
یادگیری انتقالی با کمک تنسرفلو

مقدمه ای کوتاه بر یادگیری انتقالی
فراگیرترین مشکلات در یادگیری ماشین مربوط به داده است: ممکن است ناکافی یا با کیفیت پایین باشد. یک راه حل واضح برای این مجموعه از مشکلات، به دست آوردن داده های بیشتر و بهتر است. با این حال، این دو اغلب متناسب با هم نیستند. باید کیفیت را فدای کمیت کنیم یا برعکس. خوشبختانه راه حل ابتکاری تری مانند استفاده از یادگیری انتقالی وجود دارد.
یادگیری انتقالی روشی برای استفاده مجدد از مدلی است که قبلاً برای کار دیگری آموزش دیده است. مرحله اصلی آموزش، پیش آموزش نامیده می شود. ایده کلی این است که، پیشآموزش، ویژگیهای کلیتری را به مدل «آموزش» میدهد، در حالی که آخرین مرحله آموزشی، ویژگیهای مختص دادههای (محدود) خودمان را «آموزش» میدهد.
یادگیری انتقالی به ویژه در زمینه هایی مانند پزشکی مفید است، جایی که کمبود داده یک مشکل دائمی است. مدلهای مختلف CNN که از قبل بر روی دادههای ImageNet آموزش دیدهاند، در کارهای مختلف پزشکی موفق بودهاند. تنها چیزی که لازم است چند خط کد برای انتقال آنها به داده های پزشکی است.
در این مطلب قصد داریم نحوه انجام این کار را با TensorFlow، پرکاربردترین پلتفرم یادگیری عمیق در جهان (از سال 2021) بیاموزیم. قبل از اینکه به کدها بپردازیم، بیایید یک خلاصه سریع از تنسرفلو و پلتفرم کراس داشته باشیم که آن را تقویت می کند.
پلتفرم تنسرفلو و کراس:
تنسرفلو یک پلتفرم سراسری است که ساخت و استقرار مدل های یادگیری ماشین را امکان پذیر می کند. ما به ساختن مدلها علاقهمندیم و برای آن باید از کراس استفاده کنیم. کراس یک پلتفرم است که برای “انسان ها، نه ماشین ها” طراحی شده است. یعنی کراس برای کدنویسانی مانند ما که میخواهند مدلهای سفارشی بسازند طراحی شده است. نحو ساده و به یاد ماندنی آن تقریباً اعتیادآور است.
در حالی که پلتفرم کراس خود به عنوان یک کتابخانه پایتون مستقل در دسترس است، به عنوان بخشی از کتابخانه تنسرفلو نیز در دسترس است. استفاده از tensorflow.keras بر روی خود کراس توصیه میشود، زیرا توسط تیم تنسرفلو حفظ میشود، که سازگاری با سایر ماژولهای تنسرفلو را تضمین میکند.
طبقه بندی تصاویر باینری:

به عنوان اولین مثال، طبقه بندی تصاویر باینری را امتحان خواهیم کرد. مجموعه داده ما Hot Dog – Not Hot Dog از Kaggle خواهد بود و ما سعی خواهیم کرد پیش بینی کنیم، آیا تصویر داده شده هات داگ است یا خیر.برای این کار، از مدل ResNet50 استفاده می کنیم که از قبل روی مجموعه داده ImageNet آموزش داده شده است.
