
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی
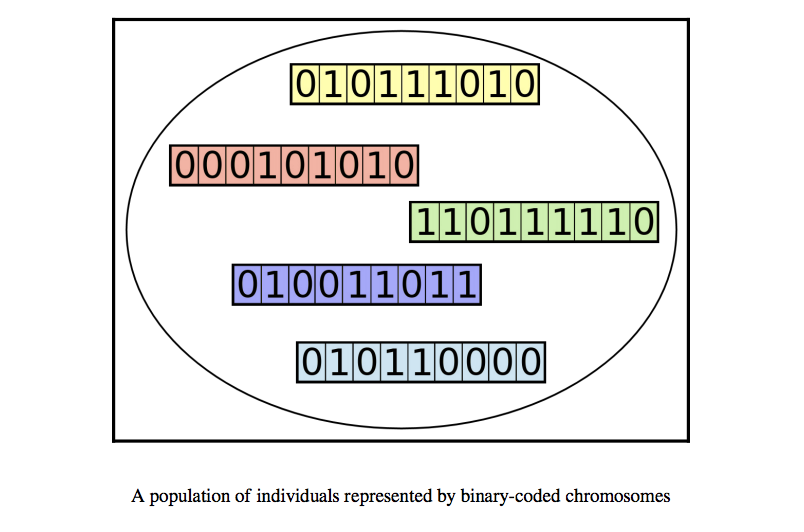
الگوریتم ژنتیک چیست؟
الگوریتم های ژنتیک الگوریتم های جستجویی هستند که از نظریه تکامل داروین در طبیعت الهام گرفته شده اند.
-
با شبیه سازی فرآیند انتخاب طبیعی، تولید مثل و جهش، الگوریتم های ژنتیک می توانند راه حل هایی با کیفیت بالا برای مسائل مختلف از جمله جستجو و بهینه سازی تولید کنند.
-
با استفاده موثر از نظریه تکامل، الگوریتم های ژنتیک قادر به غلبه بر مشکلات الگوریتم های سنتی هستند.
طبق نظریه تکامل داروین، یک تکامل جمعیتی از افراد را حفظ می کند که از یکدیگر متفاوت هستند (تغییر). کسانی که با محیط خود سازگاری بهتری دارند، شانس بیشتری برای زنده ماندن، تولید مثل و انتقال صفات خود به نسل بعدی (بقای بهترین ها) دارند.
الگوریتم های ژنتیک چگونه کار می کنند؟
قبل از ورود به کار الگوریتم ژنتیک، اجازه دهید به اصطلاحات اولیه الگوریتم ژنتیک بپردازیم.
کروموزوم/فرد
کروموزوم مجموعه ای از ژن هاست. به عنوان مثال، یک کروموزوم را می توان به عنوان یک رشته دوتایی نشان داد که در آن هر بیت یک ژن است.
جمعیت
از آنجایی که یک فرد به عنوان یک کروموزوم نشان داده می شود، جمعیت مجموعه ای از این کروموزوم ها است.
عملکرد تابع برازندگی (Fitness Function)
افرادی که به نمره برازندگی بهتری دست می یابند، راه حل های بهتری را نشان می دهند و احتمال بیشتری دارد که متقاطع انتخاب شوند و به نسل بعدی منتقل شوند.
انتخاب
انواع روش های انتخاب موجود :
- انتخاب چرخ رولت
- انتخابی مسابقات
- انتخاب بر اساس رتبه
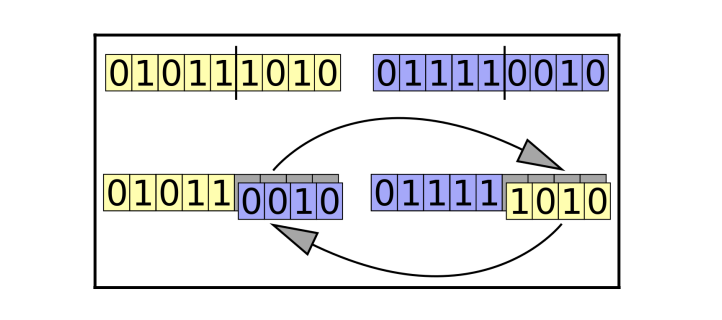
متقاطع
به طور کلی، دو فرد از نسل فعلی انتخاب می شوند و ژن های آنها بین دو فرد مبادله می شود تا یک فرد جدید به نمایندگی از فرزندان ایجاد شود. این فرآیند جفت گیری یا متقاطع نیز نامیده می شود.
