
تکنیک های یادگیری ماشین برای نمایش متن در پردازش زبان طبیعی

در یان مطلب به ارائه تکنیکهایی برای نمایش متن در پردازش زبان طبیعی میپردازیم.پردازش زبان طبیعی شاخه ای از هوش مصنوعی است که با زبان انسان سر و کار دارد تا سیستمی را قادر به درک و پاسخگویی به زبان کند.دادهها که مهمترین بخش هر پروژه علم داده است باید همیشه به گونهای نمایش داده شوند که به درک و مدل سازی آسان کمک کند.
گفته میشود که وقتی ویژگیهای بسیار خوب را به مدلهای بد و ویژگیهای بد را به مدلهای بهینهسازی شده ارائه میکنیم، مدلهای بد به مراتب بهتر از یک مدل بهینهشده عمل میکنند. بنابراین در این مطلب، نحوه استخراج ویژگیهای دادههای متنی و استفاده در فرآیند مدلسازی یادگیری ماشین و اینکه چرا استخراج ویژگی از متن در مقایسه با انواع دیگر دادهها کمی دشوار است را مطالعه خواهیم کرد.
چرا استخراج ویژگی از متن دشوار است؟
تکنیک های استخراج ویژگی از داده های متنی:
- One-Hot Encoding
- Bag of words Technique
- N-Grams
- TF-IDF
مقدمه ای بر بازنمایی متن:
اولین سوالی که مطرح می شود این است که استخراج ویژگی از متن چیست؟ استخراج ویژگی یک اصطلاح کلی است که به عنوان نمایش متنی بردارسازی متن نیز شناخته می شود که فرآیند تبدیل متن به اعداد است.
حال سوال دوم این است که چرا به استخراج ویژگی نیاز داریم؟ بنابراین می دانیم که ماشین ها فقط می توانند اعداد را بفهمند و برای اینکه ماشین ها بتوانند زبان را شناسایی کنند باید آن را به شکل عددی تبدیل کنیم.
چرا استخراج ویژگی از داده های متنی دشوار است؟
اگر از هر متخصص NLP بپرسید، پاسخ مثبت خواهد بود که مدیریت داده های متنی دشوار است.
اکنون اجازه دهید ابتدا استخراج ویژگی متن را با استخراج ویژگی در انواع دیگر داده ها مقایسه کنیم.بنابراین در یک مجموعه داده تصویری فرض کنید تشخیص رقم جایی است که شما تصاویر ارقام را دارید و وظیفه پیش بینی رقم است، بنابراین در این تصویر استخراج ویژگی آسان است. زیرا تصاویر از قبل به صورت اعداد (پیکسل) وجود دارند. اگر در مورد ویژگیهای صوتی صحبت میکنیم، پیشبینی احساسات از تشخیص گفتار را فرض کنید، بنابراین در این ما دادههایی به شکل سیگنالهای شکل موج داریم که در آن ویژگیها میتوانند در بازهای زمانی استخراج شوند.
اما وقتی میگویم جملهای دارم و میخواهم احساسش را پیشبینی کنم چگونه آن را در اعداد نشان میدهی؟ یک مجموعه داده تصویر، مجموعه داده گفتار یک مورد ساده بود، اما در یک مورد داده متنی، باید کمی فکر کنید. در این مطلب قصد داریم تنها به بررسی این تکنیک ها بپردازیم.
اصطلاحات:
Corpus(C) :تعداد کل ترکیبات کلمات در کل مجموعه داده به عنوان Corpus شناخته می شود. به عبارت ساده، به هم پیوستن تمام رکوردهای متنی مجموعه داده، یک پیکره را تشکیل می دهد.
Vocabulary (V) : تعداد کل کلمات متمایز که مجموعه شما را تشکیل می دهند به عنوان Vocabulary شناخته می شوند.
Document(D) : چندین رکورد در یک مجموعه داده وجود دارد، بنابراین یک رکورد یا بررسی به عنوان یک سند نامیده می شود.
Word(W) : کلماتی که در یک سند استفاده می شوند به عنوان Word شناخته می شوند.
تکنیکهای استخراج ویژگی:
1 نمایش متن در پردازش زبان طبیعی با تکنیک One-Hot Encoding
این روش یک روش نمایش متن در پردازش زبان طبیعی است.این روش به معنای تبدیل کلمات سند شما در یک بردار V بعدی است.و با ترکیب همه اینها یک سند واحد بدست می آوریم. بنابراین در پایان یک آرایه دو بعدی داریم. این تکنیک بسیار شهودی است به این معنی که ساده است و می توانید خودتان آن را کدنویسی کنید. این مزیت One-Hot Encoding است.
اکنون برای انجام تمام تکنیکها با استفاده از پایتون، اجازه دهید به نوت بوک Jupyter برسیم و یک دیتافریم نمونه از برخی جملات ایجاد کنیم.
import numpy as np
import pandas as pd
sentences = ['Author writes on Analytics Vidhya', 'Vidhya reads and writes comment on Analytics Vidhya', 'Vidhya appreciates author']
df = pd.DataFrame({"text":sentences, "output":[1,1,0]})

اکنون میتوانیم با استفاده از کلاس از پیش ساخته شده sklearn و همچنین با استفاده از پایتون این روش را پیادهسازی کرد. پس از اجرا، هر جمله دارای یک آرایه دو بعدی شکل متفاوت خواهد بود که در تصویر نمونه زیر یک جمله نشان داده شده است.

معایب:
1) پراکندگی:می بینید که فقط یک جمله یک بردار با اندازه n*m ایجاد می کند. که n طول جمله m تعدادی کلمه منحصر به فرد در یک سند است. و 80 درصد مقادیر در یک بردار صفر است.
2) بدون اندازه ثابت: هر سند دارای طول متفاوتی است که بردارهایی با اندازه های مختلف ایجاد می کند و نمی تواند به مدل تغذیه شود.
3) معنایی را در بر نمی گیرد: ایده اصلی این است که ما باید متن را به اعداد تبدیل کنیم و در نظر داشته باشیم که معنای واقعی یک جمله باید در اعدادی مشاهده شود که در رمزگذاری یکباره دیده نمی شوند.
2 نمایش متن در پردازش زبان طبیعی با تکنیک Bag Of Words
این روش یک روش نمایش متن در پردازش زبان طبیعی است.یکی از پرکاربردترین تکنیک های برداری متن است. بیشتر در کارهای طبقه بندی متن استفاده می شود. این روش کمی شبیه به روش قبل است که در آن هر کلمه را به عنوان یک مقدار باینری وارد می کنیم. و در یک کیسه کلمات یک ردیف را نگه می داریم و تعداد کلمات را در یک سند وارد می کنیم. بنابراین ما واژگان را ایجاد می کنیم و برای یک سند، یک ورودی را وارد می کنیم که چند بار در یک سند آمده است. اجازه دهید به IDE برسیم و مدل Bag-of words را با استفاده از کلاس بردار شمارش sciket-learn پیاده سازی کنیم.
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() bow = cv.fit_transform(df['text'])
اکنون برای دیدن واژگان و برداری که ایجاد کرده است می توانید از کد زیر همانطور که در تصویر نتایج زیر نشان داده شده است استفاده کنید.
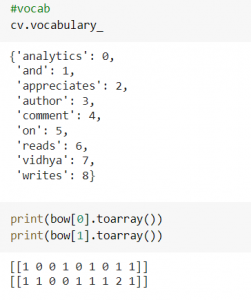
نحوه تخصیص شمارش این است که ابتدا واژگانی را بر اساس ترتیب حروف الفبا یا کلمات ایجاد می کند و سپس یک آرایه ایجاد می کند و تعداد وقوع هر عبارت را در یک سند و مکانی که در مکان مربوطه در آرایه شمارش می شود بررسی می کند. اجازه دهید در مورد مزایا و معایب این تکنیک صحبت کنیم.
مزایا:
1) ساده و شهودی: فقط چند خط کد برای پیاده سازی تکنیک مورد نیاز است.
2) بردار اندازه ثابت: مشکلی که در روش قبل مشاهده کردیم که در آن نمیتوانیم دادهها را به مدل یادگیری ماشین برسانیم زیرا هر جمله بردار اندازه متفاوتی را تشکیل میدهد اما در اینجا کلمات جدید را نادیده میگیرد و فقط کلماتی را میگیرد که واژگان آن یک بردار با اندازه ثابت ایجاد می کند.
معایب:
1) خارج از وضعیت واژگان، تعداد کلمات واژگان را حفظ میکند. بنابراین اگر کلمات جدیدی در یک جمله بیایند به سادگی آن را نادیده می گیرد و تعداد کلمات موجود در واژگان را دنبال می کند. اما اگر کلماتی که نادیده میگیرد در پیشبینی نتیجه مهم باشند، چه میشود، بنابراین این یک نقطه ضعف است، تنها فایده آن این است که خطا ایجاد نمیکند.
2) پراکندگی – وقتی دایره لغات زیادی داریم و سند حاوی چند عبارت تکرار شده است، یک آرایه پراکنده ایجاد می کند.
3) در نظر نگرفتن ترتیب یک مسئله است، تخمین معنایی سند دشوار است.
3 نمایش متن در پردازش زبان طبیعی با تکنیک N-Grams
این روش یک روش نمایش متن در پردازش زبان طبیعی است.تمام تکنیکهایی که تا به حال آن را خواندهایم از یک کلمه تشکیل شدهاند و نمیتوانیم از آنها استفاده کنیم یا برای درک بهتر از آنها استفاده کنیم. بنابراین تکنیک N-Gram این مشکل را حل می کند و واژگان را با کلمات متعدد می سازد. وقتی یک تکنیک N-gram ساختیم، باید تعریف کنیم که مثل bigram، trigram و غیره میخواهیم. بنابراین وقتی N-gram را تعریف میکنید و اگر امکانش وجود نداشته باشد، یک خطا ایجاد میکند. اجازه دهید بیگرام را امتحان کنیم و خروجی ها را مشاهده کنیم.
#Bigram model from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(ngram_range=[2,2]) bow = cv.fit_transform(df['text'])

