
کاربرد هوش مصنوعی ، یادگیری ماشین و یادگیری عمیق(بخش اول)
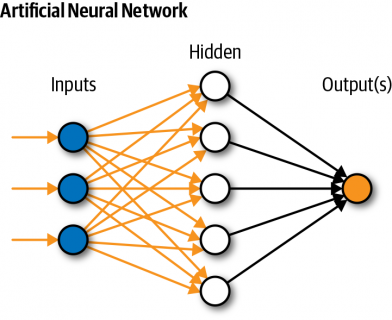
کاربرد هوش مصنوعی ، یادگیری ماشین و یادگیری عمیق
بخش 1:
همه ما درباره امکانات هوش مصنوعی ، یادگیری ماشین و یادگیری عمیق شنیده ایم. موقعیت های زیادی وجود داشته است که در آن هوش مصنوعی تأثیر قابل اندازه گیری بر یک سازمان داشته است.
و همچنین موقعیت هایی وجود داشته است که سازمان ها میلیون ها دلار در فناوری های به ظاهر نوآورانه بدون خروجی مستقیم هدر داده اند.
بنابراین کارکرد بین یادگیری ماشین ، یادگیری عمیق و هوش مصنوعی چیست و چگونه می توانند به نفع سازمان شما باشند؟
هوش مصنوعی (AI) چیست؟
هوش مصنوعی (AI) علمی است که ماشین هارا به تفکر و عمل مانند انسان وادار میکند..این ممکن است ساده به نظر برسد ، اما هیچ رایانه ای در حال حاضر با پیچیدگی های هوش انسانی مطابقت ندارد.
رایانه ها در اعمال قوانین و اجرای وظایف برتری دارند ، اما گاهی اوقات یک “اقدام” نسبتاً ساده برای یک شخص ممکن است برای کامپیوتر بسیار پیچیده باشد.
به عنوان مثال ، حمل یک سینی نوشیدنی از طریق یک کافه شلوغ و ارائه آن به مشتری مناسب کاری است که کارگران سرویس دهنده هر روز انجام می دهند ، اما این یک تمرین پیچیده در تصمیم گیری است .
و بر اساس حجم بالای داده های منتقل شده بین نورون ها در انسان انجام می شود. مغزرایا نه هنوز قادر به اینکار نیست ، اما یادگیری ماشینی و یادگیری عمیق گام هایی در جهت دستیابی به عنصر کلیدی این هدف برداشته اند..
هوش مصنوعی نظریه و توسعه سیستم های رایا نه ای است که قادر به انجام وظایفی است که معمولاً به هوش انسان نیاز دارند ، مانند درک بصری ، تشخیص گفتار ، تصمیم گیری و ترجمه بین زبان ها.
به طور خلاصه: هوش مصنوعی هر برنامه کامپیوتری است که کاری هوشمند انجام می دهد.
در هوش مصنوعی ، ماشین ها عملکردهای شناختی را که با ذهن انسان مرتبط هستند ، مانند “یادگیری” و “حل مسئله” تقلید می کنند.
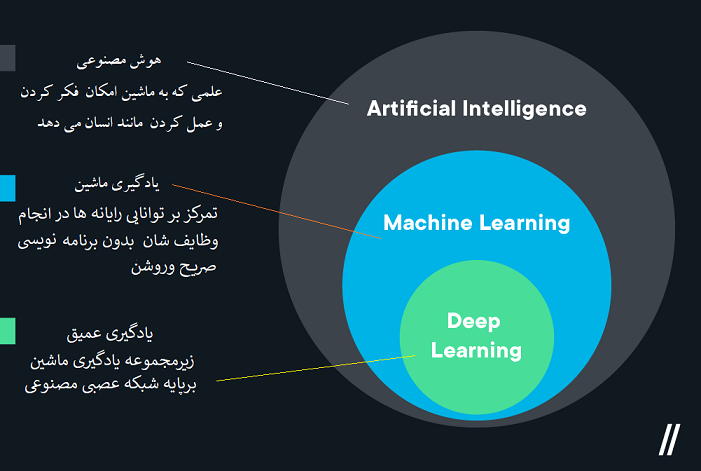
یادگیری ماشین چیست؟
یادگیری ماشین زیرمجموعه ای از هوش مصنوعی است که بر یک هدف خاص تمرکز می کند: تنظیم رایانه ها برای انجام وظایف بدون نیاز به برنامه نویسی صریح.