انواع روش های متقاطع موجود :
- کراس اوور یک نقطه
- کراس اوور دو نقطه ای
- کراس اوور یکنواخت
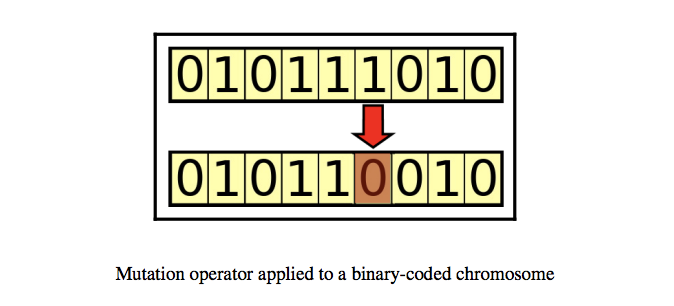
جهش
جهش یک تغییر تصادفی در یک کروموزوم برای معرفی الگوهای جدید به یک کروموزوم است. به عنوان مثال، ورق زدن کمی در یک رشته باینری.
- جهش بیت فلیپ
- جهش گاوسی
- تعویض جهش
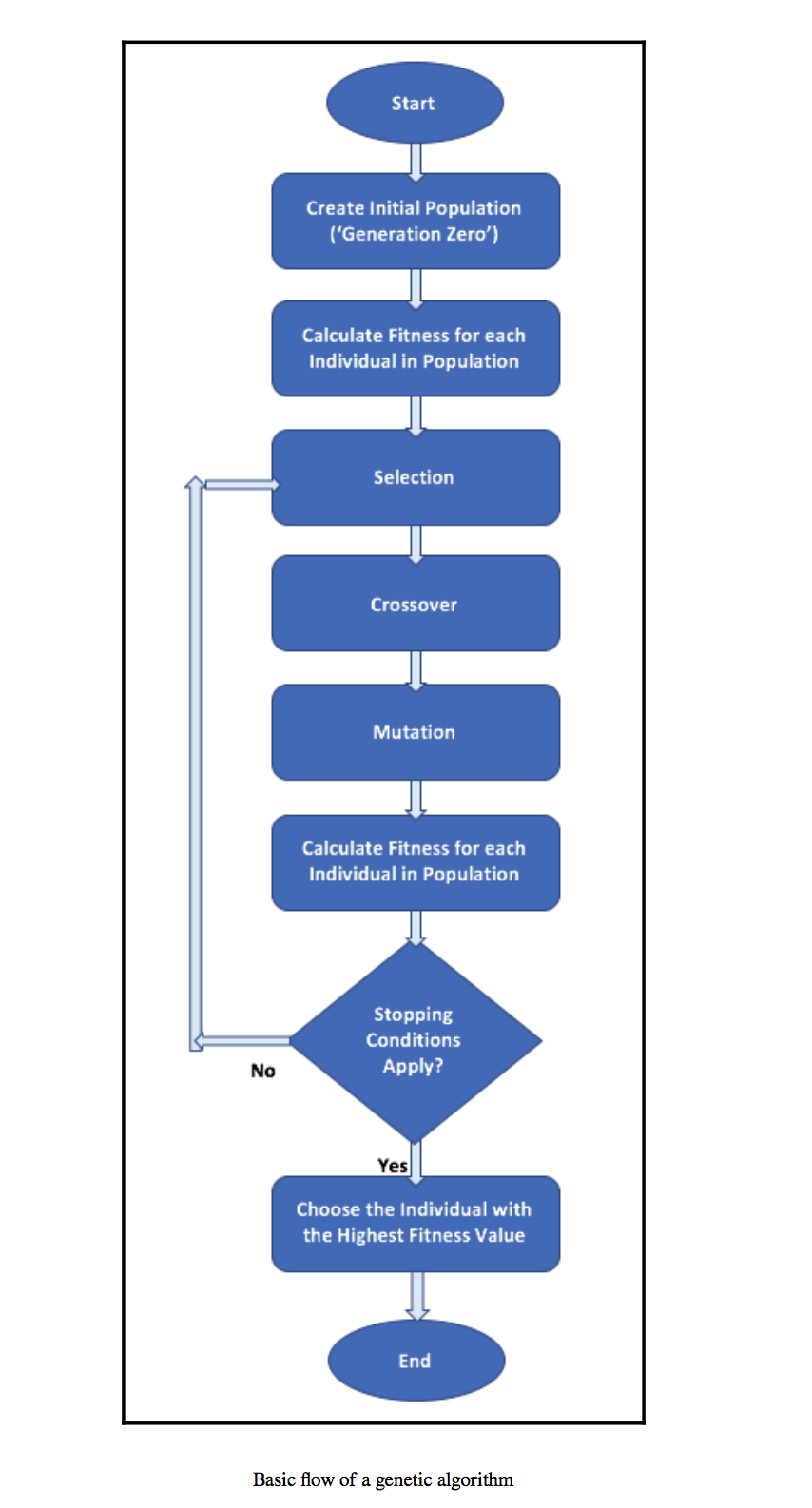
گردش کار کلی یک الگوریتم ژنتیک ساده
الگوریتم های ژنتیک چه تفاوتی با الگوریتم های سنتی دارند؟
-
فضای جستجو مجموعه ای از تمام راه حل های ممکن برای مشکل است. الگوریتمهای سنتی تنها یک مجموعه را در فضای جستجو حفظ میکنند در حالی که الگوریتمهای ژنتیک از چندین مجموعه در یک فضای جستجو استفاده میکنند (انتخاب ویژگی با استفاده از RFE در مقابل الگوریتمهای ژنتیک).
-
الگوریتم های سنتی برای انجام جستجو به اطلاعات بیشتری نیاز دارند در حالی که الگوریتم های ژنتیک فقط به یک تابع هدف برای محاسبه تناسب یک فرد نیاز دارند.
-