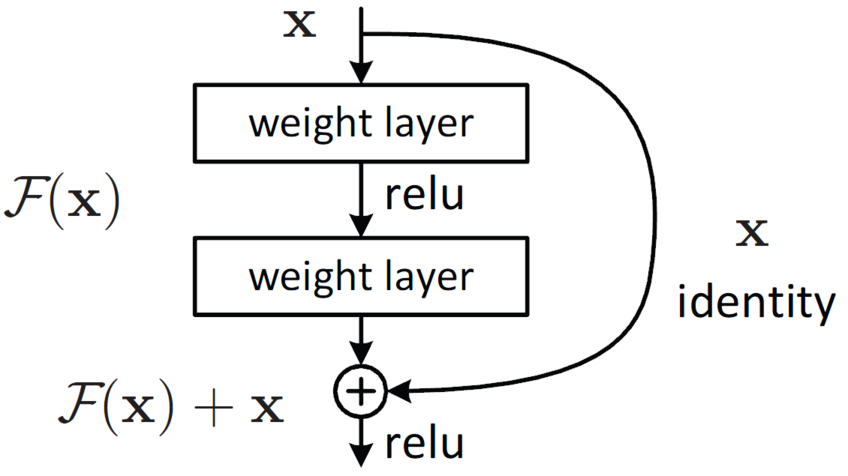
شکل زیر نشان دهنده معماری ResNet50 است:
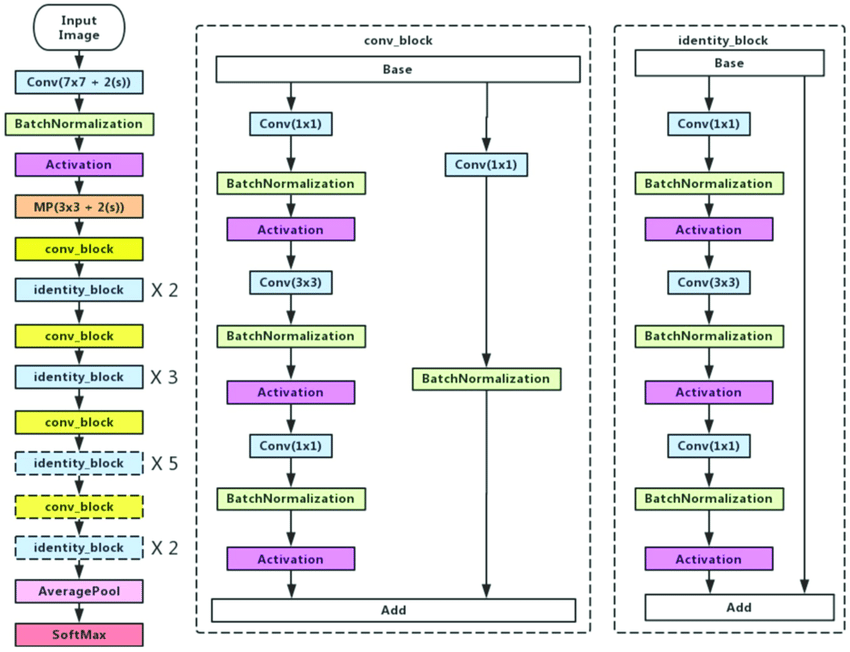
جایگزین هایی برای خانواده ResNet وجود دارد: MobileNets، Inception و غیره نیز در طبقه بندی تصاویر موفق بوده اند. همچنین می توانید یکی از اینها یا یک شبکه کاملاً متفاوت را انتخاب کنید و یادگیری انتقالی را روی آن انجام دهید.
محیطی را برای یادگیری انتقال با تنسرفلو تنظیم کنید.
توجه: این مرحله ممکن است بسته به محیط دلخواه شما متفاوت باشد. محیط شامل گوگل کولب یا پای چارم،ژوپیتر و …میشود.
# Upload the kaggle API key from google.colab import files files.upload()
! mkdir ~/.kaggle ! cp kaggle.json ~/.kaggle/ ! chmod 600 ~/.kaggle/kaggle.json
# Install the kaggle package ! pip install -q kaggle
# Download the dataset from Kaggle ! kaggle datasets download -d dansbecker/hot-dog-not-hot-dog
# Import the necessary packages import tensorflow as tf from tensorflow import keras from PIL import Image import os import numpy as np
داده ها را برای یادگیری انتقالی با تنسرفلو بارگیری کنید.
# Unzip the downloaded zip file !unzip /content/hot-dog-not-hot-dog.zip
# Let's check size of images
for image in list(os.walk("/content/train/not_hot_dog"))[0][2]:
a = Image.open(f"/content/train/not_hot_dog/{image}")
print(np.asarray(a).shape)
 این تنها بخشی از خروجی است، اما در حال حاضر میتوانیم ببینیم که اندازههای تصویر ثابت نیستند. ImageDataGenerator با این نوع مشکلات در میان بسیاری از موارد دیگر سروکار دارد.
این تنها بخشی از خروجی است، اما در حال حاضر میتوانیم ببینیم که اندازههای تصویر ثابت نیستند. ImageDataGenerator با این نوع مشکلات در میان بسیاری از موارد دیگر سروکار دارد.
داده های تصویر اساساً آرایه ای از اعداد هستند. تصاویر رنگی با ترکیبی از سه ماتریس دو بعدی نمایش داده می شوند. هر یک از این ماتریس ها از مقادیر بین 0 تا 255 تشکیل شده اند (این ممکن است متفاوت باشد). سه عدد از این مقادیر با هم ترکیب شده اند (هر کدام از یک ماتریس) فاصله پیکسل را نشان می دهند. در مورد ما، تصاویر ما شکل (512، 512، 3) دارند. یعنی ما 512*512=262144 پیکسل و 3 کانال داریم. (همانطور که قبلاً گفتیم، همه آنها با اندازه 512*512 مطابقت ندارند، اما ما به آن خواهیم پرداخت.)