رایانه ها از داده های ساختار یافته تغذیه می کنند (در بیشتر موارد) و یاد می گیرند که در ارزیابی و عمل به آن داده ها در طول زمان بهتر عمل کنند.
“داده های ساختار یافته” را به عنوان ورودی های داده ای که می توانید در ستون ها و سطرها قرار دهید ، تصور کنید. ممکن است یک ستون دسته بندی در Excel به نام “غذا” ایجاد کنید.
و ردیف هایی مانند “میوه” یا “گوشت” داشته باشید. کار با این شکل از داده های “ساختار یافته” برای رایانه ها بسیار آسان است.
و مزایای آن آشکار است (تصادفی نیست که یکی از مهمترین زبانهای برنامه نویسی داده “زبان پرس و جو ساختار یافته” نامیده می شود).
پس از برنامه ریزی ، رایانه می تواند داده های جدید را به طور نامحدود دریافت کند ، بدون نیاز به دخالت بیشتر انسان ها مرتب شده و بر اساس آنها عمل کند.
با گذشت زمان ، رایانه ممکن است تشخیص دهد که “میوه” یک نوع غذا است حتی اگر برچسب گذاری اطلاعات خود را متوقف کنید.
این “خوداتکایی” برای یادگیری ماشینی بسیار اساسی است به طوری که این حوزه بر اساس میزان کمک مداوم بشر در زیر مجموعه ها تجزیه می شود.
یادگیری تحت نظارت و یادگیری نیمه تحت نظارت :
یادگیری تحت نظارت زیرمجموعه ای از یادگیری ماشینی است که مستلزم مداوم ترین مشارکت انسانی است – از این رو نام آن “تحت نظارت” است.
کامپیوتر از داده های آموزشی تغذیه می کند و مدلی به طور صریح طراحی شده است تا نحوه پاسخ به داده ها را به او آموزش دهد.
پس از استقرار مدل ، داده های بیشتری را می توان در رایانه وارد کرد تا ببیند چقدر خوب پاسخ می دهد – و برنامه نویس/دانشمند داده می تواند پیش بینی های دقیق را تأیید کند.
یا می تواند برای هرگونه پاسخ نادرست تصحیح کند. تصویری از یک برنامه نویس که سعی می کند طبقه بندی تصاویر کامپیوتر را آموزش دهد. آنها تصاویر را وارد می کردند.
و کامپیوتر را برای طبقه بندی هر تصویر ، تأیید یا تصحیح هر خروجی کامپیوتر ، وظیفه می کردند.
با گذشت زمان ، این سطح نظارت به مدل کمک می کند تا بتواند مجموعه داده های جدیدی را که از الگوهای “آموخته شده” پیروی می کنند ، دقیقا اداره کند. اما نظارت بر عملکرد رایانه و انجام تنظیمات کارآمد نیست.
در یادگیری نیمه تحت نظارت ، رایانه از مخلوطی از داده های دارای برچسب درست و داده های بدون برچسب تغذیه می شود و الگوها را به تنهایی جستجو می کند.
داده های برچسب خورده به عنوان “راهنمای” برنامه نویس عمل می کند ، اما آنها اصلاحات مداوم را صادر نمی کنند.
امروزه یادگیری ماشینی برای چه چیزی استفاده می شود؟
شاید تعجب کنید که متوجه شدید هر روز با ابزارهای یادگیری ماشین تعامل دارید. Google از آن برای فیلتر کردن هرزنامه ها ، بدافزارها و ایمیل های فیشینگ از صندوق ورودی شما استفاده می کند.
بانک و کارت اعتباری شما از آن برای ایجاد هشدار در مورد معاملات مشکوک در حساب های شما استفاده می کنند. وقتی با Siri و Alexa صحبت می کنید .
یادگیری ماشینی بسترهای تشخیص صدا و گفتار را در محل کار پیش می برد. و وقتی پزشک شما را به متخصص می فرستد ، یادگیری ماشینی ممکن است به آنها در اسکن اشعه ایکس
و نتایج آزمایش خون برای ناهنجاری هایی مانند سرطان کمک کند.
با پیشرفت برنامه های کاربردی ، مردم برای یادگیری ماشینی به کار می گیرند تا انواع پیچیده تری از داده ها را اداره کنند. تقاضای زیادی برای رایانه هایی وجود دارد .
که بتوانند داده های بدون ساختار مانند تصاویر یا فیلم را مدیریت کنند. و اینجاست که یادگیری عمیق وارد تصویر می شود.
