
بهترین GPU برای یادگیری عمیق(بخش پایانی)

بهترین GPU های آموزش یادگیری عمیق برای پروژه های بزرگ و مراکز داده
انتخاب بهترین GPUها برای یادگیری عمیق (بخش اول)
موارد زیر GPU هایی هستند که برای استفاده در پروژه های AI در مقیاس بزرگ توصیه می شوند.
-
NVIDIA Tesla A100
A100 یک GPU با هسته های Tensor است که از فناوری GPU چند نمونه ای (MIG) استفاده می کند. این برنامه برای یادگیری ماشین ،تجزیه و تحلیل داده ها و HPC طراحی شده است.مقیاس Tesla A100 تا هزاران واحد است و می تواند برای هر حجم کاری به هفت نمونهGPU تقسیم شود. هر تسلا A100 تا 624 ترافلاپس عملکرد ، 40 گیگابایت حافظه ، 1555 گیگابایت پهنای باند حافظه و 600 گیگابایت بر ثانیه رابط متصل را ارائه می دهد.
-
NVIDIA TeslaV100
NVIDIA Tesla V100 یک پردازنده گرافیکی Tensor Core است که برای یادگیری ماشین ، یادگیری عمیق و محاسبات با کارایی بالا (HPC) طراحی شده است.این دستگاه از فناوری NVIDIA Volta پشتیبانی می کند ، که از فناوری هسته ای تنسور پشتیبانی می کند ، که برای شتاب دادن به عملیات تنسور مشترکدر یادگیری عمیق اختصاصی شده است. هر تسلا V100 دارای 149 ترافلاپس عملکرد ، حداکثر 32 گیگابایت حافظه و یک باس حافظه 4096 بیتی است.
-
NVIDIA Tesla P100
تسلا P100 یک پردازنده گرافیکی مبتنی بر معماری NVIDIA Pascal است که برای یادگیری ماشین و HPC طراحی شده است. هر P100 حداکثر 21 ترافلاپسعملکرد ، 16 گیگابایت حافظه و یک گذرگاه حافظه 4096 بیتی را ارائه می دهد.
-
NVIDIA Tesla K80
تسلا K80 یک پردازنده گرافیکی مبتنی بر معماری NVIDIA Kepler است که برای تسریع محاسبات علمی و تجزیه و تحلیل داده ها طراحی شده است.این شامل 4،992 هسته NVIDIA CUDA و فناوری GPU Boost است. هر K80 حداکثر 8.73 ترافلاپس عملکرد ، 24 گیگابایت حافظه GDDR5 و 480 گیگابایتپهنای باند حافظه را ارائه می دهد.
Google TPU
واحدهای پردازش تنسور گوگل (TPU) کمی متفاوت هستند. TPU ها مدارهای مجتمع مبتنی بر تراشه یا مبتنی بر ابر (ASIC) برای یادگیری عمیق هستند.این واحدها به طور خاص برای استفاده با TensorFlow طراحی شده اند و فقط در Google Cloud Platform در دسترس هستند.هر TPU می تواند حداکثر 420 ترافلاپس عملکرد و 128 گیگابایت حافظه پهنای باند بالا (HBM) را ارائه دهد. همچنین نسخه های حفاظت شده موجود استکه می تواند بیش از 100 پتافلاپس عملکرد ، 32 ترابایت HBM و یک شبکه مش دوبعدی درهم پیچیده را ارائه دهد.
