
یادگیری تقویتی: فرایند تصمیم گیری مارکوف (قسمت 1)
یادگیری تقویتی (RL)
در یک مسئله معمول یادگیری تقویتی (RL)، یک زبان آموز و تصمیم گیرنده به نام عامل وجود دارد و محیطی که با آن تعامل دارد محیط نامیده می شود. در عوض، محیط پاداش و وضعیت جدیدی را بر اساس اقدامات عامل ارائه می دهد. بنابراین، در یادگیری تقویتی، ما به یک عامل نمی آموزیم که چگونه باید کاری را انجام دهد، بلکه بر اساس عملکردهای آن، پاداشهای مثبت یا منفی به او می دهیم. بنابراین سوال اصلی ما این است که چگونه هر مسئله ای را در RL به صورت ریاضی تدوین می کنیم. اینجاست که فرایند تصمیم گیری مارکوف (MDP) مطرح می شود.
تعاریف رسمی
قبل از اینکه به سوال اصلی خود پاسخ دهیم، یعنی چگونه مسائل RL را به صورت ریاضی (با استفاده از MDP) تدوین می کنیم، باید شهود خود را در مورد موارد زیر توسعه دهیم:
- رابطه عامل و محیط
- ویژگی مارکوف
- فرآیند مارکوف و زنجیره مارکوف
- فرآیند پاداش مارکوف (MRP)
- معادله بلمن
عامل و محیط
ابتدا اجازه دهید برخی از تعاریف رسمی را بررسی کنیم:
عامل: برنامه های نرم افزاری که تصمیمات هوشمندانه ای می گیرند و در RL زبان آموزان هستند. این عوامل با اقدامات با محیط ارتباط برقرار می کنند و بر اساس اقدامات موجود پاداش دریافت می کنند.
محیط: این نشان دهنده مسئله است که باید حل شود. محیط واقعی یا یک محیط شبیه سازی شده است که عامل ما با آن تعامل دارد.
حالت: این موقعیت عامل ها در یک مرحله زمانی خاص در محیط است. بنابراین، هر زمان که یک عامل اقدامی انجام دهد، محیط به پاداش و وضعیت جدیدی رسیده است.
رابطه عامل و محیط
هر چیزی که عامل نمی تواند تغییر دهد، بخشی از محیط محسوب می شود. به زبان ساده، اقدامات می توانند هر تصمیمی باشند که ما می خواهیم عامل یاد بگیرد و بیان کند. همه چیز در محیط برای عامل ناشناخته نیست. محاسبه پاداش به عنوان بخشی از محیط در نظر گرفته می شود، حتی اگر عامل کمی در مورد نحوه محاسبه پاداش آن به عنوان تابعی از عملکردها و حالات خود آگاه باشد. پاداش ها نمی توانند به طور دلخواه توسط عامل تغییر کنند. گاهی اوقات، ممکن است عامل به طور کامل از محیط خود آگاه باشد، اما باز هم به حداکثر رساندن پاداش برای ما دشوار است. همانطور که ما می دانیم چگونه مکعب روبیک را بازی کنیم اما هنوز نمی توانیم آن را حل کنیم. بنابراین، با اطمینان می توان گفت که رابطه عامل و محیط نشان دهنده حد کنترل عامل است و دانش آن نیست.
ویژگی مارکوف
گذار: انتقال از یک حالت به حالت دیگر ، گذار نامیده می شود.
احتمال گذار: احتمال اینکه عامل از حالتی به حالت دیگر حرکت کند احتمال گذار نامیده می شود.
در ویژگی مارکوف آمده است:
“آینده با توجه به زمان حال مستقل از گذشته است”
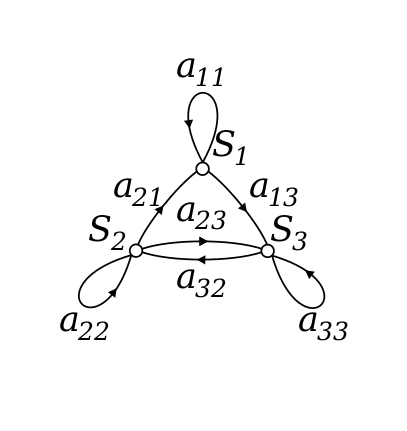
فرآیند مارکوف یا زنجیره مارکوف
فرایند مارکوف یک فرآیند تصادفی کم حافظه است. دنباله ای از حالت تصادفی S [1] ، S [2] ،… .S [n] با ویژگی Markov است. این را می توان با استفاده از مجموعه ای از حالتها تعریف کرد ( S) و ماتریس احتمال انتقال (P). پویایی محیط را می توان با استفاده از ماتریس State (S) و احتمال انتقال (P) به طور کامل تعریف کرد.
قبل از رفتن به فرایند پاداش مارکوف ، برخی مفاهیم مهم را که در درک MRP ها به ما کمک می کند ، بررسی کنیم.
پاداش و بازه
پاداشها مقادیر عددی هستند که عامل هنگام انجام برخی اقدامات در برخی از حالتها در محیط دریافت می کند. مقدار عددی بر اساس اقدامات عامل می تواند مثبت یا منفی باشد.
در یادگیری تقویتی، ما به حداکثر رساندن پاداش تجمعی (همه عوامل پاداش از محیط) اهمیت می دهیم، به جای این که عامل پاداش از وضعیت فعلی دریافت کند (که به آن پاداش فوری نیز گفته می شود). به مجموع پاداشی که عامل از محیط دریافت می کند ، بازده گفته می شود.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

دیدگاهتان را بنویسید