
تشخیص علائم ترافیکی با استفاده از CNN و Keras در پایتون

در این عصر هوش مصنوعی، انسان ها بیشتر به فناوری وابسته می شوند. با فناوری پیشرفته، شرکتهای چندملیتی مانند گوگل، تسلا، اوبر، فورد، آئودی، تویوتا، مرسدس بنز و بسیاری دیگر روی خودکارسازی وسایل نقلیه کار میکنند. آنها در تلاش هستند تا وسایل نقلیه خودران یا بدون راننده دقیق تری بسازند. همه شما ممکن است در مورد اتومبیل های خودران بدانید، جایی که خود وسیله نقلیه مانند یک راننده رفتار می کند و برای حرکت در جاده نیازی به راهنمایی انسانی ندارد. اما هیچ ماشینی دقیق تر از انسان نیست. محققان الگوریتم های زیادی را برای اطمینان از ایمنی و دقت جاده 100% اجرا می کنند. یکی از این الگوریتم ها Traffic Sign Recognition است که در این مطلب در مورد آن صحبت می کنیم.و به ارائه راهحلی برای تشخیص علائم ترافیکی خواهیم پرداخت.
وقتی در جاده می روید علائم راهنمایی و رانندگی مختلفی مانند علائم راهنمایی و رانندگی، گردش به چپ یا راست، محدودیت سرعت، ممنوعیت عبور وسایل نقلیه سنگین، ممنوعیت ورود، عبور کودکان و غیره را می بینید که برای رانندگی ایمن باید آنها را دنبال کنید. به همین ترتیب، وسایل نقلیه خودران نیز باید این علائم را تفسیر کرده و برای دستیابی به دقت تصمیم گیری کنند. روش تشخیص اینکه علائم راهنمایی و رانندگی به کدام طبقه تعلق دارد، طبقه بندی علائم راهنمایی و رانندگی نامیده می شود.
در این پروژه یادگیری عمیق، با استفاده از یک شبکه عصبی کانولوشن (CNN) و کتابخانه Keras، مدلی برای طبقهبندی علائم راهنمایی و رانندگی موجود در تصویر به دستههای مختلف خواهیم ساخت.
مجموعه داده
مجموعه داده تصویر متشکل از بیش از 50000 تصویر از علائم راهنمایی و رانندگی مختلف (محدودیت سرعت، عبور، علائم راهنمایی و رانندگی و غیره) است. حدود 43 کلاس مختلف در مجموعه داده برای طبقه بندی تصاویر وجود دارد. کلاس های مجموعه داده ها از نظر اندازه متفاوت هستند، زیرا برخی از کلاس ها تصاویر بسیار کمی دارند در حالی که برخی دیگر تعداد زیادی تصویر دارند. این شامل دو پوشه جداگانه Train و Test است که پوشه Train از کلاس ها تشکیل شده است و هر دسته شامل تصاویر مختلفی است.

می توانید مجموعه داده Kaggle را برای این پروژه از لینک زیر دانلود کنید.
https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign
پیش نیازها
تمام این کتابخانهها را برای شروع پروژه نصب کنید:
pip install tensorflow pip install tensorflow keras pip install tensorflow sklearn pip install tensorflow matplotlib pip install tensorflow pandas pip install tensorflow pil
توضیحات دیتاست
حدود 43 زیر پوشه (از 0 تا 42) در پوشه “train” ما موجود است و هر زیرپوشه یک کلاس متفاوت را نشان می دهد. ما یک ماژول سیستم عامل داریم که به تکرار همه تصاویر با کلاس ها و برچسب های مربوطه کمک می کند. برای باز کردن محتویات ایده ها در یک آرایه، از کتابخانه PIL استفاده می کنیم.