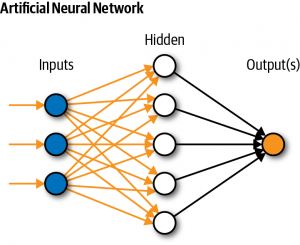
یادگیری ماشین در پایتون:
در این بخش ، ما قصد داریم یک پروژه یادگیری ماشین کوچک را انجام بدهیم.
مراحل مورد نیاز اجرای برنامه به شرح زیر است:
5 کتابخانه کلیدی وجود دارد که باید آنها را نصب کنید. در زیر لیستی از کتابخانه های Python SciPy مورد نیاز برای این آموزش آمده است:
scipy
numpy
matplotlib
pandas
sklearn
اول ، اجازه دهید همه ماژول ها را وارد کنیم
# Load libraries from pandas import read_csv from pandas.plotting import scatter_matrix from matplotlib import pyplot from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC ...
بارگیری مجموعه داده:
همه چیز باید بدون خطا بارگیری شود. اگر خطایی دارید ، متوقف شوید.
ما می توانیم داده ها را مستقیماً از مخزن یادگیری ماشین UCI بارگذاری کنیم.
ما از پانداها برای بارگیری داده ها استفاده می کنیم. ما همچنین از پانداهای بعدی برای کشف داده ها با آمار توصیفی و تجسم داده ها استفاده خواهیم کرد.
توجه داشته باشید که هنگام بارگذاری داده ها ، نام هر ستون را مشخص می کنیم. این بعداً وقتی داده ها را کاوش می کنیم کمک می کند.
... # Load dataset url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv" names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] dataset = read_csv(url, names=names)
مجموعه داده باید بدون مشکل بارگیری شود.
اگر مشکلی در شبکه دارید ، می توانید فایل iris.csv را در فهرست کار خود بارگیری کرده و با استفاده از همان روش بارگذاری کنید ، URL را به نام فایل محلی تغییر دهید
همچنین همیشه ایده خوبی است که داده های خود را به دقت بررسی کنید.
ابعاد مجموعه داده :
... # head print(dataset.head(20))
شما باید 20 ردیف اول داده ها را مشاهده کنید:
sepal-length sepal-width petal-length petal-width class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa 5 5.4 3.9 1.7 0.4 Iris-setosa 6 4.6 3.4 1.4 0.3 Iris-setosa 7 5.0 3.4 1.5 0.2 Iris-setosa 8 4.4 2.9 1.4 0.2 Iris-setosa 9 4.9 3.1 1.5 0.1 Iris-setosa 10 5.4 3.7 1.5 0.2 Iris-setosa 11 4.8 3.4 1.6 0.2 Iris-setosa 12 4.8 3.0 1.4 0.1 Iris-setosa 13 4.3 3.0 1.1 0.1 Iris-setosa 14 5.8 4.0 1.2 0.2 Iris-setosa 15 5.7 4.4 1.5 0.4 Iris-setosa 16 5.4 3.9 1.3 0.4 Iris-setosa 17 5.1 3.5 1.4 0.3 Iris-setosa 18 5.7 3.8 1.7 0.3 Iris-setosa 19 5.1 3.8 1.5 0.3 Iris-setosa
خلاصه آماری :
اکنون می توانیم به خلاصه ای از هر ویژگی نگاهی بیندازیم.
این شامل شمارش ، میانگین ، حداقل و حداکثر و همچنین چند صدک است.
... # descriptions print(dataset.describe())
می بینیم که همه مقادیر عددی دارای مقیاس یکسان (سانتیمتر) و محدوده مشابه بین 0 تا 8 سانتیمتر هستند.
sepal-length sepal-width petal-length petal-width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
کلاس بندی :
اکنون بیایید نگاهی به تعداد موارد (ردیف) مربوط به هر کلاس بیندازیم. ما می توانیم این را به عنوان یک عدد مطلق در نظر بگیریم.
...
# class distribution
print(dataset.groupby('class').size())
ما می توانیم ببینیم که هر کلاس تعداد نمونه های یکسانی (50 یا 33 of از مجموعه داده) دارد.
class Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50
مثال کامل در زیر ذکر شده است.:
# summarize the data
from pandas import read_csv
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# shape
print(dataset.shape)
# head
print(dataset.head(20))
# descriptions
print(dataset.describe())
# class distribution
print(dataset.groupby('class').size())
پایان قسمت 1
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید