
تجزیه و تحلیل احساسات(NLP) در توییت ها با LSTM

تجزیه و تحلیل احساسات(NLP) در توییت ها با LSTM
معرفی
در دنیای دیجیتال امروزی، پلتفرم های رسانه های اجتماعی مانند فیس بوک، واتساپ، توییتر به بخشی از برنامه روزانه ما تبدیل شده اند. بسیاری از تکنیک های NLP را می توان بر روی داده های متنی موجود از توییتر استفاده کرد. تحلیل احساسات به ایده پیش بینی احساس (شاد، غمگین، خنثی) از یک متن خاص اشاره دارد. در این وبلاگ، من با استفاده از تکنیک های NLP (پردازش زبان طبیعی) روی یک مجموعه داده بزرگ در دنیای واقعی، تجزیه و تحلیل احساسات را انجام خواهم داد.
من دادههایم را از مجموعه داده «Sentiment140» موجود در Kaggle میگیرم. حدود 1.6 میلیون توییت دارد که استخراج شده است. در اینجا می توانید به مجموعه داده دسترسی داشته باشید: مجموعه داده . حاشیه نویسی یا برچسب برای توییت ها به شرح زیر است:
-
0 = منفی
-
4 = مثبت
داده ها برای تجزیه و تحلیل احساسات
اجازه دهید با وارد کردن کتابخانه ها و خواندن داده ها از فایل های csv شروع کنیم.
import pandas as pd
df = pd.read_csv('../input/sentiment140/training.csv',header=None)
df.head(8)
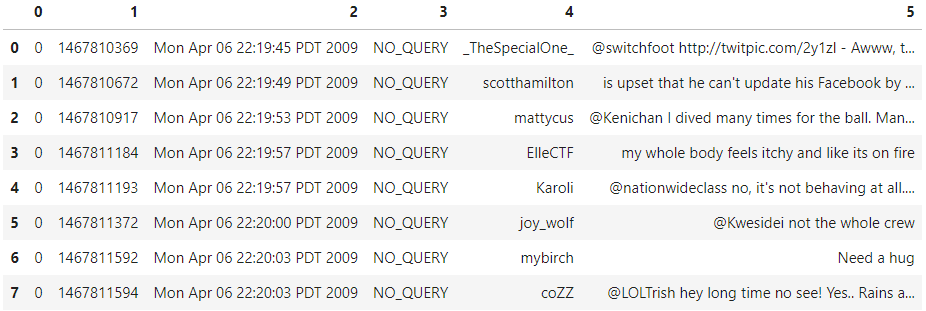
منبع: Kaggle notebook of Author
ستون اول ستون هدف است که نشان دهنده احساس توییت ها است (0/2/4). ستون بعدی شناسه هر توییت است و یک عدد منحصر به فرد است. پس از آن، تاریخ و زمان انتشار توییت را داریم. در مرحله بعد، نام کاربری نویسنده توییت را داریم. در پایان متن توییت را داریم. شما می توانید متوجه شوید که نام ستون ها بر این اساس تغییر کرده است.
df.columns = [‘احساس’، ‘شناسه’، ‘تاریخ’، ‘پرس و جو’، ‘user_name’، ‘tweet’]
در این وبلاگ تمرکز بر طبقه بندی احساس متن است. از این رو، میتوانیم ستونهای غیر ضروری را مطابق شکل زیر رها کنیم.
df = df.drop(['id', 'date', 'query', 'user_name'], axis=1) df.head()

اجازه دهید ارزش های احساسات را به مثبت و منفی ترسیم کنیم. 0 به منفی و چهار به مثبت نگاشت می شود. ما یک تابع کوچک «mapper()» برای انجام این نگاشت ایجاد می کنیم. این تابع را می توان با استفاده از تابع “apply()” در تمام ردیف های مجموعه داده استفاده کرد. به قطعه کد زیر نگاه کنید.
label_to_sentiment = {0:"Negative", 4:"Positive"}
def mapper(label):
return label_to_sentiment[label]
df.sentiment = df.sentiment.apply(lambda x: label_decoder(x))
هنگامی که ما روی مسائل طبقه بندی کار می کنیم، تعادل طبقاتی یک معیار مهم است. ضروری است اطمینان حاصل شود که کلاس ها خیلی پرت نیستند و عدم تعادل طبقاتی منجر به نتایج مغرضانه می شود. بیایید به کد نگاه کنیم.
distribution = df.sentiment.value_counts() plt.figure(figsize=(8,4)) plt.bar(distribution.index, distribution.values)
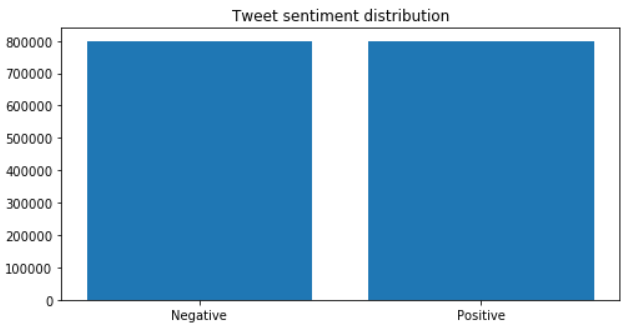
منبع: Kaggle notebook of Author
خوشبختانه برای ما، داده ها خیلی پرت نیست. بیایید به بخش اساسی هر کار NLP برویم: پیش پردازش متن.
متن برای پیش پردازش تحلیل احساسات
نویز زیادی در داده های متن خام حذف شده از توییت ها وجود دارد. دو بخش مهم تمیز کردن متن برای تجزیه و تحلیل احساسات عبارتند از: حذف کلمه توقف و ریشه کردن.
علائم نقطه گذاری وجود دارد، نمادهایی که چندان به مدل ما کمک نمی کنند. همچنین کلمات توقفی وجود دارد که باید حذف شوند. کلمات توقف به کلمات پیوند دهنده ای مانند “the”، “و” “بود” اشاره دارد که هیچ معنای خاصی ارائه نمی دهد، که به تحلیل ما کمک نمی کند. بنابراین، ما اینها را حذف کرده و داده ها را پاک می کنیم. NLTK یک بسته پایتون است که معمولاً برای وظایف NLP استفاده می شود. با استفاده از این بسته می توانیم به سرعت تمام کلمات توقف را به زبان انگلیسی دریافت کنیم. به قطعه زیر نگاهی بیندازید.
# Import nltk package and download the stopwords
import nltk
nltk.download('stopwords')
# We filter out the english language stopwrds
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)
ریشه پلماتیزاسیون به فرآیند استخراج ریشه کلمه اشاره دارد. به عنوان مثال، می توانید “بازی” را به صورت “بازی کردن”، “بازی شده”، “بازی” در زمان های مختلف بنویسید. اما معنای واقعی همان است. برای مدلسازی راحتتر باید اینها را به کلمه ریشه تبدیل کنیم. برای پیاده سازی می توانیم از Snowball stemmer از بسته NLTK استفاده کنیم. این یک نسخه اصلاح شده از الگوریتم استمر پورتر است.
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer('english')
برای حذف کاراکترهای غیر الفبایی می توانیم از عبارات regex استفاده کنیم.
import re text_cleaning_regex = "@S+|https?:S+|http?:S|[^A-Za-z0-9]+"
اکنون، اجازه دهید تابعی را تعریف کنیم که فیلتر regex را انجام میدهد، حذف کلمه را متوقف میکند و روی همه توییتها قرار میگیرد. توجه داشته باشید که در NLP، ما کلمات پردازش شده را به عنوان ‘tokens’ توصیف می کنیم. هر توییت به تابع نشان داده شده در زیر ارسال می شود.
def clean_tweets(text, stem=False):
# Text passed to the regex equatio
text = re.sub(text_cleaning_regex, ' ', str(text).lower()).strip()
# Empty list created to store final tokens
tokens = []
for token in text.split():
# check if the token is a stop word or not
if token not in stop_words:
if stem:
# Paased to the snowball stemmer
tokens.append(stemmer.stem(token))
else:
# A
tokens.append(token)
return " ".join(tokens)
در این تابع چه اتفاقی می افتد؟
متن به تمام حروف کوچک تبدیل می شود. فضاهای سفید حذف شده و به معادله منتقل می شوند. لینک ها کاراکترهای غیر الفبایی را حذف می کنند. می توان یک لیست خالی برای ذخیره نشانه های نهایی ایجاد کرد. جمله به کلمات تقسیم می شود و هر کلمه بررسی می شود که آیا به لیست کلمات توقف تعلق دارد یا خیر. پس از آن، stemming انجام می شود و کلمه در لیست ذخیره می شود. در پایان، توکن های موجود در لیست به هم متصل شده و برگردانده می شوند.
df.tweet = df.tweet.apply(lambda x: clean_tweets(x))
اجازه دهید در ادامه به قسمت مدلسازی برویم.
ابتدا، اجازه دهید مجموعه داده را به مجموعه های قطار و آزمایش تقسیم کنیم. ما می توانیم این کار را به راحتی با استفاده از تابع “train_test_split()” کتابخانه sklearn انجام دهیم. ما 20٪ از مجموعه داده را برای اهداف آزمایشی و بقیه را برای آموزش می گیریم.
# Import functions from sklearn library
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# Splitting the data into training and testing sets
train_data, test_data = train_test_split(df, test_size=0.2,random_state=16)
print("Train Data size:", len(train_data))
print("Test Data size", len(test_data))
#> Train Data size: 1280000
#> Test Data size 320000
رمزگذاری و رمزگذاری برچسب
توکن سازی به تقسیم جمله داده شده به لیستی از نشانه ها، نمایه شده یا بردار اشاره دارد. ما از TensorFlow و Keras برای مدل سازی استفاده خواهیم کرد. Keras یک ماژول پیش پردازش برای متن دارد که tf را به ما ارائه می دهد . کراس پیش پردازش . متن کلاس Tokenizer()`. می توانید آن را مطابق شکل زیر مقداردهی اولیه کنید. همچنین می توانید معیارهای تقسیم، حداکثر تعداد کلمات و غیره را مشخص کنید.
from keras.preprocessing.text import Tokenizer tokenizer = Tokenizer()
این کلاس متد «fit_on_texts()» دارد. اگر لیستی از متون را به این تابع ارسال کنیم، واژگان داخلی را متناسب با آن به روز خواهیم کرد.
tokenizer.fit_on_texts(train_data.tweet) word_index = tokenizer.word_index print(word_index)
این دیکشنری است که در آن هر کلمه با یک شاخص خاص ترسیم می شود که از 1 شروع می شود.
vocab_size = len(tokenizer.word_index) + 1
print("Vocabulary Size :", vocab_size)
#> Vocabulary Size : 290415
ما یک مدل توالی را برای این داده ها اعمال خواهیم کرد. برای این کار باید ورودی های هم اندازه را ارسال کنیم. برای رسیدن به این هدف، از تابع «pad_sequences()» استفاده می کنیم. با این کار دنباله هایی با اندازه ثابت به ما باز می گردند که می توانند به عنوان پارامتر ارسال شوند. به قطعه کد نگاهی بیندازید. طول دنباله را در این مورد 30 قرار داده ایم.
from keras.preprocessing.sequence import pad_sequences # The tokens are converted into sequences and then passed to the pad_sequences() function x_train = pad_sequences(tokenizer.texts_to_sequences(train_data.tweet),maxlen = 30) x_test = pad_sequences(tokenizer.texts_to_sequences(test_data.tweet),maxlen = 30)
در مرحله بعد، اجازه دهید به رمزگذاری برچسب برویم. ماژول پیش پردازش کتابخانه sklearn یک کلاس رمزگذار Label در اختیار ما قرار می دهد. راهاندازی کنید و آن را بر روی برچسبهای مجموعه داده آموزشی (ستون احساس) قرار دهید. پس از این، احساسات را از دادههای قطار استخراج میکنیم تا y_test، y_train را با کدگذاری و شکلدهی مجدد، مطابق شکل زیر، بسازیم.
labels = ['Negative', 'Positive'] from sklearn.preprocessing import LabelEncoder encoder = LabelEncoder() encoder.fit(train_data.sentiment.to_list()) y_train = encoder.transform(train_data.sentiment.to_list()) y_test = encoder.transform(test_data.sentiment.to_list()) y_train = y_train.reshape(-1,1) y_test = y_test.reshape(-1,1)
اکنون، ما با موفقیت آنها را به مجموعه های وابسته و مستقل تقسیم کرده ایم.

منبع: Kaggle notebook of Author ( Shapes of training and testing sets)
GloVe Word Embeddings
جاسازی کلمه برای نمایش کلمات با بردار استفاده می شود. هدف نهایی این است که گفتگوهایی با معانی مشابه نسبت به کلمات نامربوط در نمایش برداری به یکدیگر نزدیکتر باشند. فاصله بین کلمات را می توان با شباهت کسینوس اندازه گیری کرد. به عنوان مثال، کلمات “سفر” و “تعطیلات” با بردارهایی نزدیکتر به یکدیگر نشان داده می شوند.
gloVe یک مدل تعبیه کلمه از قبل آموزش دیده است و ما می توانیم آن را دانلود کنیم.
!wget http://nlp.stanford.edu/data/glove.6B.zip !unzip glove.6B.zip
اکنون میتوانیم یک فرهنگ لغت ایجاد کنیم که کلمات را با نمایشهای برداری GloVe نگاشت کند.
embeddings_index = {}
# opening the downloaded glove embeddings file
f = open('/kaggle/working/glove.6B.300d.txt')
for line in f:
# For each line file, the words are split and stored in a list
values = line.split()
word = value = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' %len(embeddings_index))
به یاد بیاورید که در بخش نشانه گذاری، ما یک فرهنگ لغت “word_index” دریافت کردیم، که در آن هر کلمه به یک فهرست در واژگان نگاشت می شود. اکنون، ما آن شاخصهای vocab را با نمایشهای دستکش ترسیم میکنیم.
# creating an matrix with zeroes of shape vocab x embedding dimension
embedding_matrix = np.zeros((vocab_size, 300))
# Iterate through word, index in the dictionary
for word, i in word_index.items():
# extract the corresponding vector for the vocab indice of same word
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# Storing it in a matrix
embedding_matrix[i] = embedding_vector
اکنون ماتریسی داریم که می تواند وزن ها را مقداردهی اولیه کند. ما از لایه جاسازی Keras استفاده خواهیم کرد.
embedding_layer = tf.keras.layers.Embedding(vocab_size,300,weights=[embedding_matrix],
input_length=30,trainable=False)
معماری مدل – LSTM
LSTM مخفف Long Short Term Memory است. این یک معماری اصلاح شده و پیشرفته از RNN ها (شبکه های عصبی بازگشتی) است. این عمدتاً در مسائل متوالی NLP مفید است، جایی که RNN به دلیل ناپدید شدن و انفجار گرادیان ها از کار می افتد. LSTMها قادرند وابستگی های مدل سازی دوربرد را با دقت بهتری نسبت به شبکه های معمولی انجام دهند.
اگر در یادگیری عمیق تازه کار هستید، ممکن است بخواهید این مقاله را برای درک عمیق تر از نحوه عملکرد LSTM بررسی کنید.
در این مشکل، معماری ما از چهار بخش اصلی تشکیل شده است. ما با لایه embedding که قبلا تعریف شده است شروع می کنیم و دنباله ها را وارد می کند و embedding های کلمه را می دهد. این تعبیهها سپس به لایه پیچیدگی منتقل میشوند، که آنها را به بردارهای ویژگی کوچک تبدیل میکند. بعد، لایه LSTM دو طرفه را داریم. بعد از لایههای LSTM، چند لایه متراکم (لایههای کاملاً متصل) برای اهداف طبقهبندی داریم. ما از یک تابع فعال سازی سیگموئید قبل از خروجی نهایی استفاده می کنیم.
# Import various layers needed for the architecture from keras from tensorflow.keras.layers import Conv1D, Bidirectional, LSTM, Dense, Input, Dropout from tensorflow.keras.layers import SpatialDropout1D from tensorflow.keras.callbacks import ModelCheckpoint # The Input layer sequence_input = Input(shape=(30,), dtype='int32') # Inputs passed to the embedding layer embedding_sequences = embedding_layer(sequence_input) # dropout and conv layer x = SpatialDropout1D(0.2)(embedding_sequences) x = Conv1D(64, 5, activation='relu')(x) # Passed on to the LSTM layer x = Bidirectional(LSTM(64, dropout=0.2, recurrent_dropout=0.2))(x) x = Dense(512, activation='relu')(x) x = Dropout(0.5)(x) x = Dense(512, activation='relu')(x) # Passed on to activation layer to get final output outputs = Dense(1, activation='sigmoid')(x) model = tf.keras.Model(sequence_input, outputs)
آموزش مدل و نتایج
معماری مدل کامل است. اجازه دهید به آموزش مدل روی مجموعه داده ادامه دهیم. ما از بهینه ساز Adam استفاده خواهیم کرد. از آنجایی که این یک وظیفه طبقه بندی باینری است (احساس مثبت یا منفی)، می توانیم از تابع خطا باینری متقاطع آنتروپی استفاده کنیم.
به طور کلی، تغییر نرخ یادگیری در طول آموزش برای مشکلات جزئی آموزش مجموعه داده مفید است. برای این کار میتوانیم از Learning rate Schedulers استفاده کنیم. ReduceLROnPlateau نرخ یادگیری را با ضریب 0.1 کاهش می دهد (می توان آن را مشخص کرد) اگر افت اعتبار سنجی کاهش نیابد. در اینجا، مانیتور مورد استفاده در ReduceOnPlateau از دست دادن اعتبارسنجی است. AUC همچنین می تواند به جای آن استفاده شود.
from tensorflow.keras.optimizers import Adam from tensorflow.keras.callbacks import ReduceLROnPlateau model.compile(optimizer=Adam(learning_rate=LR), loss='binary_crossentropy',metrics=['accuracy']) ReduceLROnPlateau = ReduceLROnPlateau(factor=0.1,min_lr = 0.01, monitor = 'val_loss',verbose = 1)
شما باید اندازه دسته و تعداد دوره هایی را که برای آنها تمرین خواهید کرد تصمیم بگیرید. به طور کلی آموزش برای 10-20 دوره کافی است.
training = model.fit(x_train, y_train, batch_size=1024, epochs=10,
validation_data=(x_test, y_test), callbacks=[ReduceLROnPlateau])
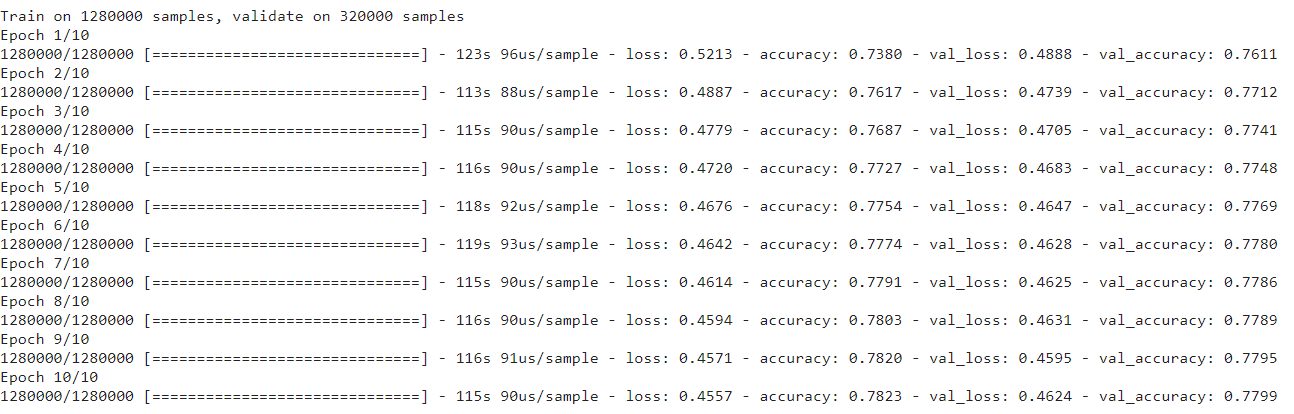
منبع: کنسول آموزشی نویسنده
ارزیابی مدل تحلیل احساسات
من دقت آموزش و اعتبار سنجی را در برابر دوره ها ترسیم کردم. همانطور که در تصویر زیر می بینیم، دقت اعتبار سنجی حدود 0.78 است.
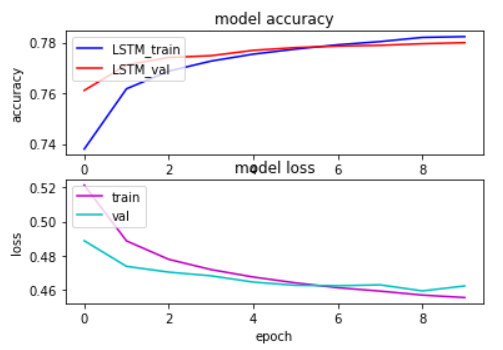
منبع: کنسول آموزشی نویسنده
اکنون که مدل آموزش داده شده است، می توانیم با آن پیش بینی کنیم. در نهایت، این یک مورد طبقه بندی باینری است. بنابراین، انتخاب یک مقدار آستانه برای طبقه بندی نمونه های داده کمک خواهد کرد. من 0.5 را انتخاب می کنم و اگر پیش بینی بالای 0.5 باشد، توییت به عنوان مثبت طبقه بندی می شود. در غیر این صورت به عنوان منفی طبقه بندی می شود.
def predict_tweet_sentiment(score):
return "Positive" if score>0.5 else "Negative"
scores = model.predict(x_test, verbose=1, batch_size=10000)
model_predictions = [predict_tweet_sentiment(score) for score in scores]
اکنون، اجازه دهید پیشبینیها را با مقادیر دادههای آزمایشی واقعی مقایسه کنیم.
from sklearn.metrics import classification_report print(classification_report(list(test_data.sentiment), model_predictions))
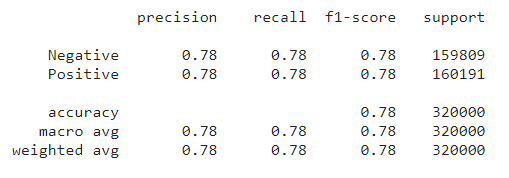
منبع: نوت بوک Kaggle نویسنده
از تصویر بالا می توان مشاهده کرد که دقت در حدود 0.78 است. این مقادیر به اندازه کافی خوب هستند.
امیدوارم مقاله من در مورد تجزیه و تحلیل احساسات را دوست داشته باشید!
مطالب زیر را حتما مطالعه کنید

درک منحنی AUC – ROC

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

ذخیره و بارگذاری مدل در پایتون
رایانش تکاملی (الگوریتم ژنتیک ) و موارد استفاده آن در یادگیری ماشینی

محل بررسی مدل های شبکه عصبی
دیدگاهتان را بنویسید