سیستم DGX برای یادگیری عمیق
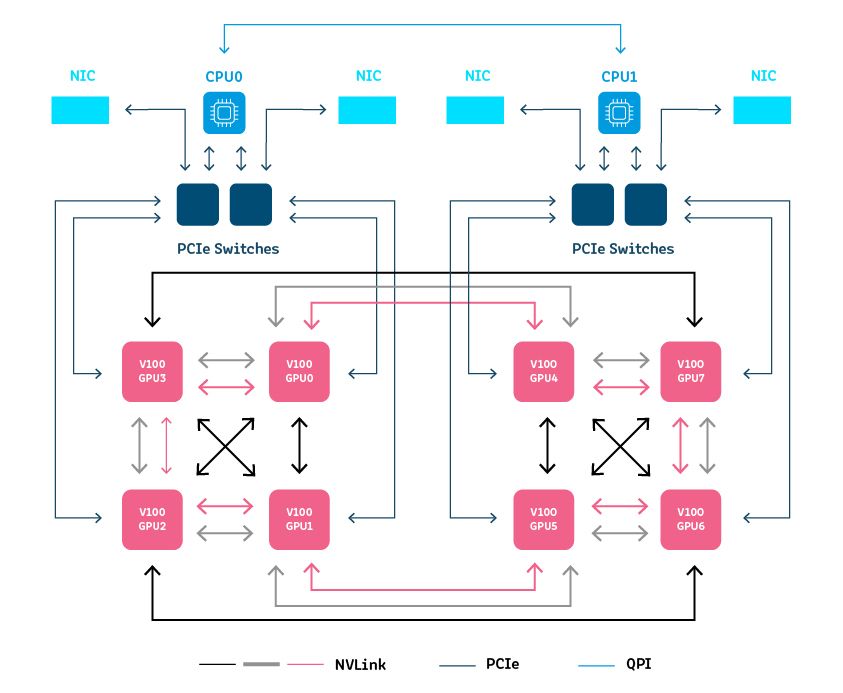
سیستم های NVIDIA DGX راه حل های کاملی هستند که برای یادگیری ماشین درجه یک طراحی شده اند. این سیستم ها بر اساس یک پشته نرم افزاریطراحی شده اند که برای هوش مصنوعی ، مقیاس پذیری چند گره ای و پشتیبانی سازمانی بهینه شده است.
می توانید پشته DGX را در چند مجموعه پیاده سازی کنید. این فناوری به صورت plug-n-play است و کاملاً با کتابخانه های یادگیری عمیق NVIDIA و راه حل هاینرم افزاری یکپارچه شده است. DGX برای ایستگاه های کاری ، سرورها ی حفاظت شده کلاس سرور در دسترس است. در زیر ، گزینه های سرور معرفی شده است.
-
DGX-1
DGX-1 یک سرور GPU است که بر اساس سیستم عامل میزبان لینوکس اوبونتو طراحی شده است. با راه حل های Red Hat ادغام می شود و شامل برنامه آموزش عمیق DIGITS ، SDK یادگیری عمیق NVIDIA ، جعبه ابزار CUDA ، و Docker Engine Utility برای GPU NVIDIA است.
هر DGX-1 شامل :
- دو پردازنده Intel Xeon برای هماهنگی چارچوب یادگیری عمیق ، راه اندازی و مدیریت ذخیره سازی
- حداکثر 8 پردازنده گرافیکی Tesla V100 Tensor Cores با 32 گیگابایت حافظه
- 300Gb/s NVLink به هم متصل می شود
- ارتباط 800 گیگابایت بر ثانیه با تاخیر کم
- SSD تنها 480 گیگابایت بوت OS و چهار SSD SAS 1.92 TB (مجموعاً 7.6 ترابایت) به صورت حجم راه راه RAID 0 پیکربندی شده است.
-
DGX-2
DGX-2 سطح بعدی DGX-1 است. برای موازی کاری و مقیاس پذیری بیشتر بر اساس شبکه NVSwitch طراحی شده است.
هر DGX-2 شامل :
- دو پتافلاپ اجرا
- 2X 960GB NVME SSD برای ذخیره سازی سیستم عامل و 30 ترابایت حافظه SSD
- 16 پردازنده گرافیکی Tesla V100 Tensor Core با 32 گیگابایت حافظه
- 12 NVS سوئیچ برای 2.4 ترابایت بر ثانیه پهنای باند دو بخش
- پهنای باند دو جهته 1.6 ترابایت بر ثانیه
- حافظه سیستم 1.5 ترابایت
- دو CPU Xeon Platinum برای هماهنگی چارچوب یادگیری عمیق ، بوت و ذخیره سازی
- دو کارت اترنت ورودی/خروجی بال
-
DGX A100
DGX A100 به عنوان یک سیستم جهانی برای حجم کار یادگیری ماشین از جمله تجزیه و تحلیل ، آموزش و نتیجه گیری طراحی شده است. برای CUDA-X کاملاً
بهینه شده است. DGX A100 را می توان با سایر واحدهای A100 روی هم قرار داد تا خوشه های عظیم هوش مصنوعی از جمله NVIDIA DGX SuperPOD ایجاد کند.
هر DGX A100 موارد زیر را ارائه می دهد:
- پنج پتافلاپس اجرا
- هشت پردازنده گرافیکی A100 Tensor Core با حافظه 40 گیگابایت
- شش سوئیچ NVS برای پهنای باند دو جهت 4.8 ترابایت
- نه رابط شبکه Mellanox Connectx-6 با پهنای باند دو جهت 450GB/s
- دو CPU 64 هسته ای AMD برای هماهنگی چارچوب یادگیری عمیق ، راه اندازی و ذخیره سازی
- حافظه سیستم 1 ترابایتی
- 2 درایو 1.92 ترابایت 2 NVME برای ذخیره سازی سیستم عامل و 15 ترابایت حافظه SSD
بهترین GPU برای یادگیری عمیق کدام است؟
متأسفانه پاسخ ساده ای وجود ندارد. بهترین GPU برای پروژه شما بستگی به بلوغ عملیات هوش مصنوعی شما ، مقیاسی که در آن کار می کنید و
الگوریتم ها و مدلهای خاصی که با آنها کار می کنید دارد. در بخشهای قبل ملاحظات بسیاری را ارائه دادیم که می تواند به شما در انتخاب GPU یا مجموعه ای
از GPU هایی که مناسب نیازهای شما هستند کمک کند.
مدیریت اجرا خودکار یادگیری عمیق با GPU : AI
اجرا: هوش مصنوعی مدیریت منابع و تنظیم حجم کار برای زیرساخت های یادگیری ماشین را به صورت خودکار انجام می دهد. با Run: AI ، می توانید
به طور خودکار هر تعداد آزمایش فشرده را که لازم است انجام دهید.
در اینجا برخی از قابلیت هایی که هنگام استفاده از Run به دست می آورید آورده شده است:
- دید پیشرفته – با جمع آوری منابع محاسبه GPU ، یک خط لوله کارآمد برای اشتراک منابع ایجاد کنید.
- دیگر نیازی به تنگناها نیست – برای جلوگیری از تنگناها و بهینه سازی صورتحساب ، می توانید سهمیه های تضمینی منابع GPU را تنظیم کنید.
- سطح بالاتری از کنترل – اجرا کنید: هوش مصنوعی به شما امکان می دهد تا تخصیص منابع را به صورت پویا تغییر دهید و اطمینان حاصل کنید
- که هر شغل در هر زمان منابع مورد نیاز خود را بدست می آورد.
- اجرا: هوش مصنوعی یادگیری عمیق را بر روی GPU تسریع می کند و به دانشمندان علم داده کمک می کند تا منابع محاسباتی گران قیمت را
- بهینه کرده و کیفیت مدل های خود را ارتقا دهند.
راهنمای اضافی ما را در زمینه موضوعات زیربنایی هوش مصنوعی کلیدی مشاهده کنید
ما راهنماهای مفصلی در مورد چندین موضوع زیرساختی هوش مصنوعی دیگر نوشته ایم که می توانند برای کشف دنیای GPU های یادگیری عمیق مفید باشند.
MLOps
در اقتصاد بسیار رقابتی امروز ، شرکت ها به طور کلی به دنبال هوش مصنوعی و به طور خاص ماشین و یادگیری عمیق هستند تا داده های بزرگ را به بینش هایکاربردی تبدیل کنند که می تواند به آنها کمک کند مخاطبین هدف خود را بهتر مورد بررسی قرار دهند ، فرایندهای تصمیم گیری خود را بهبود بخشند و زنجیره هایتأمین خود را ساده کنند. و فرآیندهای تولید ، به ذکر چند مورد از موارد استفاده فراوان موجود. با این حال ، برای اینکه جلوتر از منحنی بمانید و ارزش کامل ML را بدست آورید ،
شرکتها باید از MLOps به صورت استراتژیک استقبال کنند.
مقالات برتر را در راهنمای MLOps ما ببینید:
- برنامه های یادگیری ماشین: چیست و چرا به آن نیاز داریم
- اتوماسیون یادگیری ماشین: سرعت بخشیدن به مسیر علم داده
- گردش کار یادگیری ماشین: ساده سازی مسیر ML شما
کوبرنتس و هوش مصنوعی
این راهنما معماری Kubernetes را برای حجم کار AI و نحوه استفاده K8 در بسیاری از شرکت ها توضیح می دهد. ملاحظات خاصی برای پیاده سازی Kubernetes برای تنظیم حجم کار هوش مصنوعی وجود دارد. در نهایت ، این راهنما به کاستی های Kubernetes در مورد برنامه ریزی و تنظیم حجم کاریادگیری عمیق و چگونگی رفع این کمبودها می پردازد.
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

1 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.