الگوریتم های سنتی نمی توانند به صورت موازی کار کنند در حالی که الگوریتم های ژنتیک می توانند به صورت موازی کار کنند (محاسبه تناسب اندام افراد مستقل است).
-
یکی از تفاوتهای بزرگ در الگوریتمهای ژنتیک این است که الگوریتمهای ژنتیک بهجای اینکه مستقیماً روی راهحلهای کاندید عمل کنند، بر روی بازنمایی (یا کدگذاری) خود عمل میکنند که اغلب به آنها کروموزوم گفته میشود.
-
الگوریتمهای سنتی در نهایت تنها میتوانند یک راهحل تولید کنند در حالی که در الگوریتمهای ژنتیک میتوان چندین راهحل بهینه را از نسلهای مختلف بهدست آورد.
-
الگوریتمهای سنتی احتمال بیشتری برای تولید راهحلهای بهینه جهانی ندارند، الگوریتمهای ژنتیک تضمینی برای تولید راهحلهای بهینه جهانی نیز ندارند، اما به دلیل وجود عملگرهای ژنتیکی مانند متقاطع و جهش، احتمال بیشتری برای تولید راهحلهای بهینه جهانی دارند.
-
الگوریتم های سنتی ماهیت قطعی دارند در حالی که الگوریتم های ژنتیک ماهیت احتمالی و تصادفی دارند.
