
روش اعتبارسنجی متقابل(k-fold cross-validation)
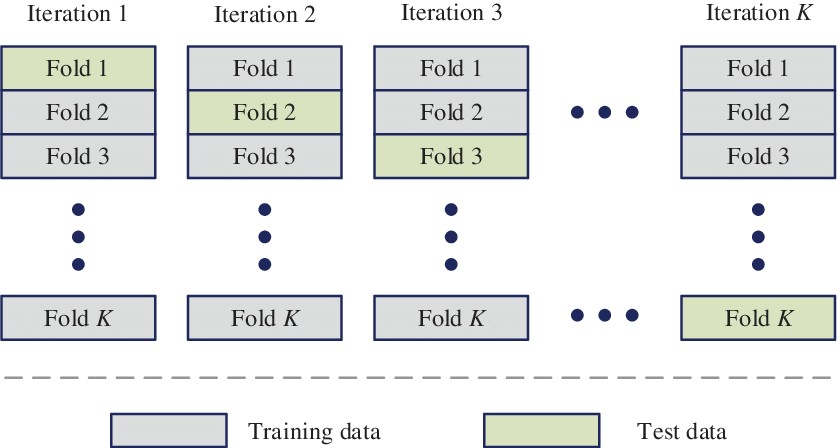
روش اعتبارسنجی متقابل (k-fold)
حالتی را در نظر بگیرید که داده های آموزشی شما در یک مسئله یادگیری ماشین، نسبتاً کم باشد و یا اینکه نتیجه مربوط به داده های تست را خیلی دقیق ندانید و بخواهید چند بار آزمایش را تکرار کنید و در نهایت میانگین این نتایج را برای ارزیابی نهایی در نظر بگیرید. در این شرایط روش اعتبارسنجی متقابل یا Cross Validation به ما کمک می کند که داده ها را به K قسمت تقسیم کنیم. سپس طی K مرحله مختلف هر بار یکی از K قسمت را به عنوان تست و K-1 قسمت دیگر را به عنوان داده آموزشی در نظر بگیریم. در نهایت میانگین نتایج ارزیابی را به عنوان نتیجه ارزیابی در نظر بگیریم.
اعتبارسنجی متقابل، یک روش استاندارد برای برآورد عملکرد یک الگوریتم یادگیری ماشین بر روی مجموعه داده است. یکی از رویکردها بررسی تأثیر مقادیر مختلف k در برآورد عملکرد مدل و مقایسه آن با شرایط آزمایش ایده آل است. این می تواند به انتخاب مقدار مناسب برای k کمک کند.
هنگامی که یک مقدار k انتخاب شد. می توان از آن برای ارزیابی مجموعه ای از الگوریتم های مختلف در مجموعه داده استفاده کرد. توزیع نتایج را می توان با ارزیابی یک الگوریتم مشابه با استفاده از یک شرایط آزمون ایده آل مقایسه کرد تا ببینیم آیا آنها بسیار مرتبط هستند یا نه. در صورت همبستگی، تأیید می کند که پیکربندی انتخاب شده تقریبی قوی برای شرایط آزمایش ایده آل است.
در این آموزش، نحوه پیکربندی و ارزیابی پیکربندی اعتبارسنجی متقابل (k-fold) را خواهید آموخت.
اعتبار سنجی متقابل یک روش است که برای برآورد مهارت مدلهای یادگیری ماشین استفاده می شود.
روش k-fold برای برآورد مهارت مدلهای یادگیری ماشین
1- اعتبارسنجی متقابل k-fold روشی است که برای برآورد مهارت مدل در داده های جدید استفاده می شود.
2- تاکتیک های متداولی وجود دارد که می توانید از آنها برای انتخاب مقدار k برای مجموعه داده خود استفاده کنید.
3- معمولاً در اعتبار سنجی متغیرها از قبیل طبقه بندی و تکرار استفاده می شود که در scikit-learn موجود است.
این روش دارای یک پارامتر به نام k است که به تعداد گروههایی اشاره می کند که یک نمونه داده مشخص باید به آن تقسیم شود. به این ترتیب ، اغلب به این روش اعتبار متقابل k-fold گفته می شود. هنگامی که مقدار خاصی برای k انتخاب می شود. ممکن است به جای k در ارجاع به مدل استفاده شود ، مانند k = 10 که 10 برابر اعتبار متقابل می شود.
اعتبارسنجی متقابل عمدتا در یادگیری ماشینی برای برآورد مهارت مدل در داده های دیده نشده استفاده می شود. به این معنا که از یک نمونه محدود برای تخمین نحوه عملکرد کلی مدل در هنگام پیش بینی داده هایی که در طول آموزش مدل استفاده نمی شوند ، استفاده شود.
این یک روش محبوب است زیرا درک آن ساده است. و به طور کلی منجر به برآورد خوش بینانه تری از مهارت مدل نسبت به سایر روش ها ، مانند تقسیم آموزش/آزمون ساده می شود.
مراحل اجرای روش اعتبارسنجی متقابل
مجموعه داده را به طور تصادفی مخلوط کنید.
مجموعه داده را به k گروه تقسیم کنید
برای هر گروه منحصر به فرد:
گروه را به عنوان یک مجموعه داده آماده یا آزمایش کنید.
گروه های باقی مانده را به عنوان مجموعه داده های آموزشی در نظر بگیرید.
یک مدل را روی مجموعه آموزشی قرار دهید و آن را در مجموعه تست ارزیابی کنید.
نمره ارزیابی را حفظ کرده و مدل را کنار بگذارید.
مهارت مدل را با استفاده از نمونه نمرات ارزیابی مدل خلاصه کنید.
نکته مهم این است که هر مشاهده در نمونه داده ها به یک گروه اختصاص داده می شود. و در طول مدت عمل در آن گروه باقی می ماند. این بدان معناست که به هر نمونه فرصتی داده می شود که 1 بار در مجموعه نگهدارنده مورد استفاده قرار گیرد. و برای آموزش مدل k-1 بار استفاده شود.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

دیدگاهتان را بنویسید