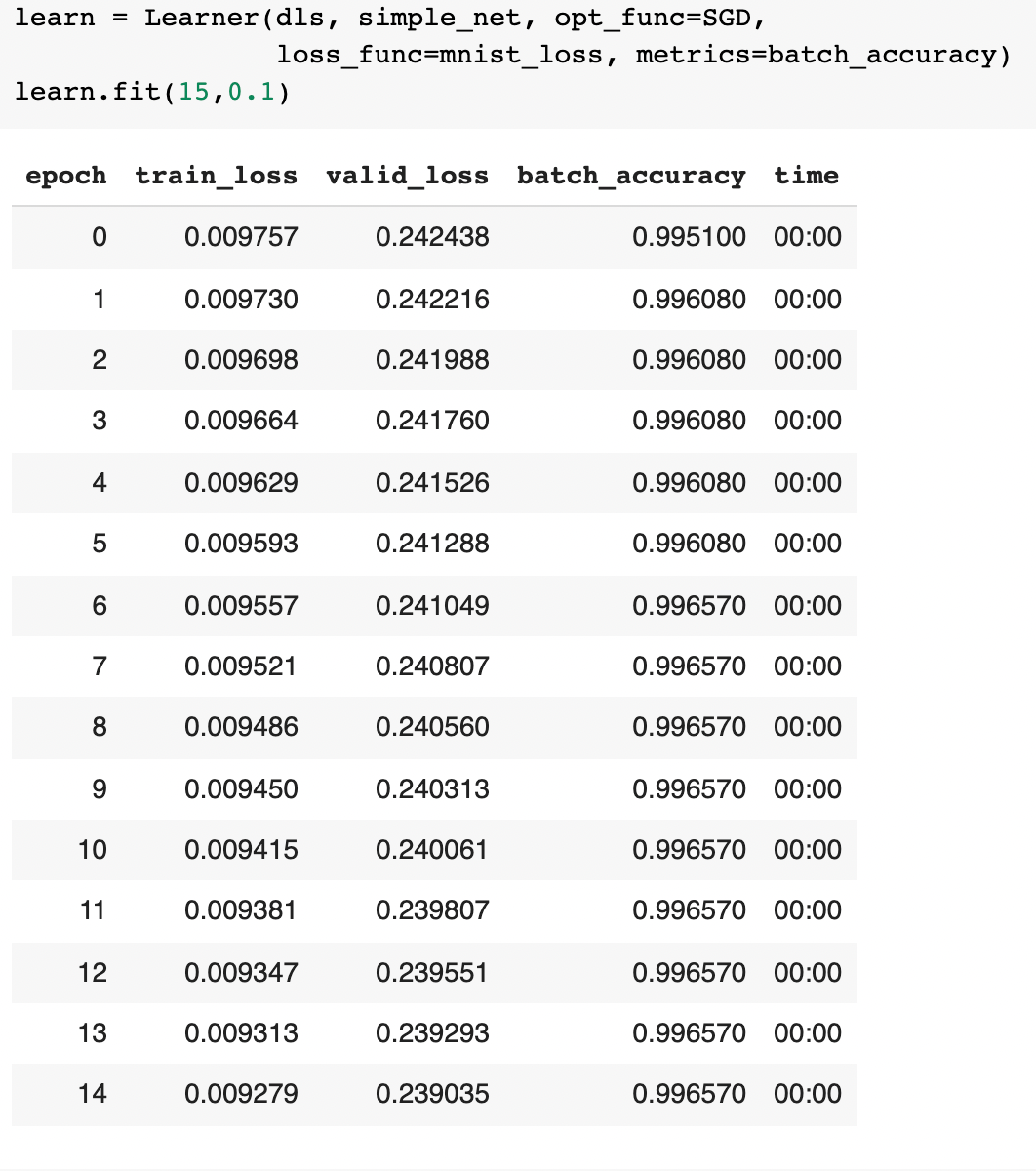
جالبتر این است که ما حتی میتوانیم ببینیم که مدل در لایههای مختلف این معماری ساده، چه تصاویری را پردازش میکند!

نتیجه
درک آنچه در داخل یک شبکه عصبی مصنوعی می رود ممکن است در ابتدا دلهره آور به نظر برسد. شبکههای عصبی کلید سفارشیسازی و درک اینکه کدام بخشهای مدل
دچار اشتباه شدهاند. اگر مجبور به ساخت یک مدل از ابتدا باشیم، هستند. آنچه که لازم است فقط عزم راسخ، یک کامپیوتر کارآمد، و کمی درک بسیار ابتدایی از مفاهیم ریاضی
دبیرستان برای فرو رفتن عمیق در هوش مصنوعی است.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

دیدگاهتان را بنویسید