# Create ImageDataGenerator objects train_datagen = tf.keras.preprocessing.image.ImageDataGenerator() test_datagen = tf.keras.preprocessing.image.ImageDataGenerator()
# Assign the image directories to them
train_data_generator = train_datagen.flow_from_directory(
"/content/train",
target_size=(512,512)
)
test_data_generator = train_datagen.flow_from_directory(
"/content/test",
target_size=(512,512)
)
ImageDataGenerator در صورت لزوم داده ها را به صورت دسته ای برای مدل ما تولید می کند. این به ما این امکان را می دهد که مستقیماً با داده های ذخیره شده روی هارد دیسک بدون بارگذاری بیش از حد رم کار کنیم. train_data_generator و test_data_generator به ترتیب به عنوان آرگومان به پارامترهای x و validation_data ارسال خواهند شد. از آنجایی که ImageDataGenerator کلاس ها را از نام پوشه ها دریافت می کند، ما به پارامتر y نیاز نداریم. (اگر سعی کنید یک آرگومان را به y ارسال کنید، پایتون یک خطا ایجاد می کند.)
اکنون که داده های آموزش و آزمایش ما تنظیم شده است، می توانیم مدل خود را بسازیم و آموزش دهیم.
مدل یادگیری انتقالی را با تنسرفلو بسازید.
ابتدا پیاده سازی کراس مدل ResNet 50 را بارگذاری می کنیم.
resnet_50 = tf.keras.applications.resnet50.ResNet50(include_top=False, weights='imagenet') resnet_50.trainable=False
include_top=False تضمین می کند که آخرین لایه مدل ResNet50 بارگذاری نمی شود. weights=’imagenet’ وزن های ImageNet را بارگیری می کند. اگر weights=None را تنظیم کنیم، وزنها بهطور تصادفی مقداردهی اولیه میشوند (در این حالت، یادگیری انتقالی را انجام نمیدهیم). با تنظیم ویژگی trainable روی False، اطمینان حاصل می کنیم که وزن اصلی (ImageNet) مدل ثابت می ماند.
ما به یک طبقه بندی کننده باینری نیاز داریم، اما ResNet50 بیش از 2 گره در لایه های نهایی دارد. یعنی باید لایه نهایی را به صورت دستی اضافه کنیم. من از پلتفرم کاربردی استفاده کرده ام، که اگر کاربر مبتدی تنسرفلو باشید می تواند چالش برانگیز باشد. (در این صورت، پیشنهاد میکنم از Sequential استفاده کنید که نحو سادهتری دارد.)
inputs = keras.Input(shape=(512,512,3)) x = resnet_50(inputs) x = keras.layers.GlobalAveragePooling2D()(x) outputs = keras.layers.Dense(2, activation="softmax")(x) model = keras.Model(inputs=inputs, outputs=outputs, name="my_model") model.compile(optimizer="Adam", loss="binary_crossentropy", metrics=["accuracy"]) model.summary()
در این خطوط، ورودی خود را تعریف می کنیم، آن را به مدل resnet_50 که قبلا تعریف کرده بودیم، ارسال می کنیم، خروجی آن را به یک لایه Global Average Pooling، خروجی آن را به یک لایه ِDense(برای دو کلاس) می دهیم. تابع فعال سازی در این مورد باید softmax باشد. مجموع مقادیر بردار خروجی softmax همیشه با 1 برابر است. برای دو گره (هر گره نشان دهنده یک کلاس)، x1 + x2 = 1 داریم، که در آن x1 و x2 احتمالات کلاس را نشان می دهند. (در غیر این صورت می توانیم 1 گره و تابع فعال سازی سیگموئید داشته باشیم). پس از همه اینها، باید با انتخاب یک بهینه ساز و یک تابع ضرر، مدل را کامپایل کنیم. همچنین میتوانیم معیارهایی را برای اندازهگیری در طول فرآیند آموزش اضافه کنیم. در نهایت، ما می توانیم مدل خود را آموزش دهیم.
model.fit(train_data_generator, validation_data=test_data_generator, epochs=5)
 کار ما با بخش آموزش یادگیری انتقالی تمام شده است. به صورت اختیاری، می توانید مدل را به fine-tune تنظیم کنید تا نتایج بهتری بگیرید.
کار ما با بخش آموزش یادگیری انتقالی تمام شده است. به صورت اختیاری، می توانید مدل را به fine-tune تنظیم کنید تا نتایج بهتری بگیرید.
سخن پایانی
در این مطلب یاد گرفتیم که چگونه یادگیری انتقال را با کمک تنسرفلو پیاده سازی کنیم. یادگیری انتقالی یک رویکرد قدرتمند است که به ما امکان می دهد بر کمبود داده غلبه کنیم.مواردی وجود دارد که کار با هر داده ای که داریم منطقی تر است و نتایج بهتری به همراه دارد. و جایگزین هایی دارد. افزایش داده یک امر رایج است. البته این دو انحصاری نیستند. رویکردهای مختلف را می توان (اغلب) برای حل مشکل داده ترکیب کرد.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید