
چرحه حیات یادگیری ماشین
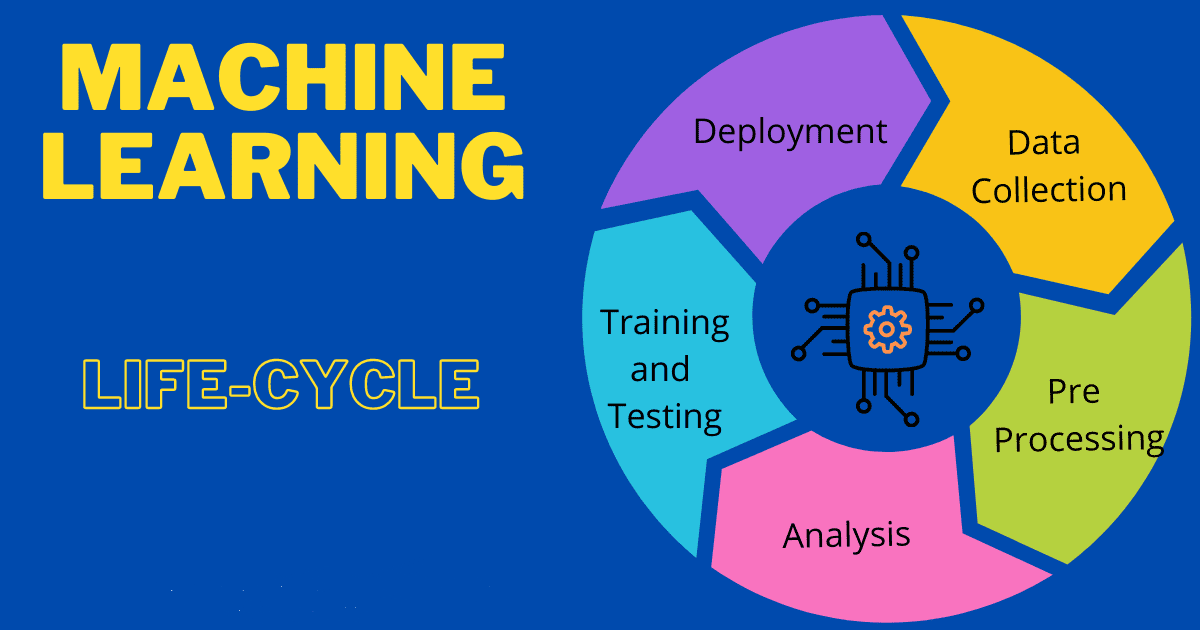
چرخه حیات یادگیری ماشین را میتوان مجموعهای از دستورالعملهایی دانست که هنگام ساخت پروژههای مبتنی بر یادگیری ماشین باید رعایت شوند. چرخه حیات یادگیری ماشین به ایجاد یک پروژه یادگیری ماشینی کارآمد کمک می کند. هدف اصلی چرخه حیات یافتن راه حلی برای مسئله یا پروژه است.
در این مقاله، در مورد اینکه منظور از چرخه زندگی یادگیری ماشین چیست و چه مراحلی را برای پیاده سازی چرخه زندگی یادگیری ماشین باید طی کنیم، خواهیم داشت.بنابراین بیایید ببینیم چه مراحل مختلفی در ساخت پروژه های یادگیری ماشینی در دنیای واقعی وجود دارد.
چرخه حیات یادگیری ماشین ؛قاب بندی مسئله
این مرحله اساسی و ضروری در توسعه یک پروژه یادگیری ماشینی است.
در این مرحله باید بفهمیم که پروژه ما چیست تا بتوانیم هر پارامتر مسئله را بشناسیم.
مواردی که باید در نظر بگیریم این است که مسئله واقعی ما چیست، اعضای تیمها، چگونه میتوانیم به آن راه حل نزدیک شویم، هزینه مربوطه، چگونه میتوانیم داده ها را به دست آوریم، الگوریتمی که میتوان از آن استفاده کرد، چارچوبی که باید مورد استفاده قرار گیرد، و مواردی این چنینی در این مرحله بررسی میشود.
پس از این که همه چیز به درستی مشخص شد، میتوانیم به مراحل بعدی برویم.
چرخه حیات یادگیری ماشین ؛جمع آوری اطلاعات
برای دانشجویان، دادهها به راحتی از وبسایتهای مختلف در دسترس هستند، اما در مورد شرکتها، این یک سناریوی متفاوت است.
روشهای مختلفی برای جمعآوری دادهها برای شرکتها وجود دارد:
APIs- با استفاده از کد پایتون به API ضربه بزنید و داده ها را با فرمت json واکشی کنید.
Web Scrapping:گاهی اوقات دادهها به صورت عمومی در دسترس نیستند،به عنوان مثال، در برخی از وب سایتها هستند، بنابراین ما باید آنها را از آنجا استخراج کنیم.
Data Warehouse-:داده ها در پایگاههای داده ذخیره میشوند. اما از این دادهها نمیتوان مستقیماً استفاده کرد زیرا داده در حال اجرا است. بنابراین دادههای پایگاه داده در یک انبار داده ذخیره می شود و سپس مورد استفاده قرار می گیرد.
Clusters:همچنین داده ها گاهی اوقات در ابزارهایی مانند spark به شکل خوشه هایی هستند که اساساً داده های بزرگ هستند، بنابراین داده ها از طریق این خوشه ها واکشی می شوند.
چرخه حیات یادگیری ماشین؛پیش پردازش داده ها
دادههایی که جمعآوری میشوند به احتمال زیاد دارای مقادیر گمشده، نقاط پرت، دادههای نویز و غیره هستند. این داده ها را نمی توان مستقیماً در مدل یادگیری ماشین استفاده کرد. بنابراین باید این داده ها را باید از قبل پردازش کنیم تا داده های جمع آوری شده مفید باشند.
پیش پردازش شامل حذف موارد تکراری، مقادیر از دست رفته، مقادیر پرت و مقیاس بندی می شود.اساساً، با پیش پردازش به داده هایی که میتواند برای مدل های یادگیری ماشین مفید باشد،دست پیدا میکنیم.
تجزیه و تحلیل داده های اکتشافی
با دیدن این تیتر مشخص است که ما دادهها را در این مرحله با مشاهده رابطه بین ورودی و خروجی تحلیل میکنیم.
این مرحله بینش دادهها را با تجسم دادهها با استفاده از نمودار، تشخیص outlier، و تجزیه و تحلیل تک متغیره به عنوان مثال، تجزیه و تحلیل مستقل هر ستون (میانگین، انحراف استاندارد)، تحلیل دو متغیره، تحلیل دو ستون و غیره ارائه میدهد.
ایده کلی پشت این مرحله به دست آوردن یک ایده عینی در مورد دادهها است.
مهندسی ویژگی و انتخاب
ویژگیها به معنای ستونهای ورودی هستند. کل ایده ایجاد ستونهای جدید در دادهها با استفاده از ستونهای موجود یا ایجاد تغییرات در ستونهای موجود برای تجزیه و تحلیل آسانتر است.
انتخاب ویژگی تنها انتخاب ستونهایی است که برای اجرای این مدل ضروری هستند.
گاهی اوقات ممکن است در دادهها ستونهای زیادی وجود داشته باشد، اما ما فقط به چند ستون ضروری نیاز داریم که برای مدل ضروری هستند.
بنابراین در چنین موردی، ما فقط آن چند ستون را انتخاب خواهیم کرد.
آموزش مدل
وقتی از داده ها مطمئن شدیم اکنون می خواهیم از این داده ها برای آموزش مدل خود استفاده کنیم. آموزش یک مدل مورد نیاز است تا بتواند الگوها، قوانین و ویژگی های مختلف را درک کند.
ما مدل را با استفاده از الگوریتمهای مختلف آموزش میدهیم و سپس الگوریتمها را با معیارهای مختلف مانند امتیاز دقت، میانگین مربعات خطا و غیره ارزیابی میکنیم.بهترین مدل انتخاب شده و پارامترها تنظیم می شوند تا عملکرد مدل بهبود یابد.
همچنین به عنوان Hyper Parameter Tuning نیز شناخته می شود.
تست مدل
هنگامی که مدل یادگیری ماشین ما بر روی یک مجموعه داده مشخص آموزش داده شد، سپس مدل را آزمایش می کنیم.در این مرحله، با ارائه یک مجموعه داده آزمایشی، صحت مدل خود را بررسی می کنیم.آزمایش مدل بر اساس نیاز پروژه یا مسئله، درصد دقت مدل را تعیین می کند.
استقرار مدل
در این مرحله، مدل را در سیستم دنیای واقعی مستقر می کنیم. اگر مدل آماده شده فوق با سرعت قابل قبولی نتیجه دقیقی را مطابق با نیاز ما ایجاد کند، مدل را در سیستم واقعی مستقر می کنیم.
اما قبل از استقرار پروژه، بررسی می کنیم که آیا با استفاده از داده های موجود عملکرد خود را بهبود می بخشد یا خیر.
برای استقرار میتوانیم از Heroku، AWS، پلتفرم ابری گوگل و غیره استفاده کنیم. اکنون مدل ما آنلاین است و درخواستهای کاربران را ارائه میکند.
برای فردی که روی یک پروژه شخصی یا پروژه کالج کار می کند، این مراحل کامل هستند.دو مرحله بعدی توسط شرکت ها استفاده می شود.
الف. برنامه/نرم افزار تست:
در این مرحله، شرکتها نسخههای آلفا/بتای مدل مستقر شده را برای گروه خاصی از کاربران یا مشتریان ارائه میکنند تا بررسی کنند که آیا مدل مطابق با نیاز کار میکند یا خیر.
بازخورد از این کاربران جمع آوری می شود و سپس روی آن کار می شود. اگر مدل به درستی کار می کند، برای همه ارائه می شود.
ب.بهینه سازی:
در این مرحله، شرکتها از سرورها برای تهیه نسخه پشتیبان از مدل، پشتیبانگیری از دادهها، بالانس داده(در صورت درخواست کاربران زیادی خدمات ارائه میکنند)، از سرورها استفاده میکنند. این مرحله به طور کلی خودکار است.
نتیجهگیری:
سیستمهای یادگیری ماشین روز به روز اهمیت بیشتری پیدا میکنند، زیرا حجم دادههای درگیر در برنامههای مختلف به سرعت در حال افزایش است. موفقیت یادگیری ماشینی را میتوان به سیستمهای حیاتی ایمنی، مدیریت دادهها و محاسبات با عملکرد بالا که پتانسیل زیادی برای حوزههای کاربردی دارد، گسترش داد.
برای هر فردی بسیار مهم است که تمام مراحل چرخه حیات یادگیری ماشین را دنبال کند. با انجام این مراحل کلیه الزامات لازم جمع آوری و با برنامه ریزی مناسب (با انجام EDA و مهندسی ویژگی) اجرا می شود. این مراحل تضمین می کند که مدل یادگیری ماشین به خوبی بهینه شده است و نتایج صحیح یا دلخواه را ارائه می دهد.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

تاثیر هایپرپارامترها در مدل یادگیری عمیق

ذخیره و بارگذاری مدل در پایتون
دیدگاهتان را بنویسید