
الگوریتم kNN – یک مدل ML مبتنی بر نمونه برای پیش بینی بیماری قلبی
معرفی
یادگیری مبتنی بر نمونه (Instance-based) یک جنبه مهم از یادگیری ماشینی نظارت شده است. در این روش به جای اینکه کل داده ها را با یک الگوریتم تبدیل به چند پارامتر کند که مفهوم یادگیری را در دل خودشان داشته باشند باید تمام داده ها را در دیتا بیسی ذخیره کرده و نقطه جدید را با توجه به داده هایی که دارد پیش بینی کند.
برای حل وظایف تقریبی توابع هدف واقعی یا با ارزش گسسته است. روش کار این الگوریتم این است که نمونههای آموزشی ذخیره میشوند و زمانی که نمونه آزمایشی تغذیه میشود، نزدیکترین تطابقها پیدا میشوند. یادگیری مبتنی بر نمونه به عنوان یادگیری مبتنی بر حافظه شناخته می شود. نمونههایی از این حالت یادگیری شبکههای kNN، RBF و kernel machines هستند. در این مقاله، kNN را مورد بحث قرار خواهیم داد.
الگوریتم kNN
الگوریتم KNN (k نزدیکترین همسایه – K-nearest neighbors) از الگوریتم های یادگیری ماشین تحت نظارت است که در مسائل طبقه بندی و رگرسیون مورد استفاده قرار می گیرد. kNN اغلب به عنوان الگوریتم یادگیری تنبل شناخته می شود زیرا تا زمانی که نداند دقیقاً چه چیزی و از چه نوع متغیرهایی باید پیش بینی شود، کاری انجام نمی دهد. این یک ابزار اعتبارسنجی متقابل بسیار کارآمد است. برای بسیاری از کاربران، یک روش یادگیری قابل درک است.
اساس طبقه بندی الگوریتم kNN
- نمونه های آموزشی را ذخیره می کند.
- در طول زمان پیشبینی،در میان ذاده های آموزشی ذخیره شده k نمونه آموزشی نزدیک به نمونه آزمایشی x را پیدا می کند و بر اساس آن مقدار X را پیش بینی می کند. از معیار فاصله یا شباهت، برای پیداکردن k همسایه نزدیک استفاده میشود.
ریاضیات الگوریتم kNN
فاصله اقلیدسی یکی از معیارهای رایج برای محاسبه است که به نوبه خود برای یافتن kNN و پیش بینی استفاده می شود.
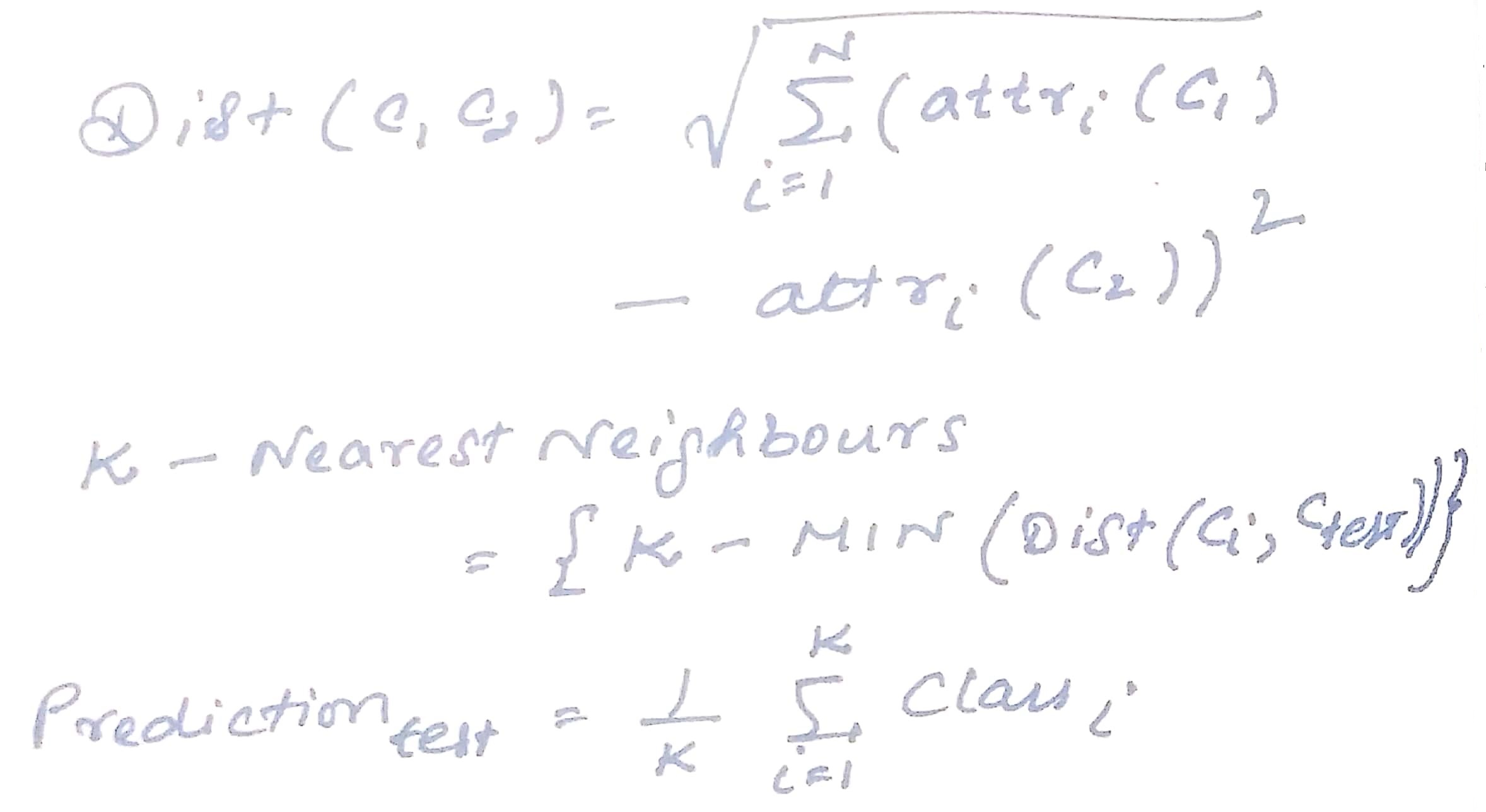
اهمیت k و انتخاب مقدار k
“k” تعداد نزدیکترین همسایه ها را نشان می دهد.
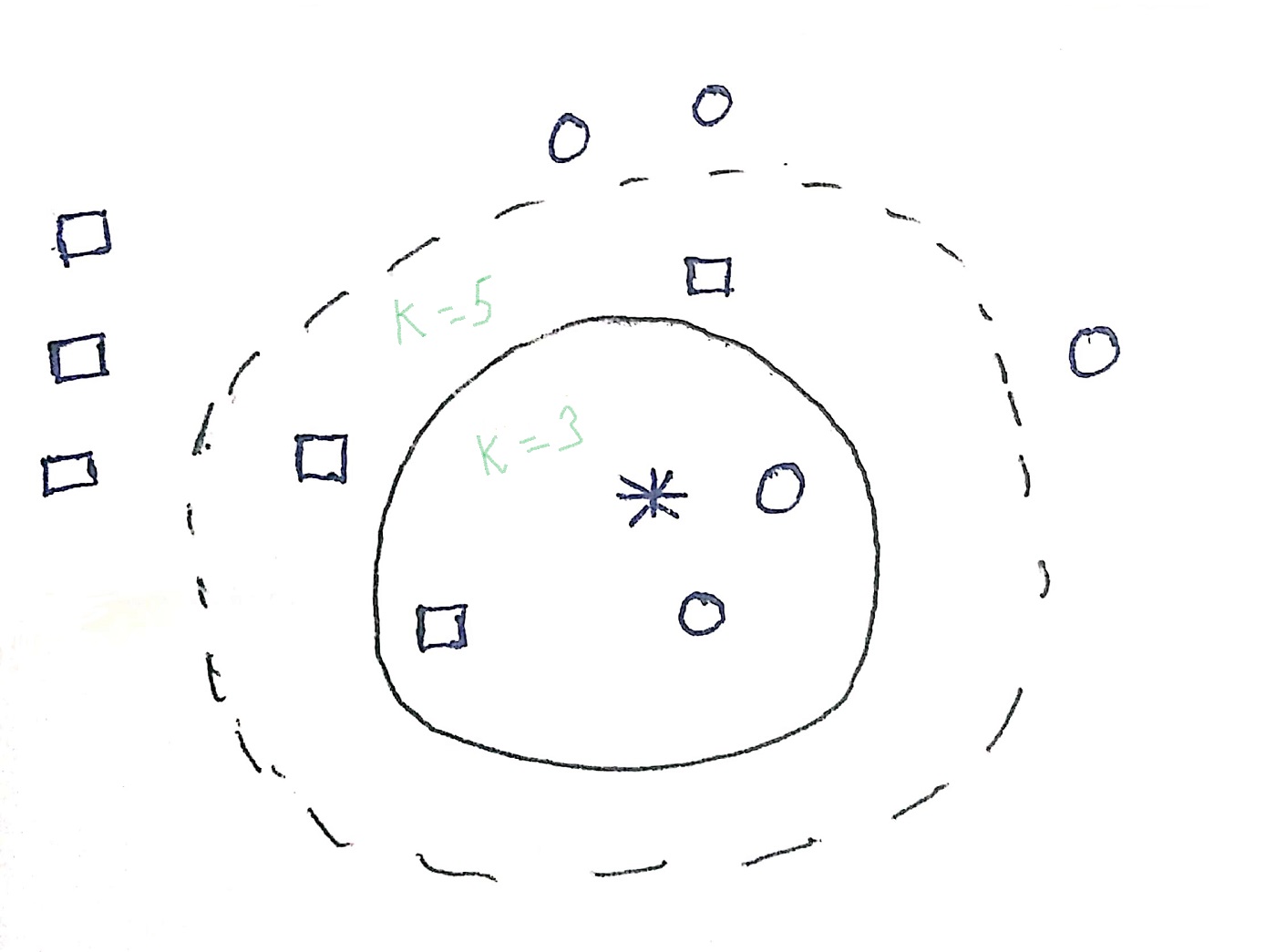