-
مسائل دنیای واقعی چند وجهی هستند (شامل چندین راه حل بهینه محلی)، الگوریتم های سنتی به خوبی با این مسائل برخورد نمی کنند، در حالی که الگوریتم های ژنتیک، با تنظیم پارامتر مناسب، به دلیل فضای راه حل بزرگ، می توانند این مسائل را به خوبی مدیریت کنند.
مزایای الگوریتم ژنتیک
-
موازی سازی
-
بهینه سازی جهانی
-
مجموعه ای بزرگتر از فضای راه حل
-
به اطلاعات کمتری نیاز دارد
-
چندین راه حل بهینه ارائه می دهد
-
ماهیت احتمالی
-
نمایش ژنتیکی با استفاده از کروموزوم ها
معایب الگوریتم ژنتیک
-
نیاز به تعاریف خاص
-
تنظیم فراپارامتر
-
پیچیدگی محاسباتی
موارد استفاده از الگوریتم های ژنتیک در یادگیری ماشینی
-
انتخاب ویژگی
-
تنظیم مدل Hyper-Parameter
-
بهینه سازی خط لوله یادگیری ماشین
TPOT (بهینه سازی خط لوله مبتنی بر درخت) یک چارچوب Auto-ML است که از الگوریتم های ژنتیک برای بهینه سازی خطوط لوله یادگیری ماشین با استفاده از چارچوب الگوریتم ژنتیک به نام DEAP (الگوریتم های تکاملی توزیع شده در پایتون) استفاده می کند.
انتخاب ویژگی با استفاده از الگوریتم ژنتیک
با استفاده از الگوریتم ژنتیک، اجازه دهید انتخاب ویژگی را روی مجموعه داده موجود در sklearn انجام دهیم.
import random
import pandas as pd
from sklearn.base import clone
from deap.algorithms import eaSimple
from deap import base, creator, tools
from sklearn.datasets import load_wine
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
data = load_wine()
features = pd.DataFrame(
data.data, columns=data.feature_names
)
target = pd.Series(data.target)
# split the data into train and test
x_train, x_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, stratify=target
)
model = RandomForestClassifier()
داده ها را به ویژگی ها و هدف تقسیم کنید و سپس ویژگی ها و هدف را برای آموزش و آزمایش تقسیم کنید.
def compute_fitness_score(individual):
"""
Select the features from the individual, train
and compute the accuracy_score.
Example:
individual = [0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1]
The 1 represents the presence of features and
0 represents the absence of features
"""
column_support = pd.Series(individual).astype(bool)
global x_train, y_train, x_test, y_test, model
x_train_ = x_train[x_train.columns[column_support]]
x_test_ = x_test[x_test.columns[column_support]]
model.fit(x_train_, y_train)
y_pred = model.predict(x_test_)
score = accuracy_score(y_test, y_pred)
return score,
نمره برازندگی را تعریف کنید. compute_fitness_score یک فرد را به عنوان ورودی می گیرد، برای مثال، اجازه دهید فرد زیر را در نظر بگیریم [0، 1، 1، 1، 0، 0، 1، 1، 0، 0، 1، 1، 1]، در این لیست 1 نشان دهنده وجود آن ویژگی خاص و 0 نشان دهنده عدم وجود آن ویژگی است. ستون ها بر حسب فرد انتخاب می شوند و سپس مدل برازش می شود و امتیاز دقت محاسبه می شود. این امتیاز دقت، امتیاز برازندگی یک فرد است.
n_genes = x_train.shape[1]
n_generations = 10
n_population = 10
crossover_probability = 0.6
mutation_probability = 0.2
def setup_toolbox():
# container for individuals
creator.create('FitnessMax', base.Fitness, weights=(1.0,))
creator.create('Individual', list, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register(
'individual_generator_function',
random.randint, 0, 1
)
# method to populate individual
toolbox.register(
'individual_generator',
tools.initRepeat,
creator.Individual,
toolbox.individual_generator_function,
n_genes
)
# method to create population
toolbox.register(
'population_generator',
tools.initRepeat,
list,
toolbox.individual_generator
)
# fitness calculation
toolbox.register(
'evaluate', compute_fitness_score
)
# selection
toolbox.register(
'select', tools.selTournament, tournsize=3
)
# crossover
toolbox.register('mate', tools.cxOnePoint)
# mutation
toolbox.register(
'mutate',
tools.mutFlipBit,
indpb=mutation_probability
)
return toolbox
n_genes تعداد ژنهای یک فرد را نشان میدهد که برابر با تعداد ویژگیها است، n_generations نشاندهنده تعداد نسلهایی است که برابر با 10 است و همچنین n_population نشاندهنده تعداد جمعیت است. احتمال متقاطع روی 0.6 و احتمال جهش روی 0.2 تنظیم شده است.
جعبه ابزار یک کلاس در چارچوب عمیق است که ابزارهای مورد نیاز را برای تعریف فرد، جمعیت و بسیاری موارد دیگر در اختیار ما قرار می دهد.
مراحل انجام شده در روش setup_toolbox عبارتند از
- ابتدا فردی را تعریف می کنیم که دارای امتیاز تناسب اندام باشد
- در مرحله بعد، تابعی را تعریف می کنیم که ژن های یک فرد را تولید می کند، در مورد ما 0 یا 1 در یک فرد
- ما تابعی را تعریف می کنیم که افراد یک جمعیت را تولید می کند، به عنوان مثال، [0، 1، 1، 1، 0، 0، 1، 1، 0، 0، 1، 1، 1] یک فرد در یک جمعیت است.
- سپس، تابعی را تعریف می کنیم که یک جمعیت تولید می کند، به عنوان مثال، [[0، 1، 1، 0، 0، 0، 1، 0، 1، 0، 1، 1، 1]،
[0، 1، 0، 0، 0، 0، 1، 1، 0، 0، 1، 1، 1]] جمعیتی با اندازه 2 است.
-
بعد، ما یک تابع برای ارزیابی تعریف می کنیم، در مورد ما از تابع compute_fitness_score استفاده می کنیم.
-
ما روش انتخاب مسابقات را برای فرآیند انتخاب، یک نقطه متقاطع برای فرآیند متقاطع و جهش بیت فلیپ را برای فرآیند جهش انتخاب کردیم.
-
# setup deap toolbox toolbox = setup_toolbox() # create a population population = toolbox.population_generator(n_population) # A simple evolutionary algorithm final_population, logbook = eaSimple( population, toolbox, crossover_probability, mutation_probability, n_generations )
ابتدا جمعیتی از افراد با اندازه 10 تولید می کنیم. سپس روش eaSimple را در deap فراخوانی می کنیم که یک الگوریتم ژنتیک ساده را انجام می دهد.
آرگومان های تابع eaSimple،
- اولین بحث جمعیت است
- جعبه ابزار نمونه ای از کلاس جعبه ابزار deap است
- احتمال متقاطع نشان دهنده احتمال عبور از یک جفت از افراد است
- احتمال جهش نشان دهنده احتمال جهش یک فرد است
- n_generations نشان دهنده تعداد نسل هایی است که باید تکامل یابند.
الگوریتم eaSimple به شرح زیر عمل می کند:
- برازندگی افراد در یک جمعیت محاسبه می شود
- با استفاده از روش انتخاب مسابقات، مناسب ترین فرد را انتخاب کنید
- با استفاده از روش متقاطع یک نقطه ای افراد را متقاطع کنید
- با استفاده از جهش بیت فلیپ، افراد را جهش دهید
- برازندگی افراد را دوباره محاسبه کنید
- مراحل 2 تا 5 را تا رسیدن به تعداد نسل مورد نظر دنبال کنید
به این ترتیب می توانید انتخاب ویژگی را با استفاده از الگوریتم ژنتیک انجام دهید.
دیدگاهتان را بنویسید