
تاثیر هایپرپارامترها در مدل یادگیری عمیق

مقدمه: تاثیر هایپرپارامترها در مدل یادگیری عمیق
یک شبکه عصبی عمیق از چندین لایه تشکیل شده است: یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی. برای توسعه هر مدل یادگیری عمیق، باید در مورد بهینهترین مقادیر تعدادی از هایپرپارامترها مانند توابع فعالسازی، اندازه دسته و نرخ یادگیری در میان سایر موارد تصمیم گرفت تا بتوان هر یک از این لایهها را تنظیم کرد.در این مطلب به تاثیر هایپرپارامترها در مدل یادگیری عمیق میپردازیم.
یک هایپرپارامتر فرآیند یادگیری را کنترل میکند و بنابراین مقادیر آنها مستقیماً بر سایر پارامترهای مدل مانند وزنها و بایاسها تأثیر میگذارد که در نتیجه بر عملکرد مدل ما تأثیر میگذارد. دقت هر مدل یادگیری ماشینی اغلب با تنظیم دقیق این هایپرپارامترها بهبود مییابد. بنابراین، درک این هایپرپارامترها برای محقق یادگیری ماشین ضروری است.
در این مطلب، برخی از هایپرپارامترها را بررسی میکنیم و به چگونگی تأثیر تغییر آنها بر عملکرد مدل نگاه میکنیم.
دیتاست
ما در اینجا گروه دیابت Indian هند را در نظر گرفتهایم. که حاوی اطلاعاتی در مورد ۷۶۸ زن از یک جمعیت در نزدیکی فینیکس، آریزونا، آمریکا است. متغیر وابسته در اینجا دیابت است. از ۷۶۸ تا از زنان به طبقه “مثبت” تعلق دارند در حالی که ۵۰۰ نفر دیگر متعلق به طبقه “منفی” هستند. ۸ ویژگی بارداریها، فشار خون، ضخامت پوست، انسولین، BMI (شاخص توده بدنی)، سن، و تابع دیابت سلسله مراتبی در این مجموعه داده وجود دارد.
ساختار شبکه
ساختار شبکه عصبی مورد استفاده ما شامل یک لایه ورودی با 8 نود است. به دنبال آن اولین لایه پنهان دارای 12 نود میباشد. و لایه پنهان دوم دارای 8 نود که همه آنها به یک نود در لایه خروجی متصل شدند. لایه خروجی برای تولید یک مقدار خروجی باینری با یک تابع فعالسازی سیگموید است زیرا ما با یک مسئله طبقهبندی باینری سروکار داریم.
آزمایش
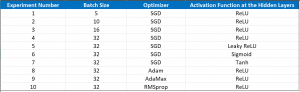
جدول زیر تنظیمات آزمایشهای مختلفی را نشان میدهد که ما به منظور مطالعه تأثیر هایپرپارامترها بر عملکرد مدل خود انجام دادیم.
تاثیر هایپرپارامترها در مدل یادگیری عمیق-اثر اندازه دسته
روش گرادیان نزولی برای آموزش شبکههای عصبی بکار میرود. در این تکنیک، برآورد خطای (تفاوت بین متغیرهای واقعی و پیشبینیشده)براساس یک زیرمجموعه از مجموعه داده آموزشی برای به روزرسانی وزنها در هر تکرار استفاده میشود. اندازه دستهای به عنوان تعداد نمونههایی تعریف میشود که از مجموعه داده آموزشی برای تخمین شیب خطا استفاده میشود. و یک هایپرپارامتر مهم است که بر پویایی الگوریتم یادگیری تاثیر میگذارد.در نزول گرادیان دسته ای کوچک، اندازه دسته روی بیش از یک و کمتر از تعداد کل نمونهها در مجموعه داده آموزشی تنظیم میشود.
در پایتون، اندازه دسته را می توان در حین آموزش مدل به صورت زیر مشخص کرد:
history = model.fit(X_train,y_train,validation_data=(X_test,y_test),epochs=NB_EPOCHS,batch_size=BATCH_SIZE,verbose=0,shuffle=False)
نمودارهای زیر دقت طبقهبندی مدلها را با مجموعه دادههای آموزش و تست ما با اندازههای دستهای مختلف هنگام استفاده از شیب نزول دستهای کوچک را نشان میدهند.
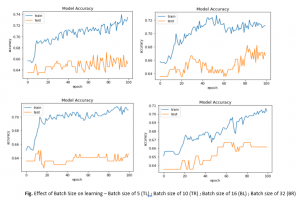
نمودارها نشان می دهند که:
- اندازههای دستهای کوچک 5 و 10 به طور کلی منجر به یادگیری سریع (دستیابی به دقت در مجموعه داده آموزشی بالای 0.72 در 100 دوره)، اما یک فرآیند یادگیری متغییر با واریانس بالاتر در دقت طبقهبندی میشود.
- اندازه دسته بزرگتر 16 و 32 روند یادگیری کندتر (دستیابی به دقت کمتر (72/0) در مجموعه داده های آموزشی در 100 دوره)، اما مراحل نهایی (بین 80 تا 100 دوره) منجر به مدل پایدارتری می شود که با واریانس کمتر در دقت طبقه بندی نشان داده شده است.
تاثیر هایپرپارامترها در مدل یادگیری عمیق-اثر توابع فعالسازی
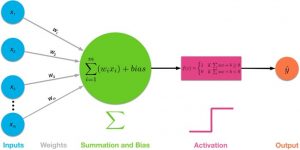
یک تابع فعالسازی در یک شبکه عصبی، مجموع وزنها از ورودی را به خروجی از یک گره در لایه ای از شبکه تبدیل میکند. اگر از یک تابع فعالسازی استفاده نشود، شبکههای عصبی فقط به یک مدل رگرسیون خطی تبدیل میشوند. زیرا این توابع، تبدیل غیرخطی ورودیها را امکانپذیر میکنند و آنها را قادر به یادگیری و انجام وظایف پیچیدهتر میکند. چندین توابع فعال سازی غیر خطی رایج مانند سیگموئید، tanh و ReLU وجود دارد.
در پایتون، تابع فعالسازی برای هر لایه پنهان را میتوان در هنگام ساخت مدل با استفاده از Keras به صورت زیر مشخص کرد:
from keras.models import Sequential model = Sequential() model.add(Dense(12, input_dim=8, activation='relu',kernel_initializer='uniform')) model.add(Dense(8, activation='relu',kernel_initializer='uniform')) model.add(Dense(1,activation='sigmoid' ,kernel_initializer='uniform'))
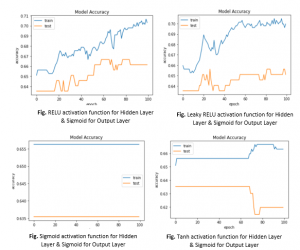
نمودارهای بالا دقت طبقهبندی مدلها را با مجموعه دادههای آموزش و تست با توابع فعالسازی مختلف در لایههای پنهان نشان میدهند.
- با توابع فعالسازی سیگموئید و tanh در لایه پنهان، از نمودارها مشاهده میکنیم که تقریباً هیچ یادگیری در دورهها صورت نمیگیرد. هر دو تابع فعالسازی سیگموئید و tanh از مشکل گرادیان ناپدید شدن رنج میبرند، که میتواند دلیلی برای مشاهده این رفتار هنگام استفاده از آنها در لایه پنهان باشد.
- از آنجایی که توابع فعالسازی مانند ReLU و leaky ReLU با مشکل گرادیان ناپدید شونده به چالش کشیده نمیشوند، ما مشاهده کردیم که یادگیری فعال در طول دورهها هنگام استفاده از آنها در لایه پنهان اتفاق میافتد.
اثر بهینه سازها
در حین آموزش یک مدل یادگیری عمیق، وزنها و سوگیری های مرتبط با هر گره از یک لایه در هر تکرار با هدف به حداقل رساندن تابع ضرر به روز میشوند. این تنظیم وزنها توسط الگوریتمهایی مانند نزول گرادیان تصادفی که با نام بهینه سازها نیز شناخته میشوند، فعال می شود.
سایر الگوریتمها مانند بهینهسازهای نرخ یادگیری تطبیقی، نرخ یادگیری را در طول آموزش در پاسخ به عملکرد مدل تنظیم میکنند. اگرچه هیچ روش واحدی بر روی همه مسائل بهترین کارایی را ندارد، روشهای نرخ یادگیری تطبیقی زیادی وجود دارند که ثابت کردهاند در بسیاری از انواع معماریهای شبکه عصبی و انواع مسائل قوی هستند. آنها AdaGrad، RMSProp، Adam، AdaMax هستند. و همگی نرخهای یادگیری را برای هر یک از وزنهای مدل حفظ و تطبیق میکنند.
در پایتون میتوانیم در هنگام ساخت مدل در Keras نوع بهینهساز را به صورت زیر مشخص کنیم:
from keras import optimizers sgd = optimizers.SGD(lr=0.001) rmsprop = optimizers.RMSprop(lr=0.001) adagrad = optimizers.Adagrad(lr=0.001) adam = optimizers.Adam(lr=0.001) adamax = optimizers.Adamax(lr=0.001) # Compile the model model.compile(loss='binary_crossentropy', optimizer=rmsprop, metrics=['accuracy'])
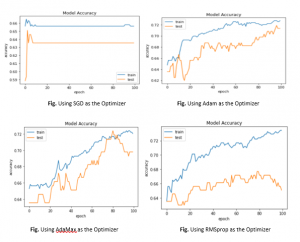
از نمودارهای داده شده در بالا، میتوانیم متوجه شویم که:
- گرادیان نزولی تصادفی (SGD)،با نرخ یادگیری 0.001 حتی با 100 دوره به دقت 0.7 در مجموعه داده آموزشی دست نمی یابد در حالی که RMSprop، AdaMax و Adam به طور موثر مسئله را یاد می گیرند و این دقت را در مجموعه داده آموزشی بسیار قبل از 100 دوره به دست می آورند.
- RMSprop، AdaMax و Adam بهینهسازهای نرخ یادگیری تطبیقی هستند که در آن نرخهای یادگیری برای هر یک از وزنهای مدل را میتوان بر اساس پاسخ به عملکرد مدل تطبیق داد.
نتیجه
در این مطلب تاثیر هایپرپارامترها در مدل یادگیری عمیق برای پیشبینی دیابت مورد بررسی قرار گرفت.
- اندازههای دستهای بزرگ باعث کند شدن فرآیند یادگیری میشود. اما یک مدل پایدارتر (همانطور که با واریانس کمتر در دقت طبقهبندی نشان میدهد) در مقایسه با اندازههای دستههای کوچکتر تولید میکند.
- استفاده از توابع فعالسازی مانند ReLU و leaky ReLU در لایه پنهان به حل مسئله گرادیان ناپدید شدن که هنگام استفاده از توابع فعالسازی sigmoid و tanh مشاهده شد، کمک کرد.
- استفاده از نرخهای یادگیری تطبیقی مانند RMSprop، AdaMax و adam به طور موثر تشخیص داده شدند. و در مقایسه با زمان استفاده از گرادیان تصادفی با نرخ یادگیری یکسان (۰.۰۰۱)به دقت بالاتری دست یافتند.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی
دیدگاهتان را بنویسید