در تصویر بالا چند دایره و چند مربع که را می بینیم. ستاره نمونه آزمایشی است که باید طبقه بندی شود. اگر k=3 باشد، ستاره به کلاس دایره اختصاص داده می شود زیرا 2 دایره و 1 مربع وجود دارد. در مثالی دیگر، اگر k=5 باشد، 3 مربع و 2 دایره وجود دارد بنابراین ستاره در کلاس مربع طبقه بندی می شود. به این ترتیب طبقه بندی kNN انجام می شود. مقدار ‘k’ باید با دقت انتخاب شود و اثرات مقدار خیلی بزرگ و خیلی کوچک ‘k’ در زیر مشخص شده است.
انتخاب مقدار K بزرگ
- حساسیت کمتری نسبت به نویز.
- برآورد احتمال بهتر برای کلاس های گسسته.
- مجموعه های آموزشی بزرگتر مقادیر زیاد k را امکان پذیر می کند.
انتخاب مقدار k کوچکتر
- ساختار خوب. فضای مشکل را بهتر به تصویر می کشد.
- به مجموعه های آموزشی کوچک نیاز دارد.
تفاوت بین انتخاب مقادیر مختلف k در تصاویر زیر نشان داده شده است
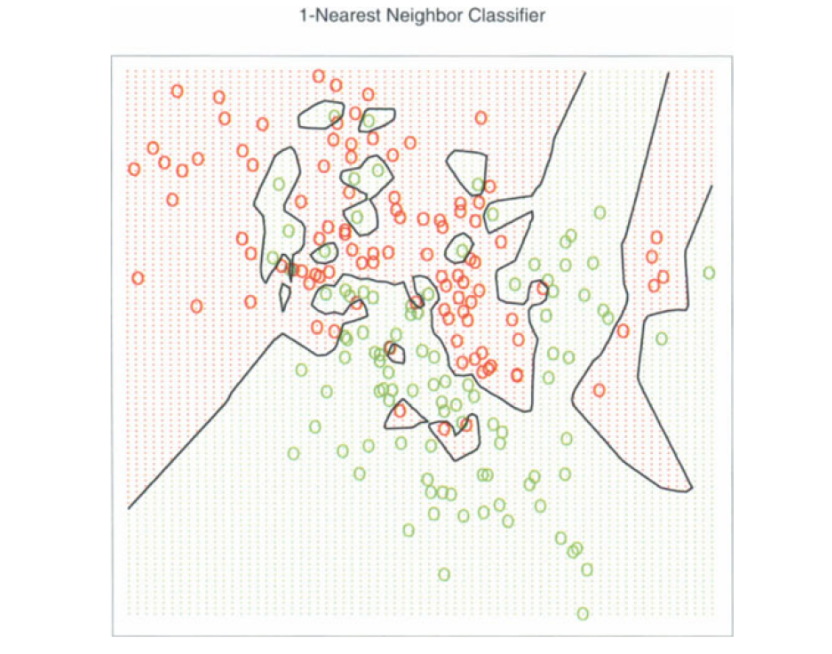
 تغییر مرزهای کلاسها با انتخاب k
تغییر مرزهای کلاسها با انتخاب kهمانطور که از تصاویر مشهود است، با افزایش مقدار k، مرزهای کلاسها روانتر میشود. با افزایش k به سمت بینهایت، بسته به اکثریت مطلق نمونهها در نهایت یک کلاس سبز یا قرمز وجود خواهد داشت.