import numpy as
np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from PIL import Image
import os
from sklearn.model_selection
import train_test_split
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
data = []
labels = []
classes = 43
cur_path = os.getcwd()
for i in range(classes):
path = os. path.join(cur_path,'train', str(i))
images = os.listdir(path)
for a in images:
try:
image = Image.open(path + '\'+ a)
image = image.resize((30,30))
image = np.array(image)
data.append(image)
labels.append(i)
except:
print("Error loading image")
data = np.array(data)
labels = np.array(labels)
در پایان، ما باید هر تصویر را با برچسب های مربوط به آن در لیست ها ذخیره کنیم. یک آرایه NumPy برای تغذیه داده ها به مدل مورد نیاز است، بنابراین ما این لیست را به یک آرایه تبدیل می کنیم. اکنون، شکل دادههای ما این است (39209، 30، 30، 3)، که در آن 39209 نشاندهنده تعداد تصاویر، 30*30 اندازههای تصویر را به پیکسل، و 3 آخرین نشاندهنده مقدار RGB (در دسترس بودن دادههای رنگی) است.
print(data.shape, labels.shape) #Splitting training and testing dataset X_t1, X_t2, y_t1, y_t2 = train_test_split(data, labels, test_size=0.2, random_state=42) print(X_t1.shape, X_t2.shape, y_t1.shape, y_t2.shape) #Converting the labels into one hot encoding y_t1 = to_categorical(y_t1, 43) y_t2 = to_categorical(y_t2, 43)
![]()
ساخت مدل CNN
ما یک مدل CNN می سازیم تا تصاویر را به دسته های مربوطه طبقه بندی کنیم.
معماری مدل ما این است:
-
2 Conv2D layer (filter=32, kernel_size=(5,5), activation=”relu”)
-
MaxPool2D layer ( pool_size=(2,2))
-
Dropout layer (rate=0.25)
-
2 Conv2D layer (filter=64, kernel_size=(3,3), activation=”relu”)
-
MaxPool2D layer ( pool_size=(2,2))
-
Dropout layer (rate=0.25)
-
Dense Fully connected layer (256 nodes, activation=”relu”)
-
Dropout layer (rate=0.5)
-
Dense layer (43 nodes, activation=” softmax”)
#Building the model model = Sequential() model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=X_train.shape[1:])) model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu')) model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(rate=0.25)) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(rate=0.25)) model.add(Flatten()) model.add(Dense(256, activation='relu')) model.add(Dropout(rate=0.5)) model.add(Dense(43, activation='softmax')) #Compilation of the model model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
آموزش و اعتبارسنجی مدل
برای آموزش مدل خود، از متد ()model.fit استفاده می کنیم که پس از ساخت موفقیت آمیز معماری مدل به خوبی کار می کند. با کمک 64 سایز دسته ای، 95% دقت در مجموعه های تست بدست آوردیم و پس از 15 ایپوک به ثبات رسیدیم.
eps = 15 anc = model.fit(X_t1, y_t1, batch_size=32, epochs=eps, validation_data=(X_t2, y_t2))
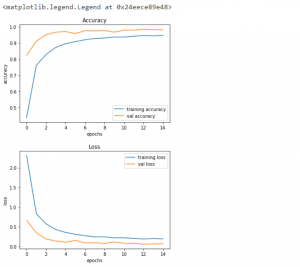
#plotting graphs for accuracy
plt.figure(0)
plt.plot(anc.anc['accuracy'], label='training accuracy')
plt.plot(anc.anc['val_accuracy'], label='val accuracy')
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
plt.figure(1)
plt.plot(history.history['loss'], label='training loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()
تست مدل
پوشه ای با نام “test” در مجموعه داده ما موجود است. در داخل آن، ما فایل اصلی کاری جدا شده به نام test.csv را دریافت کردیم. این شامل مسیرهای تصویر، و برچسب های کلاس مربوطه آنها است. ما می توانیم از کتابخانه پایتون پانداها برای استخراج مسیر تصویر با برچسب های مربوطه استفاده کنیم. در مرحله بعد، ما باید اندازه تصاویر خود را به 30×30 پیکسل تغییر دهیم تا مدل را پیش بینی کنیم و یک آرایه numpy پر از داده های تصویر ایجاد کنیم. برای درک اینکه مدل چگونه برچسب های واقعی را پیش بینی می کند، باید accuracy_score را از sklearn.metrics وارد کنیم. در نهایت، ما متد Keras model.save را فراخوانی می کنیم تا مدل آموزش دیده خود را حفظ کنیم.