میتوانید trigram را با محدودهای مانند [3،3] امتحان کنید و با محدوده N امتحان کنید تا به وضوح بیشتری در مورد تکنیک دست پیدا کنید و سعی کنید یک سند جدید را تغییر دهید و عملکرد آن را مشاهده کنید.
مزایا:
1) قادر به گرفتن معنای معنایی جمله است .همانطور که از Bigram یا trigram استفاده می کنیم، دنباله ای از جملات را می گیرد که یافتن رابطه کلمه را آسان می کند.
2) پیاده سازی آن شهودی و آسان است.
معایب:
1) با حرکت از یونیگرام به N-گرم، بعد تشکیل بردار یا دایره لغات افزایش مییابد که در نتیجه محاسبه و پیشبینی کمی زمان بیشتری میبرد.
2) راه حلی برای اصطلاحات خارج از واژگان وجود ندارد. ما راهی جز نادیده گرفتن کلمات جدید در یک جمله جدید نداریم.
4 نمایش متن در پردازش زبان طبیعی با تکنیک
TF-IDF (Term Frequency and Inverse Document Frequency)
این روش یک روش نمایش متن در پردازش زبان طبیعی است.این تکنیک مانند تکنیک های فوق کار نمی کند. این روش به هر کلمه در یک سند مقادیر (وزن) متفاوتی می دهد. ایده اصلی تخصیص وزن کلمه ای است که چندین بار در یک سند ظاهر می شود اما ظاهر نادری در مجموعه دارد، بنابراین برای آن سند بسیار مهم است بنابراین وزن بیشتری به آن کلمه می دهد. این وزن با دو عبارت معروف به TF و IDF محاسبه میشود. بنابراین برای یافتن وزن هر کلمه، TF و IDF را پیدا کرده و هر دو عبارت را ضرب می کنیم.
Term Frequency(TF): به تعداد دفعات تکرار یک کلمه در یک سند تقسیم بر تعداد کل عبارات یک سند گفته می شود. به عنوان مثال، من باید فرکانس ترم افراد را در جمله زیر پیدا کنم، سپس 1/5 می شود. می گوید که یک کلمه خاص در یک سند خاص چقدر تکرار می شود.
People read on Analytics Vidhya
Inverse Document Frequency : به تعداد کل اسناد موجود در مجموعه تقسیم بر تعداد کل اسناد دارای عبارت T در آنها و گرفتن گزارش یک کسر کامل،گفته میشود. اگر کلمه ای داشته باشیم که در تمام اسناد آمده باشد، خروجی حاصل از log صفر است اما در پیاده سازی sklearn از پیاده سازی کمی متفاوت استفاده می کند زیرا اگر صفر شود، سهم کلمه نادیده گرفته می شود. بنابراین یک در نتیجه اضافه می کنند و به همین دلیل می توانید مقادیر TFIDF را کمی بالا مشاهده کنید. اگر کلمه ای فقط یک بار بیاید، IDF بالاتر خواهد بود.
from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer() tfidf.fit_transform(df['text']).toarray()
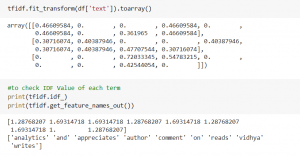
بنابراین یک اصطلاح تعداد دفعات تکرار این اصطلاح را پیگیری می کند، در حالی که اصطلاح دیگر به ندرت این اصطلاح را دنبال می کند.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

تاثیر هایپرپارامترها در مدل یادگیری عمیق
دیدگاهتان را بنویسید