
انواع داده ها در دیتاست های یادگیری ماشین

دیتاست چیست؟
به مجموعه ای از داده های جمع آوری شده برای ایجاد مدل های یادگیری ماشین و فرآیند آموزش دیتاست (مجموعه داده) گفته می شود. معمولاً مجموعه داده از تعدادی سطر و ستون تشکیل شده است. هر سطر مشکل کننده ی یک نمونه داده و هر ستون مشخص کننده ی یک ویژگی است. فرض کنید ما می خواهیم یک سیستم هوش مصنوعی طراحی کنیم که قیمت خانه را پیش بینی کند. برای این کار نیاز به داده های قبلی داریم که در آن قیمت واقعی خانه ها پیش بینی شده باشد. اما برای این داده ها باید تعدادی ویژگی (Feature) تعیین کنیم. این ویژگی ها باید توصیف مناسبی از داده ها ارائه دهند تا فرآیند یادگیری دقیق تر باشد. به عنوان مثال: مساحت، تعداد اتاق، نوع سازه، سن بنا، طبقه، منطقه و … می توانند ویژگی های مناسبی برای این داده ها باشند. در اینجا اطلاعات مربوط به هر خانه، یک نمونه (sample) محسوب می شود. واضح است که هر چه ویژگی های بهتری (نه لزوماً بیشتر) داشته باشیم و تعداد نمونه ها بیشتر باشد، دیتاست ما بهتر خواهد بود.
انواع داده ها در دیتاست
داده ها را می توان به دو دسته کلی: عددی (Numerical) و غیر عددی (Categorical) تقسیم بندی کرد. داده های عددی می توانند گسسته یا پیوسته باشند و داده های غیر عددی می توانند ترتیبی و غیر ترتیبی باشد. مثلاً سن افراد یک ویژگی عددی گسسته و مساحت خانه یک ویژگی عددی گسسته است. جنسیت افراد و رنگ پوست ویژگی های غیر عددی و غیر ترتیبی هستند. اما ویژگی کیفیت یک محصول، اگر دارای مقادیر (ضعیف، متوسط، خوب و عالی ) باشد چون دارای ارزش جایگاهی هستند از نوع ترتیبی (ordinal) محسوب می شوند.
داده های عددی (Numerical)
- عددی گسسته (مانند تعداد اتاق یک خانه)
- عددی پیوسته (مانند مساحت خانه)
داده های غیرعددی یا دسته ای (Categorical)
- داده های غیر Ordinal (مانند رنگ چشم) برای این نوع ویژگی ها نمی توان ارزش جایگاهی تعیین کرد. مثلا نمی توان گفت رنگ آبی به قرمز نزدیک تر است یا به سبز (منطور ما اینجا استفاده از ویژگی رنگ در پردازش تصویر نیست)
- داده های Ordinal (مانند جایگاه یک شخص در یک سازمان یا کیفیت یک محصول: A, B, C, D) در این حالت مقادیر دارای ارزش جایگاهی هستند. به عنوان مثال فاصله جایگاهی معاون با مدیرعامل، کمتر از فاصله آن با کارشناس امور مالی است.
دلیل اینکه ویژگی های Ordinal و غیر ordinal را از هم تفکیک میکنیم این است که روش تبدیل این نوع داده ها، به داده های عددی متفاوت است. چون در اکثر موارد ما مجبور هستیم داده های غیر عددی را به داده های عددی تبدیل کنیم تا مدل بتواند از آن استفاده کند. به عنوان مثال در روش ماشین بردار پشتیبان یا SVM یا شبکه عصبی، همه ویژگی ها باید از نوع عددی باشند. اما در درخت تصمیم، ترجیح این است که ویژگی ها از نوع غیر عددی باشند.
ویژگی Target چیست؟
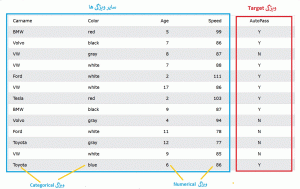
معمولاً داده های جمع آوری شده دارای برچسب یا Label هستند. این برچسب ها توسط فرد خبره روی داده ها به داده ها اضافه می شوند. به عنوان مثال در مجموعه داده اطلاعات خانه ها، ویژگی قیمت ویژگی Target است و مسئله ما باید این ویژگی را بر اساس سایر ویژگی ها یاد بگیرد و در آینده آن را برای نمونه های جدید پیش بینی کند. اما ممکن است یک مجموعه داده فاقد ویژگی برچسب باشد. اگر داده ها دارای برچسب باشند، مدل یادگیری از نوع باناظر و اگر فاقد برچسب باشند از نوع بدون ناظر است. در زیر یک نمونه دیتاست با 5 ویژگی (شامل یک ویژگی Target) و 13 نمونه نشان داده شده است.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

دیدگاهتان را بنویسید