#testing accuracy on test dataset
from sklearn.metrics import accuracy_score
y_test = pd.read_csv('Test.csv')
labels = y_test["ClassId"].values
imgs = y_test["Path"].values
data=[]
for img in imgs:
image = Image.open(img)
image = image.resize((30,30))
data.append(np.array(image))
X_test=np.array(data)
pred = model.predict_classes(X_test)
#Accuracy with the test data
from sklearn.metrics import accuracy_score
print(accuracy_score(labels, pred))
0.9532066508313539
model.save(‘traffic_classifier.h5’)#to save
کل کد منبع
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#to plot accuracy
import cv2
import tensorflow as tf
from PIL import Image
import os
from sklearn.model_selection import train_test_split #to split training and testing data
from keras.utils import to_categorical#to convert the labels present in y_train and t_test into one-hot encoding
from keras.models import Sequential, load_model
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout#to create CNN
data = []
labels = []
classes = 43
cur_path = os.getcwd()
#Retrieving the images and their labels
for i in range(classes):
path = os.path.join(cur_path,'train',str(i))
images = os.listdir(path)
for a in images:
try:
image = Image.open(path + '\'+ a)
image = image.resize((30,30))
image = np.array(image)
#sim = Image.fromarray(image)
data.append(image)
labels.append(i)
except:
print("Error loading image")
#Converting lists into numpy arrays
data = np.array(data)
labels = np.array(labels)
print(data.shape, labels.shape)
#Splitting training and testing dataset
X_t1, X_t2, y_t1, y_t2 = train_test_split(data, labels, test_size=0.2, random_state=42)
print(X_t1.shape, X_t2.shape, y_t1.shape, y_t2.shape)
#Converting the labels into one hot encoding
y_t1 = to_categorical(y_t1, 43)
y_t2 = to_categorical(y_t2, 43)
#Building the model
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=X_train.shape[1:]))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(43, activation='softmax'))
#Compilation of the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
eps = 15
anc = model.fit(X_t1, y_t1, batch_size=32, epochs=eps, validation_data=(X_t2, y_t2))
model.save("my_model.h5")
#plotting graphs for accuracy
plt.figure(0)
plt.plot(anc.anc['accuracy'], label='training accuracy')
plt.plot(anc.anc['val_accuracy'], label='val accuracy')
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
plt.figure(1)
plt.plot(history.history['loss'], label='training loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()
#testing accuracy on test dataset
from sklearn.metrics import accuracy_score
y_test = pd.read_csv('Test.csv')
labels = y_test["ClassId"].values
imgs = y_test["Path"].values
data=[]
for img in imgs:
image = Image.open(img)
image = image.resize((30,30))
data.append(np.array(image))
X_test=np.array(data)
pred = model.predict_classes(X_test)
#Accuracy with the test data
from sklearn.metrics import accuracy_score
print(accuracy_score(labels, pred))
model.save(‘traffic_classifier.h5’)
رابط کاربری گرافیکی برای طبقه بندی علائم راهنمایی و رانندگی
ما از یک کتابخانه استاندارد پایتون به نام Tkinter برای ایجاد یک رابط کاربری گرافیکی (GUI) برای تشخیص علائم ترافیکی خود استفاده خواهیم کرد. برای این منظور باید یک فایل پایتون جداگانه با نام “gui.py” ایجاد کنیم.
