
آموزش شبکه عصبی با مثال XOR
آموزش شبکه عصبی با مثال XOR
شبکه های عصبی مصنوعی مدل های آماری یادگیری هستند که از شبکه های عصبی بیولوژیکی (سیستم عصبی مرکزی ، مانند مغز) الهام گرفته شده و در یادگیری ماشین استفاده می شوند. این شبکه ها به عنوان سیستم های “نورون” به هم پیوسته نشان داده می شوند که پیام هایی را به یکدیگر ارسال می کنند. اتصالات درون شبکه را می توان به طور سیستماتیک بر اساس ورودی ها و خروجی ها تنظیم کرد و برای یادگیری تحت نظارت ایده آل است.
XOR
شبکه های عصبی می تواند ترسناک باشد ، به ویژه برای افرادی که تجربه کمی در یادگیری ماشین و علوم شناختی دارند! با این حال ، این آموزش نحوه عملکرد شبکه های عصبی را توضیح می دهد. در پایان ، شما خواهید آموخت که چگونه شبکه یادگیری انعطاف پذیر خود را شبیه به ذهن بسازید.تنها پیش نیازها داشتن درک اولیه از پایتون ، محاسبه دبیرستان و عملیات ساده ماتریسی است. به غیر از این ، شما نیازی به دانستن چیزی ندارید.
درک ذهن
شبکه عصبی مجموعه ای از “نورون ها” است که “سیناپس” آنها را به هم متصل می کند. این مجموعه به سه قسمت اصلی سازماندهی شده است: لایه ورودی ، لایه مخفی و لایه خروجی. توجه داشته باشید که می توانید n لایه پنهان داشته باشید ، و یادگیری عمیق که شا مل چندین لایه پنهان است.
لایه های پنهان زمانی ضروری هستند که شبکه عصبی باید چیزی واقعاً پیچیده ، متنی یا غیر واضح را تشخیص دهد ، مانند تشخیص تصویر. اصطلاح یادگیری عمیق از داشتن لایه های پنهان فراوان ناشی شده است. این لایه ها به عنوان “مخفی” شناخته می شوند ، زیرا به عنوان خروجی شبکه قابل مشاهده نیستند..دایره ها نشان دهنده نورون ها و خطوط نشان دهنده سیناپس ها هستند. Synapses ورودی را گرفته و آن را در یک “وزن” ضرب می کند (“قدرت” ورودی در تعیین خروجی). نورون ها خروجی های همه سیناپس ها را اضافه کرده و یک تابع فعال سازی را اعمال می کنند.آموزش یک شبکه عصبی اساساً به معنی کالیبره کردن همه “وزنه ها” با تکرار دو مرحله کلیدی ، انتشار به جلو و انتشار عقب است.از آنجا که شبکه های عصبی برای رگرسیون عالی هستند ، بهترین داده های ورودی اعداد هستند (برخلاف مقادیر گسسته ، مانند رنگها یا ژانرهای فیلم ، که داده های آنها برای مدلهای طبقه بندی آماری بهتر است). داده های خروجی یک عدد در محدوده 0 و 1 خواهند بود (این در نهایت به عملکرد فعال سازی بستگی دارد).در انتشار رو به جلو ، ما مجموعه ای از وزن ها را به داده های ورودی اعمال می کنیم و خروجی را محاسبه می کنیم. برای اولین انتشار رو به جلو ، مجموعه وزنها به طور تصادفی انتخاب می شوند.در انتشار عقب ، ما حاشیه خطای خروجی را اندازه گیری می کنیم و وزن ها را بر این اساس تنظیم می کنیم تا خطا کاهش یابد.شبکه های عصبی هر دو انتشار رو به جلو و عقب را تکرار می کنند تا زمانی که وزن ها برای دقیق پیش بینی خروجی کالیبره شوند.در مرحله بعد ، ما یک مثال ساده از آموزش شبکه عصبی را برای عملکرد به عنوان یک عملیات “اختصاصی یا” (“XOR”) برای نشان دادن هر مرحله از فرآیند آموزش ، مرور می کنیم.
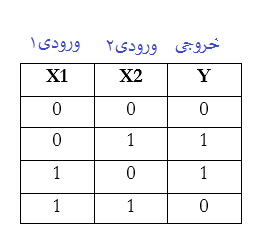
عملکرد XOR را می توان با نگاشت ورودی ها و خروجی های زیر نشان داد که از آنها به عنوان داده های آموزشی استفاده می کنیم. با توجه به هر ورودی قابل قبول توسط تابع XOR ، باید خروجی صحیحی را ارائه دهد.
بیایید از آخرین سطر جدول بالا ، (1 ، 1) => 0 برای نشان دادن انتشار جلو استفاده کنیم:
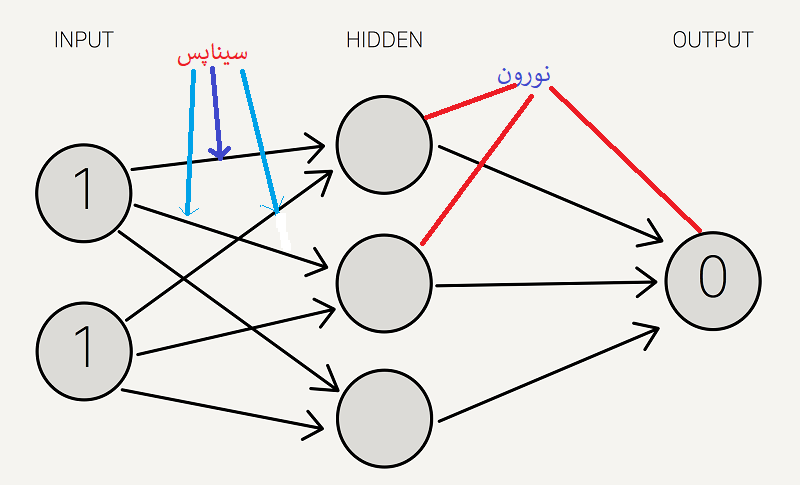
اکنون وزن را به همه سیناپس ها اختصاص می دهیم. توجه داشته باشید که این وزن ها به طور تصادفی (بر اساس توزیع گوسی) انتخاب می شوند ، زیرا اولین بار است که ما به جلو تبلیغ می کنیم. وزنهای اولیه بین 0 تا 1 خواهد بود
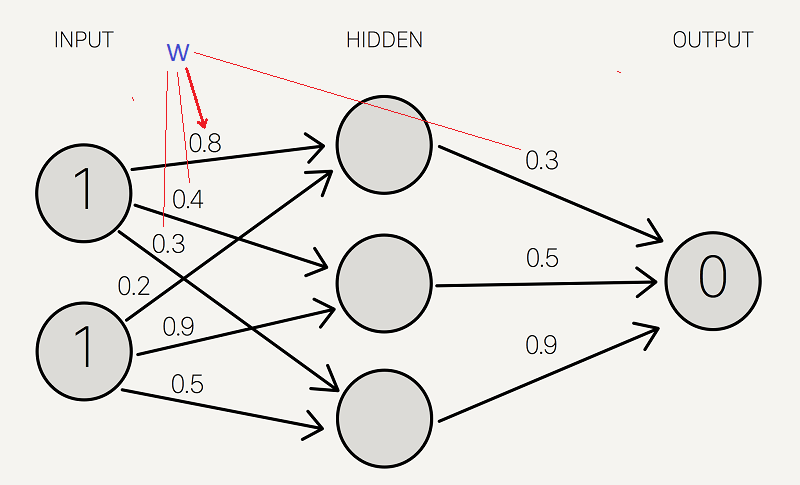
ما حاصلضرب ورودی ها را با مجموعه وزن مربوطه جمع می کنیم تا به اولین مقادیر لایه مخفی برسیم. می توانید وزنها را به عنوان معیارهای تأثیر گره های ورودی بر خروجی در نظر بگیرید.

این مقادیر را در دایره کوچکتر قرار می دهیم ، زیرا مقدار نهایی نیستند:
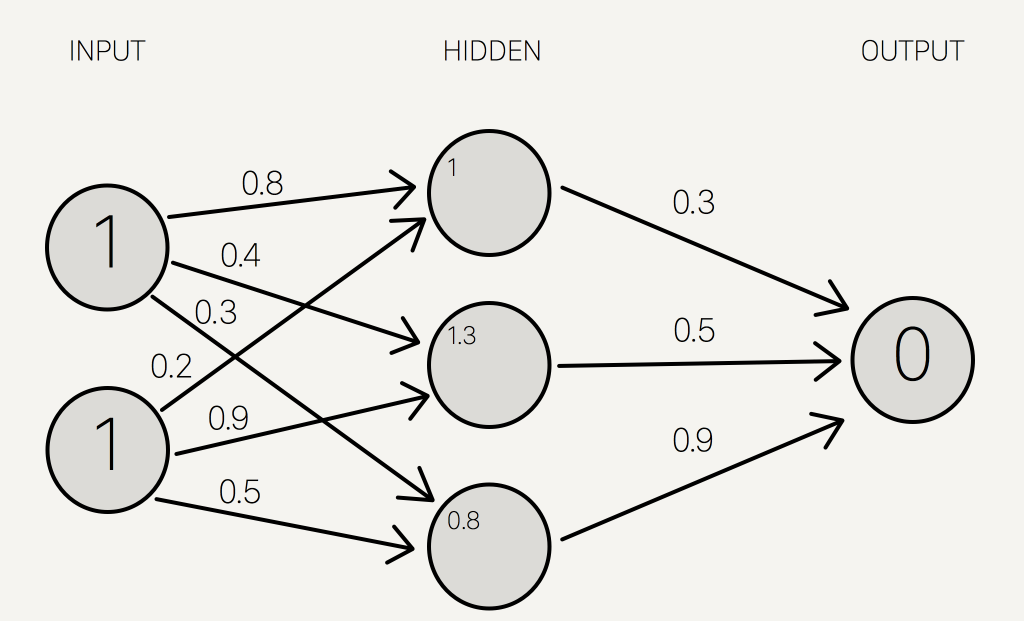
برای بدست آوردن مقدار نهایی ، تابع فعال سازی را روی مغادیر لایه مخفی اعمال می کنیم. هدف از تابع فعال سازی تبدیل سیگنال ورودی به یک سیگنال خروجی است و برای شبکه های عصبی الگوهای پیچیده غیر خطی که مدلهای ساده تر ممکن است از دست بدهند ضروری است.انواع مختلفی از توابع فعال سازی وجود دارد-خطی ، سیگموئید ، مماس هذلولی ، حتی مرحله ای. صادقانه بگویم ، من نمی دانم چرا یک عملکرد بهتر از عملکرد دیگر است.
برای مثال ما ، بیایید از تابع sigmoid برای فعال سازی استفاده کنیم. عملکرد سیگموئید به صورت گرافیکی به این شکل است:
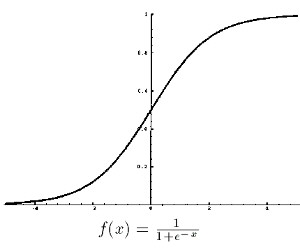
و با اعمال S (x) بر روی سه مقدار لایه مخفی ، بدست می آوریم:

ما آن را به عنوان نتایج لایه پنهان به شبکه عصبی خود اضافه می کنیم:
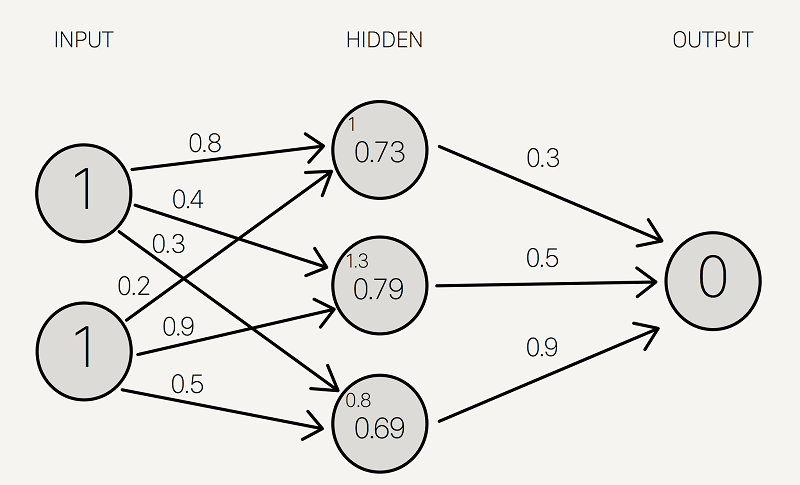
سپس ، حاصل نتایج لایه پنهان را با مجموعه دوم وزن ها (که اولین بار به طور تصادفی نیز تعیین شد) جمع می کنیم تا مجموع خروجی را تعیین کنیم.

از آنجا که ما از یک مجموعه تصادفی از وزنه های اولیه استفاده کردیم ، مقدار نورون خروجی خارج از علامت است. در این مورد 0.77+ (از آنجا که هدف 0 است). اگر در اینجا متوقف شویم ، این مجموعه وزنها یک شبکه عصبی عالی برای نمایش نادرست عملیات XOR خواهد بود.اجازه دهید با استفاده از انتشار به عقب برای تنظیم وزن برای بهبود شبکه ، آن را برطرف کنیم!برای بهبود مدل خود ، ابتدا باید میزان پیش بینی های خود را تا چه اندازه اشتباه کنیم.سپس ، وزن ها را بر این اساس تنظیم می کنیم تا حاشیه خطاها کاهش یابد.
مشابه انتشار جلو ، محاسبه انتشار عقب در هر “لایه” رخ می دهد. ما با تغییر وزن بین لایه مخفی و لایه خروجی شروع می کنیم.
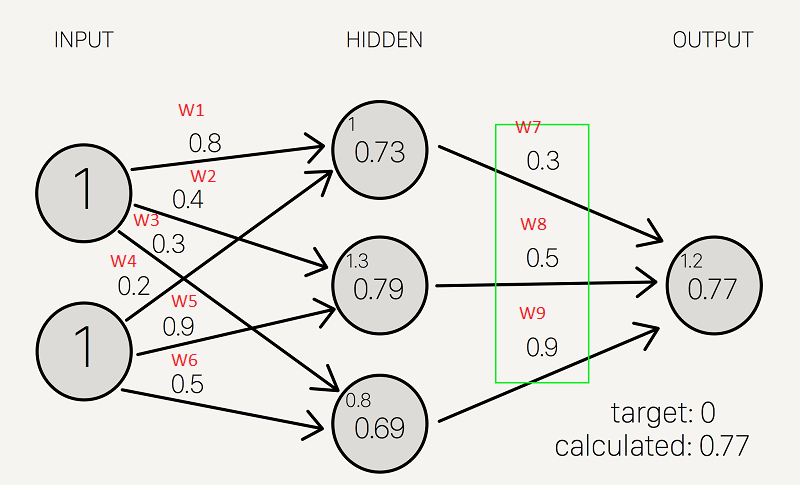
محاسبه تغییرات افزایشی در این وزنها در دو مرحله اتفاق می افتد: 1) ما حاشیه خطای نتیجه خروجی (آنچه بعد از اعمال تابع فعالسازی بدست می آوریم) را پیدا می کنیم تا تغییرات لازم در مجموع خروجی را کنار بگذاریم (ما این را خروجی دلتا می نامیم ) و 2) ما تغییر وزن را با ضرب مجموع خروجی دلتا در نتایج لایه مخفی استخراج می کنیم.
حاشیه مجموع خروجی خطا نتیجه خروجی هدف منهای نتیجه خروجی محاسبه شده است:

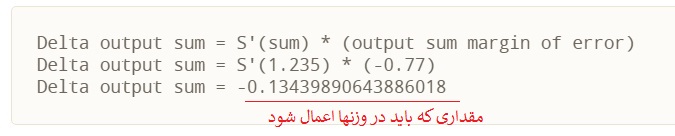
برای محاسبه تغییر لازم در مجموع خروجی ، یا مجموع خروجی دلتا ، مشتق تابع فعال سازی را گرفته و آن را بر مجموع خروجی اعمال می کنیم. در مثال ما ، تابع فعال سازی تابع سیگموئید است.
برای تازه سازی حافظه ، تابع فعال سازی ، sigmoid ، مجموع را گرفته و نتیجه را برمی گرداند
از نظر مفهومی ، این بدان معناست که تغییر در مجموع خروجی همان اول سیگموئید نتیجه خروجی است. با انجام ریاضی واقعی ، به دست می آوریم:
این رابطه نشان می دهد که تغییر بیشتر در مجموع خروجی ، تغییر بیشتری در وزن ها ایجاد می کند. نورونهای ورودی با بیشترین سهم (وزن بیشتر به نورون خروجی) باید تغییرات بیشتری در سیناپس اتصال ایجاد کنند.

برای تعیین تغییر وزن بین لایه های ورودی و لایه های پنهان ، ما محاسبات مشابه ، اما قابل توجهی متفاوت را انجام می دهیم. توجه داشته باشید که در محاسبات زیر ، از وزنهای اولیه به جای وزنهای اخیر تعدیل شده در قسمت اول انتشار عقب استفاده می کنیم.

هنگامی که مجموع مخفی دلتا را بدست می آوریم ، تغییر وزن بین لایه ورودی و لایه مخفی را با تقسیم آن با داده های ورودی محاسبه می کنیم (1 ، 1). داده های ورودی در اینجا معادل نتایج پنهان در فرایند انتشار قبلی است تا تغییر وزنهای مخفی به خروجی مشخص شود. در اینجا مشتق از آن رابطه ، مشابه رابطه قبلی است:

هنگامی که به وزنهای تنظیم شده رسیدیم ، دوباره با انتشار رو به جلو شروع می کنیم. هنگام آموزش شبکه عصبی ، معمول است که هر دو این مراحل را هزاران بار تکرار کنید (به طور پیش فرض ، 10 هزار بار تکرار می شود).
و با انتشار سریع به جلو ، می بینیم که خروجی نهایی در اینجا کمی به خروجی مورد انتظار نزدیک ترمی شود.
منتظر ادامه اموزش و کد نویسی مثال xor با پایتون باشید
موفق باشید .
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

1 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.