انتخاب k باید با دقت ایجاد شود. از آنجایی که مبادله بین k کوچک و بزرگ می تواند دشوار باشد، دو رویکرد وجود دارد که می تواند مبادله را تسهیل کند.
1. Distance weighted kNN

2. Locally weighted averaging

عرض کرنل اندازه همسایگی را کنترل می کند که تأثیر زیادی بر مقادیر دارد.
کاربرد صنعتی الگوریتم kNN
- سیستم توصیهکننده – آمازون محصولاتی را از طریق ابزارهای بازاریابی هدفمند توصیه میکند. محصولاتی را بر اساس تاریخچه جستجو و علاقهمندیهایی که ما به احتمال زیاد خریداری میکنیم، توصیه میکند.
- جستجوی مفهومی – اسناد مشابه معنایی را جستجو می کند. با تولید دادهها در هر ثانیه، هر سند داده میتواند حاوی مفاهیم بالقوه باشد. تشخیص تصویر، تشخیص دست خط و طبقه بندی بیماری، جستجوهای مفهومی مهمی هستند.
الگوریتم kNN با استفاده از مجموعه داده های بیماری قلبی پایتون
تشخیص بیماری قلبی با الگوریتم Knn
numpy as np import pandas as pd import matplotlib.pyplot as plt
ابتدا پکیج های numpy، pandas و matplotlib.pyplot را وارد می کنیم.
df=pd.read_csv('heart.csv')
df یک dataframe است که مجموعه داده «قلب» در آن بارگذاری می شود.
df.head()
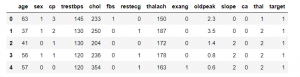
df.shape df.info()
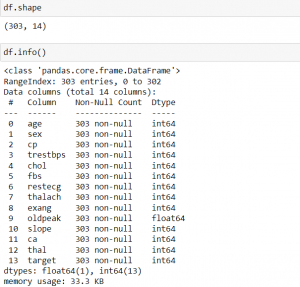
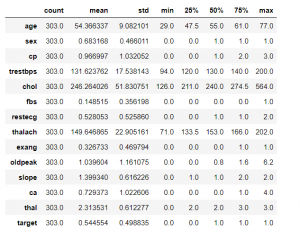
df.describe().T
df.isnull().sum()
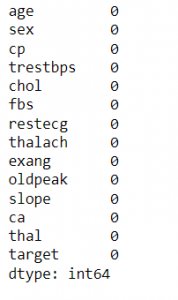
پس از بارگذاری مجموعه داده، از تابع head() برای خواندن 5 ردیف اول مجموعه داده استفاده شده، تابع shape برای یافتن تعداد سطرها و ستون ها استفاده می شود، در این حالت 303 سطر و 14 ستون است. تابع info() اطلاعاتی در مورد انواع داده ها، ستون ها، شمارش مقادیر تهی، استفاده از حافظه و … می دهد. سپس از تابع describe() برای تولید آمار توصیفی مجموعه داده استفاده شده است. T برای جابجایی نمایه و ستون های دیتافریم df است. برای اطمینان از تمیز بودن مجموعه داده، از تابع isnull() استفاده کرده و متوجه شدیم که مقدار null وجود ندارد.
import seaborn as sns sns.pairplot(df,hue='target')
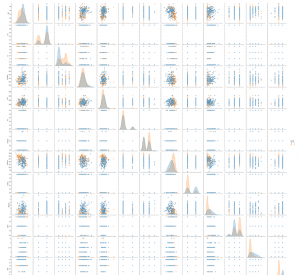
کتابخانه seaborn را برای تجسم داده ها بر اساس matplotlib وارد و یک نمودار زوجی ایجاد شده.
plt.figure(figsize=(14,12)) sns.heatmap(df.corr(), annot=True,cmap ='RdYlGn')

برای یافتن رابطه بین 2 کمیت، از ضریب همبستگی پیرسون استفاده کرده.همچنین، از یک heatmap برای تولید نمایش دو بعدی اطلاعات با استفاده از رنگ ها استفاده کرده است.
from sklearn.preprocessing import StandardScaler
X = pd.DataFrame(StandardScaler().fit_transform(df.drop(['target'],axis = 1),),
columns=['age', 'sex', 'cp', 'trestbps', 'chol','fbs', 'restecg', 'thalach','exang','oldpeak','slope','ca','thal'])
X.head()

standard scaler را از کتابخانه یادگیری ماشینی scikit-learn وارد شده. مقیاسگذاری دادهها برای kNN مهم است، زیرا برای اعمال الگوریتمهای مبتنی بر فاصله، آوردن همه ویژگیها به یک مقیاس توصیه میشود.
X = df.drop('target',axis=1).values
y = df['target'].values
from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.35,random_state=5)
from sklearn.neighbors import KNeighborsClassifier
neighbors = np.arange(1,14) train_accuracy =np.empty(len(neighbors)) test_accuracy = np.empty(len(neighbors))
for i,k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
train_accuracy[i] = knn.score(X_train, y_train)
test_accuracy[i] = knn.score(X_test, y_test)
plt.title('k-NN Varying number of neighbors')
plt.plot(neighbors, test_accuracy, label='Testing Accuracy')
plt.plot(neighbors, train_accuracy, label='Training accuracy')
plt.legend()
plt.xlabel('Number of neighbors')
plt.ylabel('Accuracy')
plt.show()
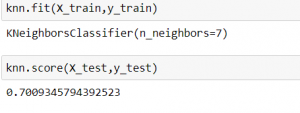
train_test_split را از scikit-learn وارد کرده تا دادهها را به مجموعه دادههای train و test تقسیم کند.سپس با استفاده از الگوریتم k-Nearest Neighbors یک طبقه بندی کننده ایجاد کرده. در نهایت دقتها را با مقادیر مختلف k مشاهده کردیم و مشاهده میشود که با k=7 بیشترین دقت تست نشان داده میشود.
knn = KNeighborsClassifier(n_neighbors=7) knn.fit(X_train,y_train) knn.score(X_test,y_test)
from sklearn.metrics import confusion_matrix,accuracy_score y_pred = knn.predict(X_test) confusion_matrix(y_test,y_pred)

Confusion matrix یا error matrix جدولی است که مقادیر پیشبینیشده درست را مشخص میکند و بهعنوان مثبت درست، منفی درست، مثبت کاذب و منفی کاذب طبقهبندی میشود.
- نمونه عضو دسته مثبت باشد و عضو همین کلاس تشخیص داده شود (مثبت صحیح یا True Positive)
- نمونه عضو کلاس مثبت باشد و عضو کلاس منفی تشخیص داده شود (منفی کاذب یا False Negative)
- نمونه عضو کلاس منفی باشد و عضو همین کلاس تشخیص داده شود (منفی صحیح یا True Negative)
- و در نهایت، نمونه عضو کلاس منفی باشد و عضو کلاس مثبت تشخیص داده شود (مثبت کاذب یا False Positive)
pd.crosstab(y_test, y_pred, rownames=['True'], colnames=['Predicted'], margins=True)
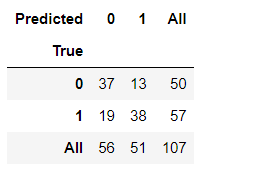
در خروجی بالا، 0 به عدم وجود بیماری قلبی و 1 به وجود بیماری قلبی اشاره دارد. 37 یعنی 0~0 به معنای منفی واقعی است. 38 یعنی 1~1 به معنای مثبت واقعی است. 13 یعنی 0~1 به معنای مثبت کاذب و 19 یعنی 1~0 به معنای منفی کاذب هستند. یعنی از 107 نمونه، 75 نمونه به درستی طبقه بندی شده اند و بقیه به اشتباه طبقه بندی شده اند.
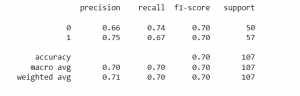
from sklearn.metrics import classification_report print(classification_report(y_test,y_pred))
 نتیجه
نتیجه
الگوریتم kNN یک الگوریتم یادگیری نظارت شده مفید نه تنها برای سیستم های توصیه کننده بلکه برای طبقه بندی بیماری ها است. این الگوریتم می تواند به پزشکان کمک کند تا وجود یا عدم وجود بیماری را به درستی تشخیص دهند.درک الگوی رفتار مصرف کننده برای تحلیلگران بازاریابی مهم است.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

تاثیر هایپرپارامترها در مدل یادگیری عمیق

دیدگاهتان را بنویسید