
مدل های تولیدی و GAN چیست؟ جادوی بینایی کامپیوتر(قسمت دوم)

ایجاد تصاویر مصنوعی با استفاده از شبکه GAN، جادوی بینایی کامپیوتر (قسمت اول)
مدل های تولیدی و GAN چیست؟ جادوی بینایی کامپیوتر(قسمت دوم )
درک مدلهای تراکم صریح
ما می دانیم که یک مدل چگالی صریح یک تابع چگالی صریح را تعریف می کند. و سعی می کند احتمال آن عملکرد را در داده های آموزشی به حداکثر برساند. بسته به اینکه این مدلهای چگالی آشکار قابل جذب هستند یا خیر ، ما می توانیم آنها را به بخش های زیر تقسیم کنیم:
چگالی قابل جذب
چگالی تقریبی
قابل جذب به این معنی است که ما می توانیم یک تابع پارامتریک را تعریف کنیم که بتواند توزیع را به طور موثر ضبط کند. اما بسیاری از توزیع ها ، مانند توزیع تصاویر یا توزیع امواج گفتاری ، پیچیده هستند و طراحی یک تابع پارامتریک برای ضبط آنها بسیار دشوار است. چنین مدلهایی که تابع پارامتریک برای ضبط توزیع ندارند ، تحت مدلهای چگالی تقریبی قرار می گیرند.
برای تعریف تابع چگالی ، احتمال تصویر (x) را با استفاده از قاعده زنجیره به محصولی از توزیع های 1 بعدی تجزیه می کنیم:
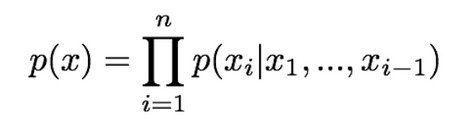
p (x) در اینجا احتمال تصویر x را نشان می دهد و سمت راست نشان دهنده احتمال مقدار پیکسل i ام با توجه به تمام پیکسل های قبلی است. پس از تعریف این تابع ، ما احتمال داده های آموزشی را به حداکثر می رسانیم. این نحوه کار مدل های چگالی قابل جذب را نشان میدهد.
Pixel RNN و Pixel CNN رایج ترین مدلهای با چگالی قابل جذب هستند. بیایید در زیر کمی بیشتر با آنها بحث کنیم.
- Pixel RNN
Pixel RNN یک شبکه عصبی عمیق است که پیکسل های تصویر را به صورت متوالی تولید می کند. شروع به تولید پیکسل ها از گوشه می کند و سپس دو پیکسل متوالی را تولید می کند. اجازه دهید این را با یک مثال توضیح دهم.
فرض کنید ما باید یک تصویر 5 × 5 ایجاد کنیم. مانند تصویر زیر دارای 25 پیکسل است:

مدل با تولید پیکسل از گوشه شروع می کند:
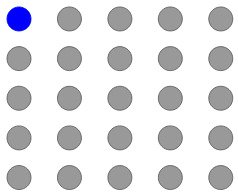
سپس ، دو پیکسل مربوطه را با استفاده از این پیکسل گوشه تولید می کند:
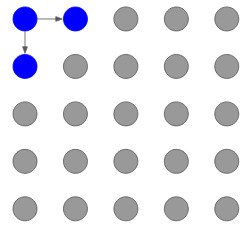
و این روند تا تولید آخرین پیکسل ادامه می یابد
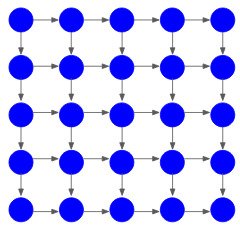
تولید پیکسل به تمام مقادیر پیکسل قبلی بستگی دارد و این وابستگی با استفاده از شبکه عصبی مکرر (RNN) یا حافظه کوتاه بلند مدت (LSTM) مدل می شود.
این یک مرور کوتاه از نحوه عملکرد Pixel RNN است. برای مطالعه بیشتر در مورد آن می توانید مقاله رسمی Pixel RNN را بررسی کنید.
اشکال استفاده از Pixel RNN این است که از آنجایی که این نسل متوالی است ، کند است. به همین دلیل است که Pixel CNN معرفی شد.
پیکسل CNN
ایده Pixel CNN کاملاً شبیه Pixel RNN است. اما ، به جای مدل سازی وابستگی پیکسل های قبلی با استفاده از RNN ، از CNN در یک منطقه زمینه استفاده می کنیم. ما از گوشه شروع می کنیم ، درست مانند Pixel RNN ، و سپس دو پیکسل متوالی را تولید می کنیم.
برای تولید پیکسل ، فرض کنیم xi ، مدل فقط می تواند از پیکسل های تولید شده قبلی استفاده کند ، یعنی x1 ، x2 ،… ، xi-1. ما برای اطمینان از این اتفاق از فیلتر پوشانده شده استفاده می کنیم:

بنابراین ، پیکسل هایی که تولید شده اند دارای مقدار 1 و بقیه مقدار 0. برای آنها تعیین شده است. این فقط مقادیر پیکسل تولید شده را در نظر می گیرد. سرعت آموزش در مورد Pixel CNN در مقایسه با زمان آموزش Pixel RNN سریعتر است ، اما تولید پیکسل ها هنوز متوالی است و بنابراین روند کند است.
به طور خلاصه ، هر دو Pixel RNN و Pixel CNN می توانند احتمال p (x) را به طور صریح محاسبه کنند که به ما معیار ارزیابی خوبی برای سنجش عملکرد مدل ما می دهد. و ما در بالا دیدیم که نمونه های تولید شده خوب هستند. از سوی دیگر ، تولید این مدل ها به عنوان یک فرآیند متوالی کند است.تا کنون ، ما توابع چگالی قابل حرکت را مشاهده کرده ایم. ما می توانیم به طور مستقیم احتمال این عملکردها را بر روی داده های آموزشی بهینه سازی کنیم. در حال حاضر ، ما در مورد یک مدل مولد دیگر به نام خودکار رمزگذار (VA) بحث خواهیم کرد.
خلاصه ای از نحوه عملکرد رمزگذارهای خودکار
بیایید به سرعت بفهمیم که رمزگذارهای خودکار چیست و سپس در مورد مفهوم رمزگذارهای خودکار مختلف و نحوه استفاده از آنها برای تولید تصاویر بحث خواهیم کرد.
رمزگذارهای خودکار یک روش بدون نظارت برای یادگیری نمایش ویژگی های ابعاد پایین هستند.آنها از دو شبکه متصل تشکیل شده اند – رمزگذار و رمزگشایی. هدف رمزگذار گرفتن ورودی (x) و تهیه نقشه ویژگی (z) است:
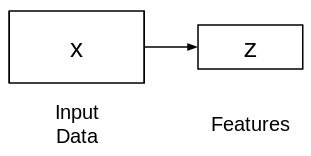
در این شکل نقشه ویژگی (z) معمولاً کوچکتر از x است. چرا فکر می کنی مسئله اینه؟
از آنجا که ما می خواهیم z فقط عوامل معنی دار تغییرات را که می توانند داده های ورودی را توصیف کنند ، ضبط کند ، شکل z معمولاً کوچکتر از x است. حال ، این سوال مطرح می شود که چگونه این ویژگی نمایش (z) را یاد بگیریم؟ چگونه این مدل را آموزش دهیم؟ برای این منظور ، می توانیم یک شبکه رمزگشایی را در بالای ویژگی های استخراج شده اضافه کنیم و از L2 loss برای آموزش مدل استفاده کنیم:
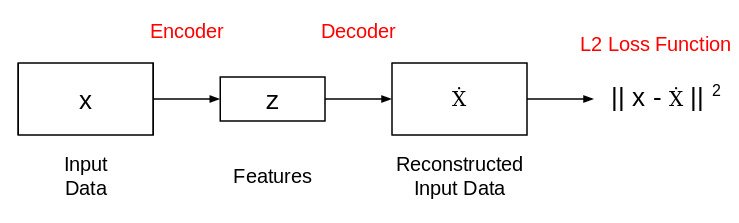
شبکه رمزگذار خودکار به این شکل است. این شبکه به گونه ای آموزش دیده است که از ویژگی های (z) می توان برای بازسازی داده های ورودی اصلی (x) استفاده کرد. اگر خروجی (Ẋ) با ورودی (x) متفاوت باشد ، از دست دادن L2 آن را جریمه می کند و به بازسازی داده های ورودی کمک می کند.
حال ، چگونه می توانیم تصاویر جدیدی از این رمزگذارهای خودکار ایجاد کنیم؟
رمزگذارهای خودکار متنوع
اینجاست که رمزگذارهای خودکار مختلف مفید هستند. آنها فرض می کنند که داده های آموزش از برخی نمایه های زیربنایی مشاهده نشده (z) تولید می شود.
تفاوت اصلی بین رمزگذار خودکار ساده و رمزگذار خودکار در این است که ما به جای استخراج مستقیم ویژگی ها از داده های ورودی ، سعی می کنیم توزیع احتمال داده های آموزش را مدل سازی کنیم.
برای این منظور ، به جای اینکه خروجی رمزگذار را بردار رمزگذاری اندازه n قرار دهیم ، دو بردار اندازه n را خروجی می کنیم – بردار میانگین و بردار دیگر انحراف استاندارد.
معماری کامل شبکه رمزگذارهای خودکار مختلف به این شکل است:
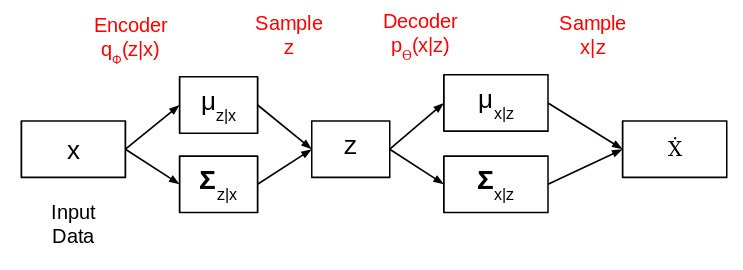
میانگین در اینجا موقعیتی را که رمزگذاری ورودی باید در آن متمرکز باشد کنترل می کند و انحراف استاندارد کنترل می کند که میانگین کدگذاری ها چقدر می تواند متفاوت باشد. تابع ضرر برای آموزش رمزگذار متغییرخودکار استفاده می شود واگرایی Kullback-Leibler (یا واگرایی KL) نامیده می شود. این میزان تفاوت دو توزیع احتمال را اندازه گیری می کند:
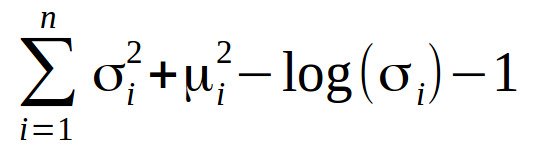
ما باید واگرایی KL را به حداقل برسانیم. این امر پارامترهای توزیع احتمال (میانگین و انحراف معیار) را بهینه می کند. پس از آموزش این مدل ، می توانیم تصاویر جدیدی از آن ایجاد کنیم. بگذارید به شما نشان دهم چگونه؟
چگونه می توانیم با استفاده از رمزگذارهای خودکار مختلف تصاویر تولید کنیم؟
پس از آموزش مدل ، بخش رمزگذار را حذف کرده و شبکه زیر را دریافت می کنیم:
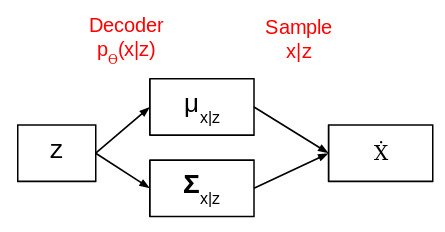
اکنون یک توزیع احتمال ساده با میانگین 0 و انحراف استاندارد 1 را انتخاب کرده و آن را به عنوان ورودی به شبکه فوق منتقل می کنیم. سپس خروجی تولید می کند. به این ترتیب رمزگذارهای خودکار مختلف می توانند به ما در تولید تصاویر کمک کنند.
اگرچه این روش برای تولید تصاویر بسیار مفید است ، اما چند نکته منفی نیز در آن وجود دارد. یکی از اشکالات عمده رمزنگاران خودکار متغییر این است که نمونه های تولید شده در مقایسه با نمونه های GAN های پیشرفته تارتر و کیفیت پایینی دارند. این یک زمینه تحقیقاتی فعال است – امیدواریم به زودی شاهد پیشرفت هایی باشیم!
تا کنون ، همه مدلهای مولد که مشاهده کرده ایم یک تابع چگالی صریح را تعریف می کنند. اگر بخواهیم چگالی را به صراحت مدل سازی نکنیم ، فقط توانایی نمونه برداری از مجموعه آموزشی را به طور ضمنی داریم؟ اینجاست که GAN ها وارد می شوند. آنها دارای تابع چگالی ضمنی هستند که به نمونه برداری از مجموعه آموزش کمک می کند.
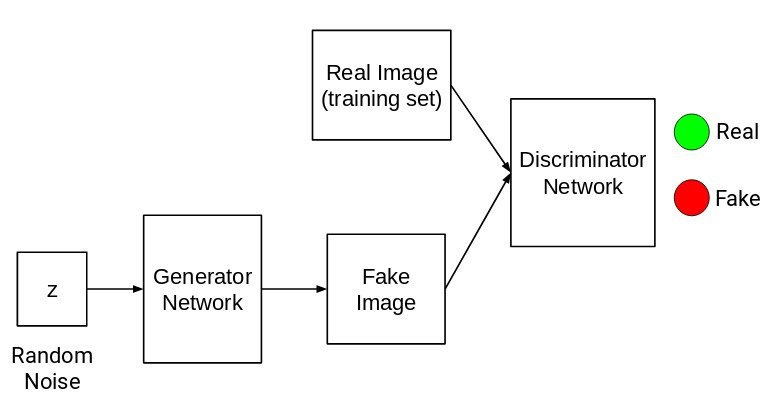
GAN ها از دو شبکه متفاوت تشکیل شده اند:
شبکه ژنراتور
شبکه تفکیک کننده
اجازه دهید هر شبکه را با جزئیات توضیح دهم.
شبکه ژنراتور
هدف شبکه ژنراتور تولید تصاویر با نویز تصادفی به عنوان ورودی است:
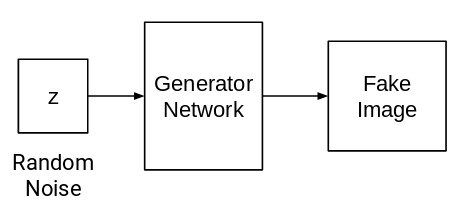
این شبکه ژنراتور یک شبکه عصبی یا یک شبکه عصبی کانولوشن (CNN) است. ما نویز تصادفی را منتقل می کنیم و این شبکه با استفاده از آن نویز تصویری ایجاد می کند.
شبکه تفکیک کننده
کار یک شبکه تفکیک کننده بسیار ساده است. باید تشخیص دهد که ورودی واقعی است یا جعلی:

همه تصاویر مجموعه آموزشی به عنوان Real (یا 1) و همه تصاویر ایجاد شده از شبکه ژنراتور به عنوان Fake (یا 0) علامت گذاری شده اند. در حال حاضر ، وظیفه یک شبکه تشخیص دهنده اجرا تابع باینری است. باید ورودی را به عنوان واقعی یا جعلی (1 یا 0) طبقه بندی کند.
مزیت این مدل این است که کاملاً متمایز است. از آنجا که هر دو مولد و تشخیص دهنده ، شبکه های عصبی (یا شبکه های عصبی پیچشی) هستند ، یک شبکه کاملاً متغیر بدست می آوریم.
ما مدل را آموزش می دهیم ، تابع ضرر را در انتهای شبکه تشخیص دهنده محاسبه می کنیم و ضرر را به دو مدل تشخیص دهنده و مولد ارائه می دهیم.
این پارامترهای هر دو شبکه را به روز می کند و متعاقباً نتایج را بهبود می بخشد. هر دو مولد و تشخیص دهنده به طور مشترک در یک بازی minimax آموزش دیده اند:
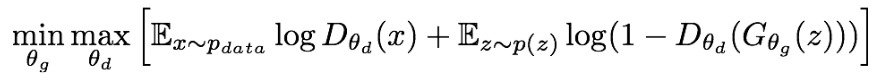
اینجا:
- p (داده) نشان دهنده توزیع داده ها از مجموعه آموزش است
- D (x) این احتمال است که x از داده های آموزش بدست آید
- p (z) متغیر نویز ورودی را نشان می دهد
تفکیک کننده (D) می خواهد تابع هدف را به حداکثر برساند به طوری که D (x) نزدیک به 1 و D (G (z)) نزدیک به 0 باشد. این بدان معناست که متمایز کننده باید تمام تصاویر مجموعه آموزشی را واقعی تشخیص دهد (1) و تمام تصاویر ایجاد شده به عنوان جعلی (0).
ژنراتور (G) می خواهد تابع هدف را به حداقل برساند به این صورت که D (G (z)) 1 است. این بدان معناست که مولد سعی می کند تصاویری تولید کند که توسط شبکه تشخیص دهنده به عنوان واقعی (1) طبقه بندی می شوند.
این چنین است که یک شبکه مخالف تولیدی (GAN) کار می کند.
پایان و موفق باشید
دیدگاهتان را بنویسید