ابتدا، ما باید مدل آموزشدیده خود “traffic_classifier.h5” را با کمک کتابخانه Keras از تکنیک یادگیری عمیق بارگذاری کنیم. پس از آن، رابط کاربری گرافیکی برای آپلود تصاویر و یک دکمه طبقهبندی برای تعیین اینکه تصویر ما متعلق به کدام کلاس است، میسازیم. ما تابع ()classify را برای این منظور ایجاد می کنیم. از آنجایی که روی دکمه GUI کلیک می کنیم، این تابع به طور ضمنی فراخوانی می شود. برای پیشبینی علامت راهنمایی و رانندگی، باید همان وضوحهای شکلی را که در زمان آموزش مدل استفاده میکردیم، ارائه کنیم. بنابراین، در روش ()classify تصویر را به ابعاد شکل (1 * 30 * 30 * 3) تبدیل می کنیم. تابع model.predict_classes(image) برای پیشبینی تصویر استفاده میشود، عدد کلاس (0-42) را برای هر تصویر برمیگرداند. سپس با استفاده از این شماره کلاس می توانیم اطلاعات را از دیکشنری استخراج کنیم.
import tkinter as tk
from tkinter import filedialog
from tkinter import *
from PIL import ImageTk, Image
import numpy
#load the trained model to classify sign
from keras.models import load_model
model = load_model('traffic_classifier.h5')
#dictionary to label all traffic signs class.
classes = { 1:'Speed limit (20km/h)',
2:'Speed limit (30km/h)',
3:'Speed limit (50km/h)',
4:'Speed limit (60km/h)',
5:'Speed limit (70km/h)',
6:'Speed limit (80km/h)',
7:'End of speed limit (80km/h)',
8:'Speed limit (100km/h)',
9:'Speed limit (120km/h)',
10:'No passing',
11:'No passing veh over 3.5 tons',
12:'Right-of-way at intersection',
13:'Priority road',
14:'Yield',
15:'Stop',
16:'No vehicles',
17:'Veh > 3.5 tons prohibited',
18:'No entry',
19:'General caution',
20:'Dangerous curve left',
21:'Dangerous curve right',
22:'Double curve',
23:'Bumpy road',
24:'Slippery road',
25:'Road narrows on the right',
26:'Road work',
27:'Traffic signals',
28:'Pedestrians',
29:'Children crossing',
30:'Bicycles crossing',
31:'Beware of ice/snow',
32:'Wild animals crossing',
33:'En
d speed + passing limits',
34:'Turn right ahead',
35:'Turn left ahead',
36:'Ahead only',
37:'Go straight or right',
38:'Go straight or left',
39:'Keep right',
40:'Keep left',
41:'Roundabout mandatory',
42:'End of no passing',
43:'End no passing vehicle with a weight greater than 3.5 tons' }
#initialise GUI
top=tk.Tk()
top.geometry('800x600')
top.title('Traffic sign classification')
top.configure(background='#CDCDCD')
label=Label(top,background='#CDCDCD', font=('arial',15,'bold'))
sign_image = Label(top)
def classify(file_path):
global label_packed
image = Image.open(file_path)
image = image.resize((30,30))
image = numpy.expand_dims(image, axis=0)
image = numpy.array(image)
pred = model.predict_classes([image])[0]
sign = classes[pred+1]
print(sign)
label.configure(foreground='#011638', text=sign)
def show_classify_button(file_path):
classify_b=Button(top,text="Classify Image",command=lambda: classify(file_path),padx=10,pady=5)
classify_b.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
classify_b.place(relx=0.79,rely=0.46)
def upload_image():
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
show_classify_button(file_path)
except:
pass
upload=Button(top,text="Upload an image",command=upload_image,padx=10,pady=5)
upload.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
upload.pack(side=BOTTOM,pady=50)
sign_image.pack(side=BOTTOM,expand=True)
label.pack(side=BOTTOM,expand=True)
heading = Label(top, text="check traffic sign",pady=20, font=('arial',20,'bold'))
heading.configure(background='#CDCDCD',foreground='#364156')
heading.pack()
top.mainloop()
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید