
پیش بینی دیابت با استفاده از یادگیری ماشین در پایتون

نحوه استفاده از یادگیری ماشین برای کمک به پیش بینی دیابت با استفاده از زبان برنامه نویسی پایتون
الگوریتمهای یادگیری ماشین عملکرد بسیار خوبی در خودکارسازی برخی از کارها یا پیش بینی بیماریها دارند.
این پروژه به طور خالصه شامل موارد زیر است:
گام اول : وارد کردن مجموعه داده ی diabetes
گام دوم: تحلیل آماری مجموعه داده
گام سوم : پیش پردازش اولیه ی انجام شده بر روی مجموعه ی داده diabetes
گام چهارم : تقسیم داده های مجوعه، به دو بخش داده های آموزشی و داده های آزمون
گام پنجم: پیاده سازی مدل یادگیری ماشین، و استفاده از الگوریتمMLP
گام ششم : ارزیابی نتایج به دست آمده )از لحاظ دقت(
گام هفتم : استفاده از دو ویژگی مناسب، نسبت به سایر ویژگی ها و ارزیابی دقت شبکه فقط با این دو ویژگی
گام هشتم : بدست آوردن مقادیر مثبت صحیح، مثبت کاذب، منفی صحیح و منفی کاذب با استفاده از دو ویژگی انتخاب
شده از گام هفتم.
تشریح پروژه
قبل از انجام هریک از گام ها، ابتدا کتابخانه های مورد نیاز را وارد میکنیم.
پکیجهای Numpy ،Pandas ،sklearn, Matplotlibو Seaborn برای شروع یادگیری دادهکاوی با پایتون بسیار ضروری
است
گام اول
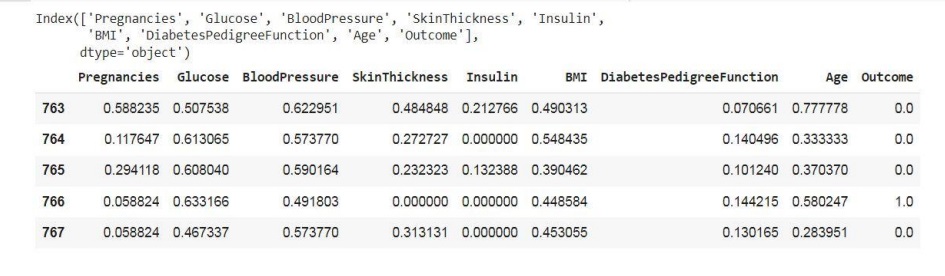
در مجموعه داده بیماران دیابتی، اطلاعات 768 بیمار ثبت شده است. که برای هر بیمار، 8 ویژگی شامل :
Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, Ageدر نظر داریم.
ستون آخر با نام Outcome ،خروجی هر یک از این نمونه ها می باشدکه برچسب 1 به این معنا است که تست دیابتفرد موردنظر، مثبت شده است. و برچسب 0 به این معنا است
که تست فرد مورد نظر، منفی شده است.
متد ()head
پنج داده ی ابتدا از مجموعه داده نمایش می دهد.

گام دوم
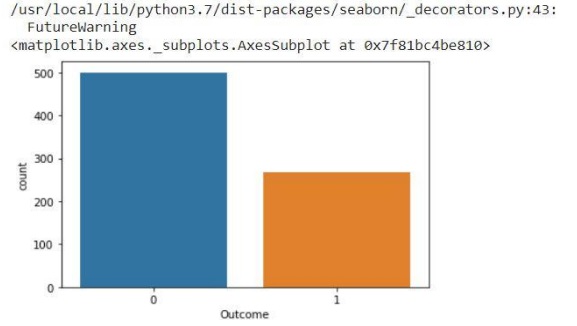
با استفاده از متد shape می توان تعداد سطر و ستون ها را نمایش داد. در اینجا متد groupby بر روی ستون خروجی اعمال شده است و نشان دهنده ی این می باشد که 268 نمونه از 768 نمونه،
دیابت دارند . و 500 نمونه از 768 نمونه، دیابت ندارند.
در این قسمت نیز تعداد نمونه های دیابتی به رنگ نارنجی و تعداد نمونه های غیردیابتی با رنگ آبی نشان داده شده است.
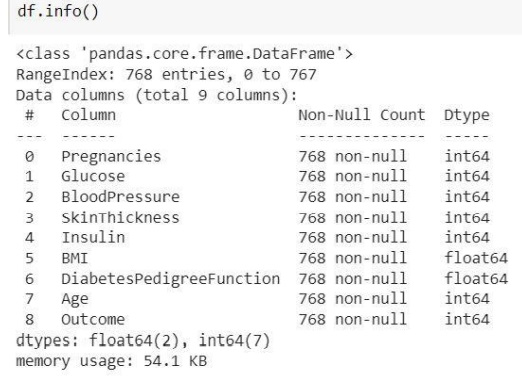
متد info نشان دهنده ی توصیفی از داده های می باشد. به طور مثال تعداد سطر و ستون ها، نوع داده ها ، مقدار خالی بودن یا نبودن جدول داده ها را نشان می دهد.
که در اینجا میبینم که در هیچ ستونی مقدار null نداریم
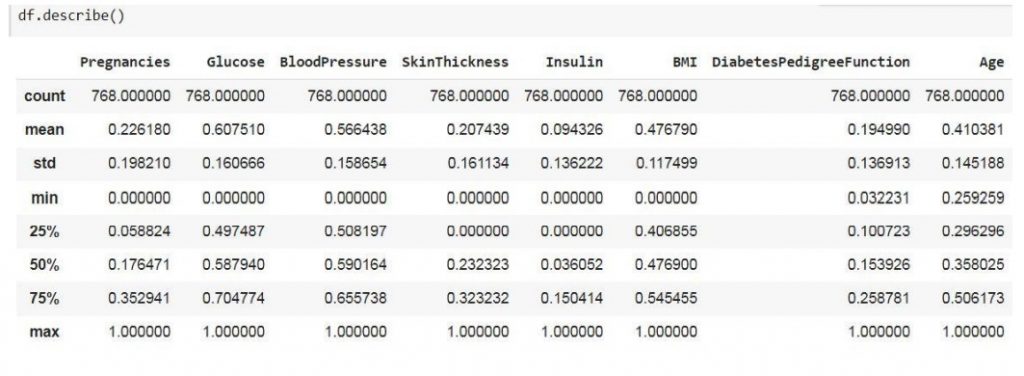
متد describe تعداد هر نمونه، میانگین، 25%و و ، 75% ، 50% مینیمم و ماکسیمم برای هر نمونه را مشخص می کند.
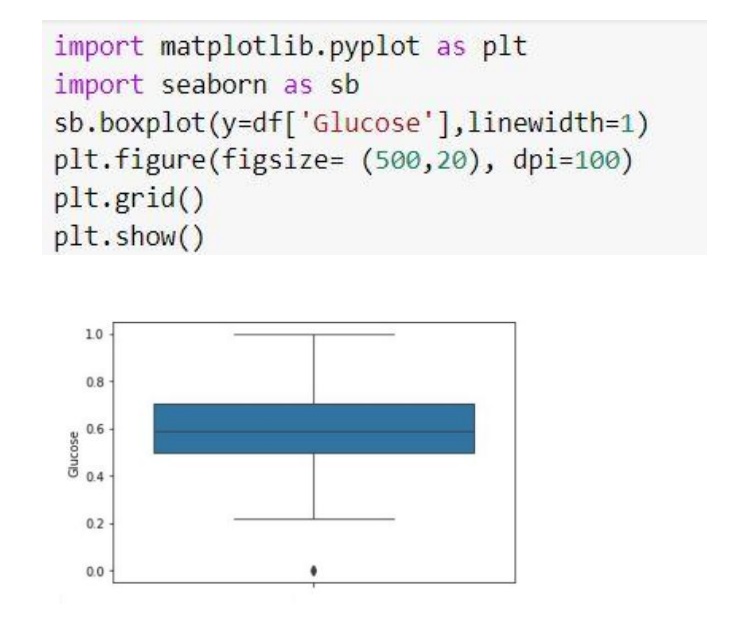
متد hist درصد فراوانی هر ویژگی را نشان می دهد.

در اینجا بعنوان مثال، محدوده مقدار ویژگی گلوکز نشان داده شده است. داده ی خارج از محدوه به صورت نقطه ای در پایین شکل نشان داده شده است.
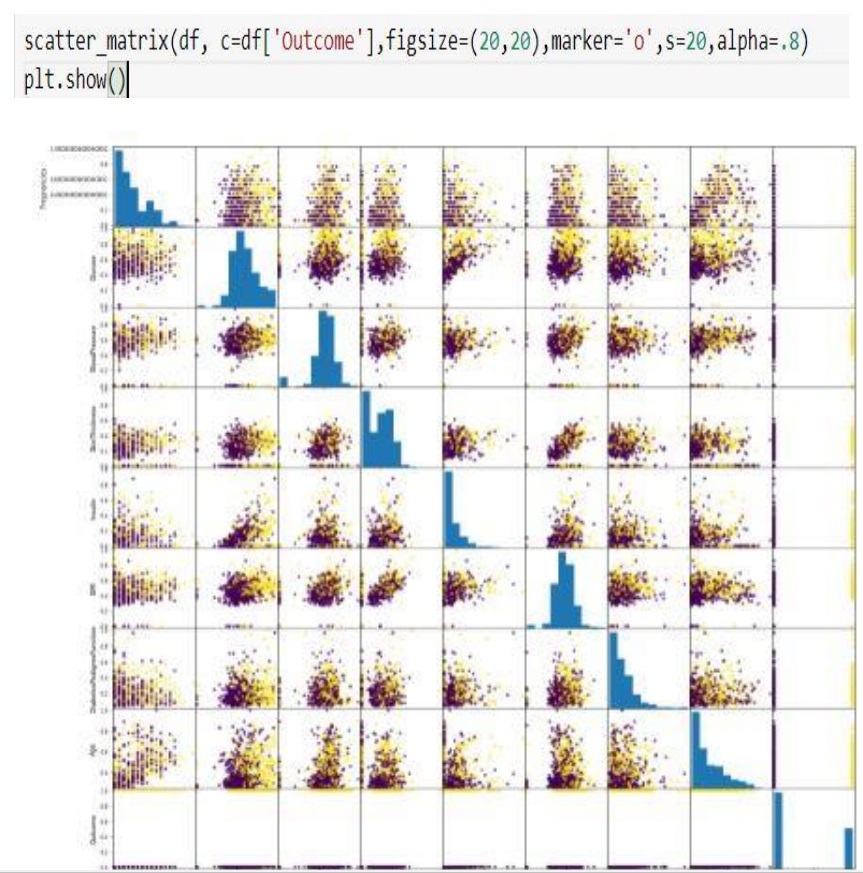
نمودار scatter نمونه ها را در فضای دو بعدی ویژگی ها ، نشان می دهد. قطر اصلی، نشان دهنده ی هیستوگرام هر ویژگی، با خودش می باشد. از این همبستگی می توان نتیجه
گرفت که دو ویژگی گلوکوز و BMI نسبت به بقیه همبستگی بیشتری دارند.
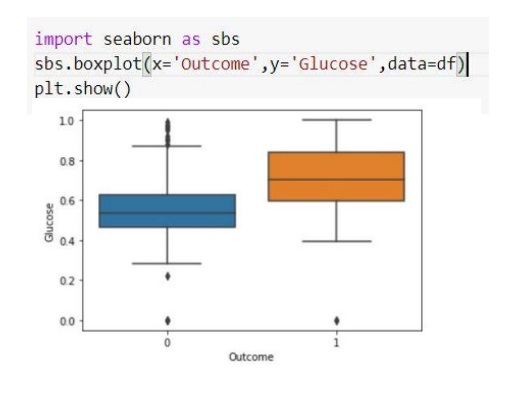
تابع seaborn برای نشان دادن overlab می باشد. که ما در اینجا برای مثال دو ویژگی گلوکز و BMI را بررسی می کنیم.
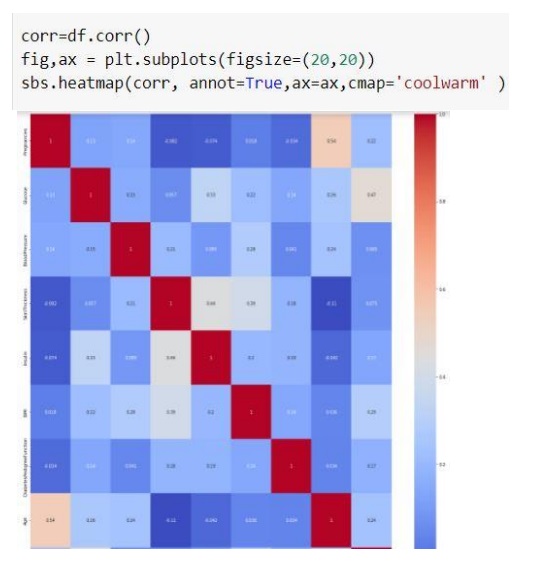
کورولوشن را با نمودار گرمایی نشان می دهیم و ویژگی هایی که همبستگی بیشتری باهم دارند پررنگ تر می باشد.
گام سوم: پیش پردازش داده ها که برای نرماالیز، از این فرمول استفاده شده است.
Feature (new)= Feature(old)/Feature (old)*max

گام چهارم:
تقسیم مجموعه داده به دوقسمت ، Trainو ،Test که در اینجا 80 %داده ها برای آموزش و 20 %داده ها برای تست در نظر گرفته شده است.

گام پنجم و گام ششم
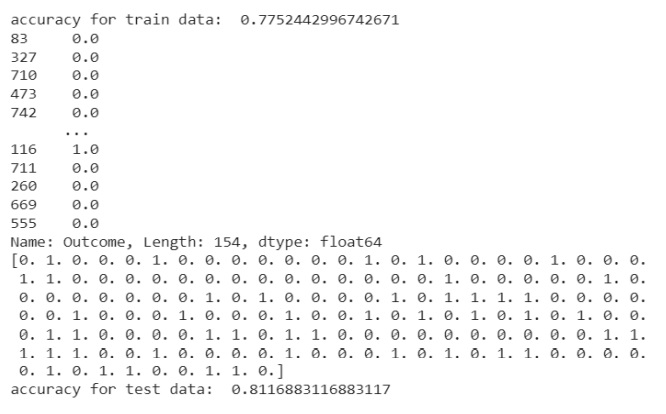
شبکه عصبیMLP را پیاده سازی میکنیم. در اینجا تعداد الیه های مخفی، تعداد دورها)epoch )را مشخص می کنیم. بعنوان مثال در اینجا دو الیه مخفی داریم اولین الیه شامل 8 نرون
و دومین الیه شامل5 نرون می باشد. که دقت شبکه برای داده ها با این حالت به صورت زیر بدست آورده است.

در اینجا دقت برای داده های آموزش، 77.0 و برای داده های تست، 81.0

در اینجا با استفاده از الگوریتمKNN مقدار دقت و مقدار مثبت صحیح، مثبت کاذب، منفی صحیح و منفی کاذب را بدست می آوریم.
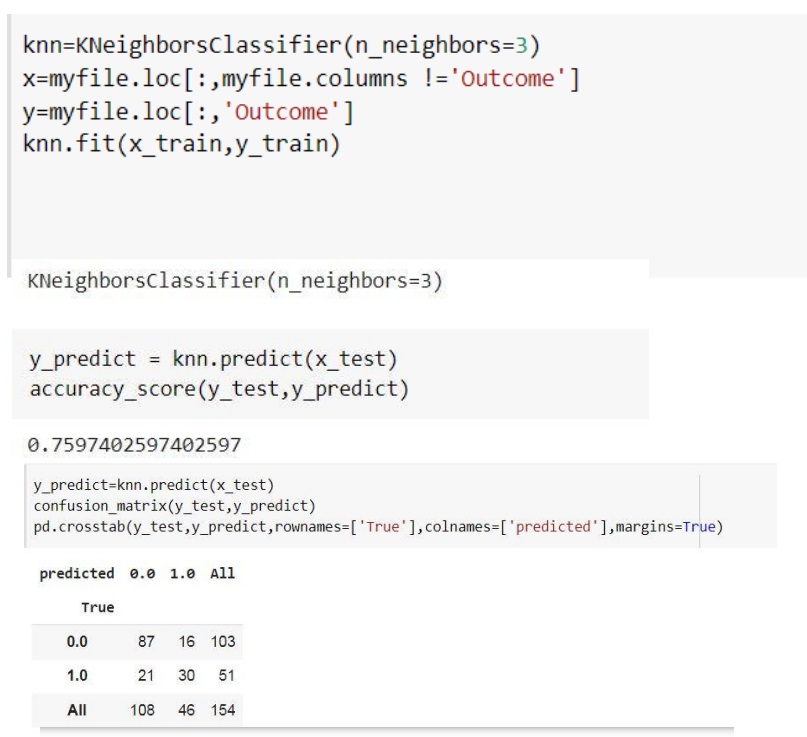
و در اینجا یک آرایه می دهیم و شبکه به ما نشان می دهد که به کدام نمونه شبیه تر می باشد.

شبکه را برای حالت های مختلف بررسی می کنیم.

گام هفتم
این بار شبکه را با دو ویژگی ” گولوکز” و “BMI”که نسبت به بقیه ویژگی ها مناسب تر هستند را از لحاظ دقت بررسی میکنیم.
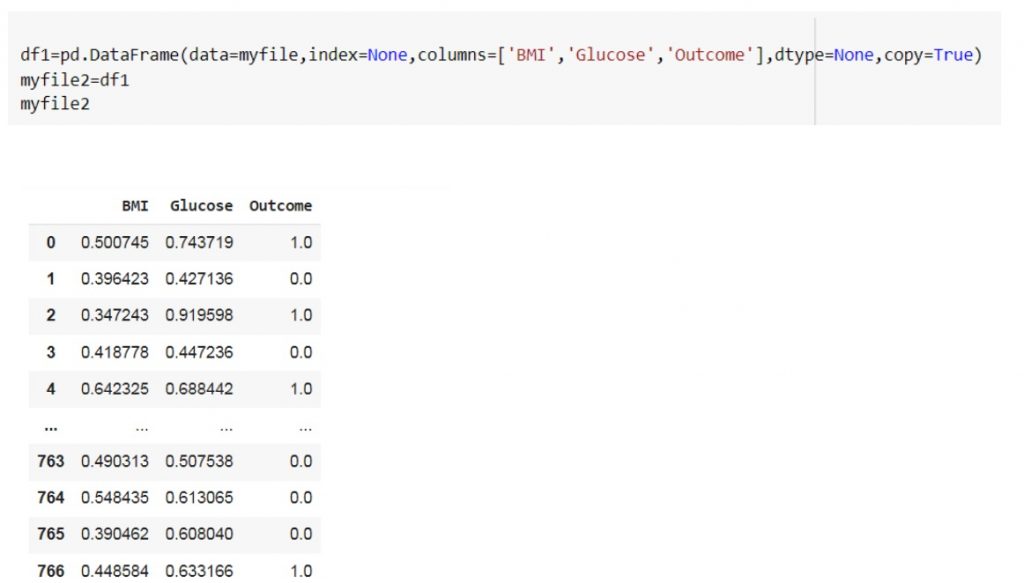
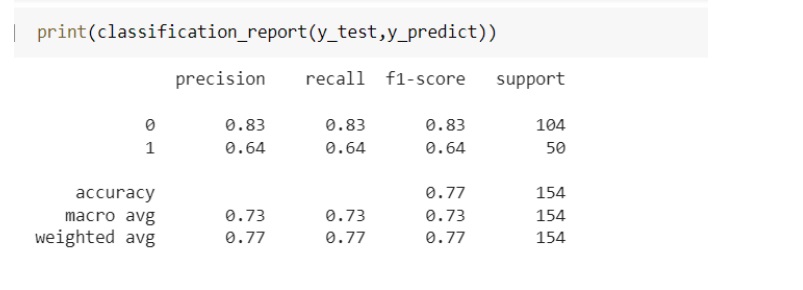
گام هشتم
با استفاده از دو ویژگی انتخاب شده در گام هفتم ، مقادیر مثبت صحیح، مثبت کاذب، منفی صحیح و منفی کاذب را بدست می آوریم .
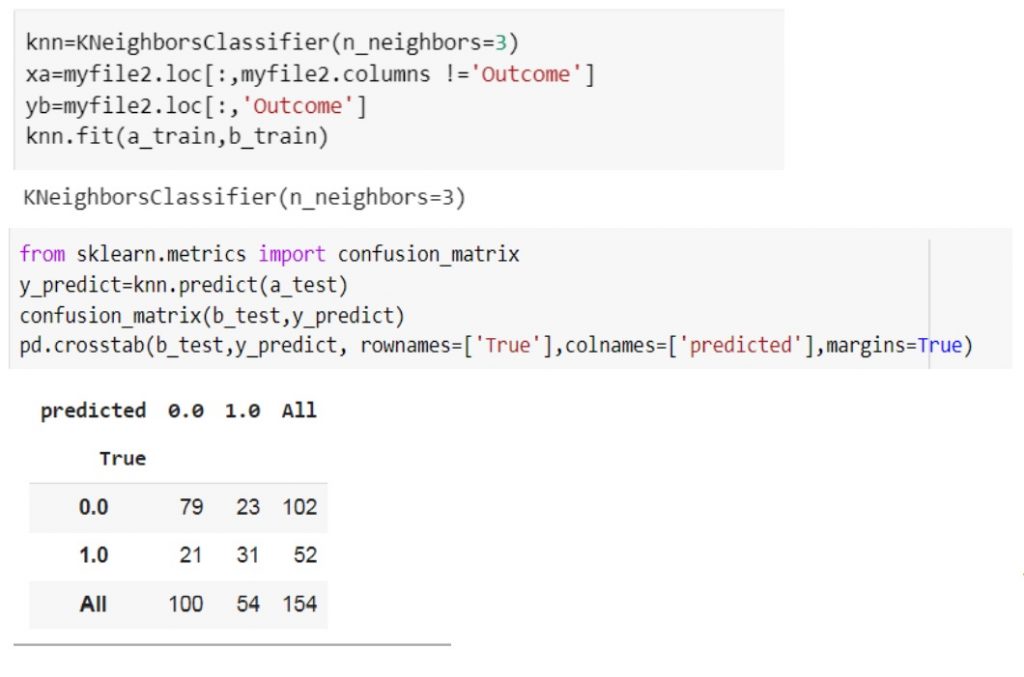
نشان می دهد که از تعداد 20 درصد از داده ها
تعداد کل نمونه های 0و 1 = 154
مثبت صحیح : 31
مثبت کاذب : 23
منفی صحیح :79
منفی کاذب: 2
موفق باشید
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

ذخیره و بارگذاری مدل در پایتون
دیدگاهتان را بنویسید