
مقایسه یادگیری عمیق و یادگیری ماشین

اینیادگیری عمیق زیرشاخه یادگیری ماشینی است که از مجموعه ای از نورون های سازماندهی شده در لایه ها استفاده می کند. یک مدل یادگیری عمیق از سه لایه تشکیل شده است: لایه ورودی، لایه خروجی و لایه های پنهان.
یادگیری عمیق چندین مزیت را نسبت به الگوریتمهای یادگیری ماشین رایج مانند k نزدیکترین همسایه، ماشین بردار پشتیبان، رگرسیون خطی و غیره ارائه میدهد. برخلاف الگوریتمهای یادگیری ماشین، مدلهای یادگیری عمیق میتوانند ویژگیهای جدیدی را از مجموعه محدودی از اطلاعات ایجاد کنند و تجزیه و تحلیل پیشرفته انجام دهند.
یک مدل یادگیری عمیق می تواند ویژگی های بسیار پیچیده تری را نسبت به الگوریتم های یادگیری ماشین یاد بگیرد. با این حال، با وجود مزایایی که دارد، چندین چالش را نیز به همراه دارد. این چالش ها شامل نیاز به حجم زیادی از داده ها و سخت افزارهای تخصصی مانند GPU و TPU است.
در این مطلب، ما یک مدل رگرسیون یادگیری عمیق برای پیشبینی قیمت خانه با استفاده از مجموعه دادههای معروف پیشبینی قیمت خانه بوستون ایجاد میکنیم.
مجموعه داده های پیش بینی خانه بوستون
این مجموعه داده شامل 506 ردیف با 13 ویژگی و یک ستون هدف، ستون قیمت است. مجموعه داده به راحتی در اینترنت در دسترس است و برای دانلود آن می توانید از این لینک استفاده کنید. یا همانطور که در مراحل زیر خواهید دید، می توان آن را با استفاده از Keras بارگذاری کرد.
import pandas as pd import numpy as np # import tensorflow as tf from tensorflow import keras from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
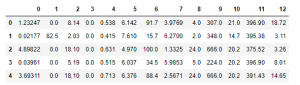
(train_features, train_labels), (test_features, test_labels) = keras.datasets.boston_housing.load_data() pd.DataFrame(train_features).head()
اگر داده ها را از Keras بارگذاری کنیم، داده ها را در یک آرایه NumPy دریافت خواهیم کرد. بنابراین، برای بررسی بهتر آن، آن را به یک فریم ورک پاندا تبدیل می کنیم و head آن به صورت زیر است:
مدل رگرسیون یادگیری عمیق
اکنون دیدیم که مجموعه داده به چه شکل است. میتوانیم ساخت مدل رگرسیون یادگیری عمیق را شروع کنیم. برای ایجاد مدل از کتابخانه TensorFlow استفاده می کنیم. از آنجایی که مجموعه داده خیلی بزرگ نیست، می توانیم تعداد لایه ها را در مدل یادگیری عمیق محدود کنیم و در زمان صرفه جویی کنیم. با فعال سازی relu از دو لایه کاملا متصل استفاده خواهیم کرد. اگر بزرگتر از 0 باشد، فعال سازی relu مستقیماً ورودی را خروجی می کند. در غیر این صورت صفر را برمی گرداند.
model = keras.Sequential() model.add(Dense(20, activation='relu', input_shape=[len(train_features[0])])) model.add(Dense(1)) # model.compile(optimizer= 'adam', loss='mse', metrics=['mse']) history = model.fit(train_features, train_labels, epochs=20, verbose=0)
در کد بالا یک شبکه عصبی feed-forward ایجاد کرده ایم. ما مدل را برای 20 دوره آموزش دادیم و از میانگین مربعات خطا به عنوان تابع ضرر با بهینه ساز adam استفاده کردیم. اکنون میتوانیم نتایج را روی دادههای آزمایش پیشبینی کرده و آن را با مقادیر واقعی مقایسه کنیم.
from sklearn.metrics import mean_squared_error as mse pred = model.predict(test_features) mse(pred, test_labels)
میتوانید از مجموعههای مقادیر دیگری مانند میانگین خطای مطلق به جای میانگین مربع خطا یا بهینهساز RMS به جای بهینهساز adam استفاده کنید. همچنین میتوانید نرخ یادگیری و تعداد دورهها را برای دستیابی به نتایج بهتر تغییر دهید.
مدل رگرسیون یادگیری عمیق ما تکمیل شده است.حال نتایج آن را با برخی از الگوریتمهای یادگیری ماشینی محبوب مقایسه خواهیم کرد.
K نزدیکترین همسایه
ابتدا، دادههای K نزدیکترین همسایه را آموزش میدهیم. این الگوریتم برای مسائل طبقهبندی محبوب است، اما نتایج منصفانهای را در وظایف رگرسیون نیز ارائه میدهد. فاصله بین نمونه های موجود در مجموعه های آموزشی و تست را محاسبه می کند. و سپس بر اساس مثال های K، نزدیک به مسئله، پیش بینی می کند.
from sklearn.neighbors import KNeighborsRegressor as KNN model_k = KNN(n_neighbors=3) model_k.fit(train_features,train_labels)
pred_k = model_k.predict(test_features) mse(pred_k, test_labels)
رگرسیون خطی
یک الگوریتم یادگیری نظارت شده انتظار یک رابطه خطی بین متغیر ورودی و خروجی را دارد. با فرمول Y = a +bX کار می کند. در اینجا X متغیر توضیحی، Y متغیر وابسته، و b شیب بهترین خط مناسب است.
from sklearn.linear_model import LinearRegression model_l = LinearRegression() model_l.fit(train_features, train_labels)
pred_l = model_l.predict(test_features) mse(pred_l, test_labels)
ماشین بردار پشتیبان
این یک الگوریتم یادگیری نظارت شده است که یک ابر صفحه را در فضای N بعدی پیدا می کند و نقاط داده را به طور مشخص طبقه بندی می کند. هایپرپلن بهترین خط برای جداسازی کلاس ها و تفکیک آنها در فضای N بعدی است. SVM همچنین می تواند با داده هایی که به صورت خطی قابل تفکیک نیستند استفاده شود.
from sklearn.svm import SVR model_s = SVR(C=1.0) model_s.fit(train_features, train_labels)
pred_s = model_s.predict(test_features) mse(pred_s, test_labels)
Sklearn همچنین یک پارامتر منظم C را همراه با SVM ارائه می دهد. منظمسازی، مدل را از یادگیری بسیاری از ویژگیهای پیچیده که میتواند منجر به برازش بیش از حد دادهها شود، جلوگیری میکند.
اکنون هر مدلی را که تا کنون ساخته ایم با هم مقایسه می کنیم. ما مدل ها را بر اساس ریشه میانگین مربعات خطا مقایسه خواهیم کرد.
| Model | Algorithm | MSE(Mean Squared Error) | Time-taken to train(s) |
| model | Feed Forward Neural Network | 119.768 | 2.929 |
| model_k | KNN | 41.428 | 0.008 |
| model_l | Linear Regression | 23.195 | 0.063 |
| model_s | SVM | 66.345 | 0.305 |
از جدول، می توانیم چندین نتیجه گیری کنیم. با یک خطای مهم تر، آموزش مدل یادگیری عمیق نسبت به الگوریتم یادگیری ماشین زمان بیشتری را صرف کرد. این ممکن است به دلیل سادگی معماری یا فقدان داده های آموزشی باشد. مدل رگرسیون خطی کوچکترین اشتباهی را نشان می دهد که به معنای یک رابطه خطی کامل بین ورودی و متغیر هدف است. همچنین SVM بدون پارامتر منظم سازی آموزش داده شد که تقریباً همان نتیجه را نشان داد. این بدان معنی است که تمام ویژگی های مجموعه داده با متغیر هدف همبستگی دارند.
نتیجه
یادگیری عمیق چندین مزیت را نسبت به یادگیری ماشین دارد، اما نمی تواند آن را برای مسائل ساده جایگزین کرد. این مطلب مدلهای رگرسیون را با استفاده از الگوریتمهای یادگیری عمیق و یادگیری ماشین ساده ایجاد کرد. ما دیدیم که آموزش یک مدل یادگیری عمیق ممکن است هر بار از نتایج بهترین انتخاب نباشد. برای مجموعه داده ای که ما انتخاب کردیم، الگوریتم های یادگیری ماشینی ساده تر نیز عملکرد بهتری داشتند. از این رو، میتوان نتیجه گرفت که یادگیری عمیق تنها زمانی باید مورد استفاده قرار گیرد که الگوریتمهای یادگیری ماشین ساده نتوانند نتایج رضایتبخشی ارائه کنند.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

دیدگاهتان را بنویسید