
تخمین وضعیت ژست انسان با استفاده از یادگیری ماشین در پایتون
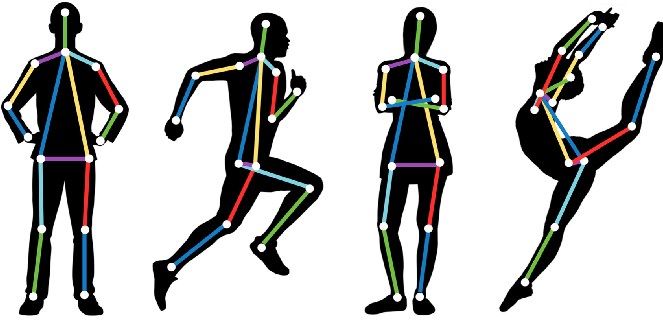
تشخیص پوز(ژست) یک رشته تحصیلی فعال در زمینه بینایی کامپیوتر است. شما به معنای واقعی کلمه می توانید صدها مقاله تحقیقاتی و چندین مدل را پیدا کنید که سعی در حل مشکل تشخیص ژست دارند. دلیل اینکه بسیاری از علاقه مندان به یادگیری ماشین جذب تخمین ژست می شوند، به دلیل کاربردهای گسترده و مفید بودن آن است. در این مقاله، ما قصد داریم یکی از این کاربردهای تشخیص و تخمین ژست را با استفاده از یادگیری ماشین و برخی از کتابخانه های بسیار مفید در پایتون پوشش دهیم.
تخمین پوز(ژست) چیست؟
تخمین وضعیت یک تکنیک بینایی کامپیوتری برای ردیابی حرکات یک فرد یا یک شی است. این معمولاً با یافتن مکان نقاط کلیدی برای اشیاء داده شده انجام می شود. بر اساس این نکات کلیدی می توانیم حرکات و وضعیت های مختلف را با هم مقایسه کنیم و بینش هایی را به دست آوریم. تخمین پوس به طور فعال در زمینه واقعیت افزوده، انیمیشن، بازی و روباتیک استفاده می شود
امروزه چندین مدل برای انجام تخمین پوز وجود دارد. برخی از روش های تخمین پوس در زیر آورده شده است:
- ژست باز
- ژست تور
- ژست بلیز
- ژست عمیق
- ژست متراکم
انتخاب یک مدل نسبت به مدل دیگر ممکن است کاملاً به برنامه بستگی داشته باشد. همچنین عواملی مانند زمان اجرا، اندازه مدل و سهولت اجرا می تواند دلایل مختلفی برای انتخاب یک مدل خاص باشد. پس بهتر است از ابتدا نیازهای خود را بدانید و بر اساس آن مدل را انتخاب کنید.برای این مقاله از ژست Blaze برای تشخیص ژست انسان و استخراج نکات کلیدی استفاده می کنیم. این مدل را می توان به راحتی از طریق یک کتابخانه بسیار مفید، که به عنوان لوله رسانه شناخته می شود، پیاده سازی کرد.Media Pipe – Media Pipe یک چارچوب چند پلت فرم منبع باز برای ساخت خطوط لوله یادگیری ماشین چند مدلی است. می توان از آن برای اجرای مدل های پیشرفته مانند تشخیص چهره انسان، ردیابی چند دستی، تقسیم بندی مو، تشخیص و ردیابی اشیا و غیره استفاده کرد.آشکارساز موقعیت شعله – در جایی که بیشتر تشخیص ژست ها بر توپولوژی COCO متشکل از 17 نقطه کلیدی متکی است، آشکارساز وضعیت شعله 33 نقطه کلیدی انسان از جمله نیم تنه، بازوها، پاها و صورت را پیش بینی می کند. گنجاندن نکات کلیدی بیشتری برای کاربردهای موفق مدلهای تخمین ژست مخصوص دامنه، مانند دستها، صورت و پاها ضروری است. هر نقطه کلیدی با سه درجه آزادی همراه با امتیاز دید پیش بینی می شود. حالت blaze یک مدل زیر میلی ثانیه است و می تواند برای کاربردهای بلادرنگ با دقتی بهتر از بسیاری از مدل های موجود استفاده شود. این مدل در دو نسخه Blaze pose lite و Blaze pose به طور کامل برای ایجاد تعادل بین سرعت و دقت موجود است.ژست Blaze چندین برنامه کاربردی از جمله تناسب اندام و ردیاب یوگا را ارائه می دهد. این برنامه ها را می توان با استفاده از یک طبقه بندی اضافی مانند آنچه که در این مقاله می سازیم پیاده سازی کرد.
تخمین ژست دو بعدی در مقابل سه بعدی
تخمین ژست را می توان به صورت دو بعدی یا سه بعدی انجام داد. تخمین حالت دوبعدی نقاط کلیدی تصویر را از طریق مقادیر پیکسل پیش بینی می کند. در حالی که تخمین پوز سه بعدی به پیش بینی آرایش فضایی سه بعدی نقاط کلیدی به عنوان خروجی آن اشاره دارد.
آماده سازی مجموعه داده برای تخمین ژست
در بخش قبل یاد گرفتیم که از نکات کلیدی ژست انسان می توان برای مقایسه پوسچرهای مختلف استفاده کرد. در این بخش قصد داریم با استفاده از خود کتابخانه لوله رسانه، مجموعه داده را آماده کنیم. ما قصد داریم از دو حالت یوگا عکس بگیریم، نکات کلیدی را از آنها استخراج کرده و در یک فایل CSV ذخیره کنیم.از طریق این لینک می توانید مجموعه داده را از Kaggle دانلود کنید. مجموعه داده از 5 حالت یوگا تشکیل شده است، با این حال، در این مقاله من فقط دو ژست می گیرم. در صورت تمایل می توانید از همه آنها استفاده کنید، روش به همان صورت باقی می ماند.
import mediapipe as mp import cv2 import time import numpy as np import pandas as pd import os mpPose = mp.solutions.pose pose = mpPose.Pose() mpDraw = mp.solutions.drawing_utils # For drawing keypoints points = mpPose.PoseLandmark # Landmarks path = "DATASET/TRAIN/plank" # enter dataset path data = [] for p in points: x = str(p)[13:] data.append(x + "_x") data.append(x + "_y") data.append(x + "_z") data.append(x + "_vis") data = pd.DataFrame(columns = data) # Empty dataset
در قطعه کد بالا، ابتدا کتابخانه های لازم را وارد کرده ایم که به ایجاد مجموعه داده کمک می کند. سپس در چهار خط بعدی، ماژول های مورد نیاز برای استخراج نقاط کلیدی و کاربردهای ترسیم آنها را وارد می کنیم. در مرحله بعد یک قاب داده خالی پاندا ایجاد می کنیم و ستون ها را وارد می کنیم. در اینجا ستون ها شامل سی و سه نقطه کلیدی است که توسط آشکارساز موقعیت شعله تشخیص داده می شود. هر نقطه کلیدی شامل چهار ویژگی است که مختصات x و y نقطه کلیدی هستند (از 0 تا 1 نرمال شده)، مختصات z که عمق نقطه عطف را با باسن به عنوان مبدأ و مقیاس مشابه با x و در نهایت امتیاز دید را نشان می دهد. امتیاز دید نشان دهنده این احتمال است که نقطه عطف یا در تصویر قابل مشاهده است یا خیر.
count = 0
for img in os.listdir(path):
temp = []
img = cv2.imread(path + "/" + img)
imageWidth, imageHeight = img.shape[:2]
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blackie = np.zeros(img.shape) # Blank image
results = pose.process(imgRGB)
if results.pose_landmarks:
# mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS) #draw landmarks on image
mpDraw.draw_landmarks(blackie, results.pose_landmarks, mpPose.POSE_CONNECTIONS) # draw landmarks on blackie
landmarks = results.pose_landmarks.landmark
for i,j in zip(points,landmarks):
temp = temp + [j.x, j.y, j.z, j.visibility]
data.loc[count] = temp
count +=1
cv2.imshow("Image", img)
cv2.imshow("blackie",blackie)
cv2.waitKey(100)
data.to_csv("dataset3.csv") # save the data as a csv file
در کد بالا، تصاویر پوز را به صورت جداگانه تکرار می کنیم، نقاط کلیدی را با استفاده از مدل pose blaze استخراج می کنیم و آنها را در آرایه موقت “temp” ذخیره می کنیم. پس از تکمیل تکرار، این آرایه موقت را به عنوان یک رکورد جدید در مجموعه داده خود اضافه می کنیم. شما همچنین می توانید این نشانه ها را با استفاده از ابزارهای طراحی موجود در خود لوله رسانه مشاهده کنید.
در کد بالا، من این نشانهها را روی تصویر و همچنین روی یک تصویر خالی «blackie» ترسیم کردهام تا فقط بر روی نتایج مدل حالت blaze تمرکز کنم. تصویر خالی “blackie” همان شکل تصویر داده شده را دارد. نکته ای که باید به آن توجه کرد این است که مدل blaze pose به جای BGR (خوانده شده توسط OpenCV) تصاویر RGB می گیرد.
پس از دریافت نکات کلیدی همه تصاویر، باید یک مقدار هدف اضافه کنیم که به عنوان یک برچسب برای مدل یادگیری ماشین ما عمل می کند. می توانید مقدار هدف را برای حالت اول 0 و دیگری را 1 قرار دهید. پس از آن، ما فقط می توانیم این داده ها را در یک فایل CSV ذخیره کنیم که در مراحل بعدی برای ایجاد یک مدل یادگیری ماشین استفاده خواهیم کرد.

از تصویر بالا می توانید مشاهده کنید که مجموعه داده چگونه به نظر می رسد.
ایجاد مدل تخمین ژست
اکنون مجموعه داده خود را ایجاد کرده ایم، فقط باید یک الگوریتم یادگیری ماشینی را برای طبقه بندی پوزها انتخاب کنیم. در این مرحله، یک تصویر میگیریم، مدل blaze pose (که قبلاً برای ایجاد مجموعه داده استفاده میکردیم) را اجرا میکنیم تا نکات کلیدی شخص حاضر در آن تصویر را بدست آوریم و مدل خود را روی آن مورد آزمایشی اجرا میکنیم. انتظار می رود این مدل نتایج صحیح را با امتیاز اطمینان بالا ارائه دهد. در این مقاله، من قصد دارم از SVC (Support Vector Classifier) از کتابخانه sklearn برای انجام وظیفه طبقه بندی استفاده کنم.
from sklearn.svm import SVC
data = pd.read_csv("dataset3.csv")
X,Y = data.iloc[:,:132],data['target']
model = SVC(kernel = 'poly')
model.fit(X,Y)
mpPose = mp.solutions.pose
pose = mpPose.Pose()
mpDraw = mp.solutions.drawing_utils
path = "enter image path"
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = pose.process(imgRGB)
if results.pose_landmarks:
landmarks = results.pose_landmarks.landmark
for j in landmarks:
temp = temp + [j.x, j.y, j.z, j.visibility]
y = model.predict([temp])
if y == 0:
asan = "plank"
else:
asan = "goddess"
print(asan)
cv2.putText(img, asan, (50,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,0),3)
cv2.imshow("image",img)
در خطوط کد بالا، ابتدا SVC (Support Vector Classifier) را از کتابخانه sklearn وارد کرده ایم. ما مجموعه دادهای را که قبلاً روی SVC ساختهایم با متغیر هدف به عنوان برچسب Y آموزش دادهایم.
سپس تصویر ورودی را می خوانیم و نقاط کلیدی را استخراج می کنیم، همانطور که در هنگام ایجاد مجموعه داده انجام دادیم. در نهایت، متغیر موقت را وارد کرده و از مدل برای پیشبینی استفاده میکنیم. اکنون می توان با استفاده از شرایط ساده if-else پوز را تشخیص داد.
نتایج مدل :

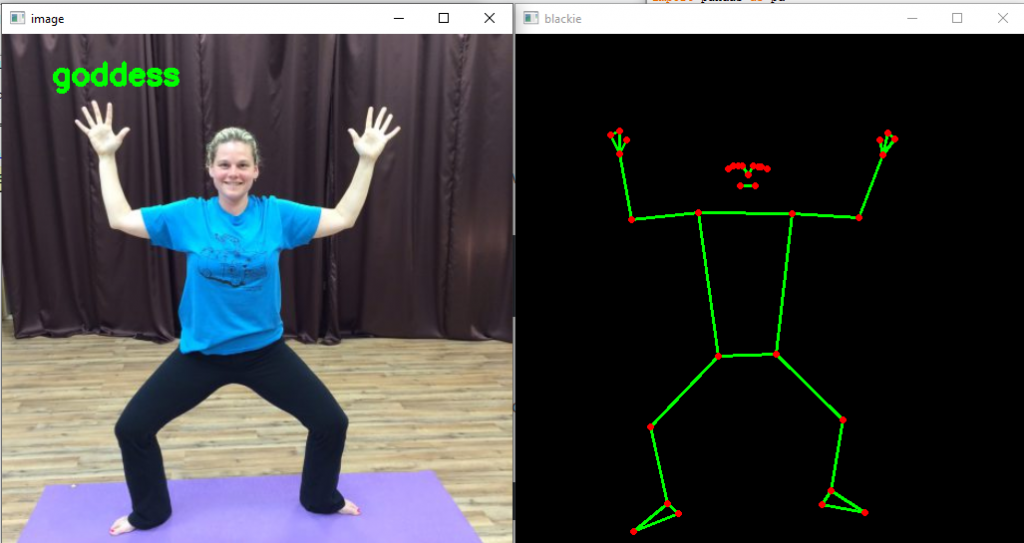
از تصاویر بالا مشاهده می کنید که مدل به درستی ژست را طبقه بندی کرده است. همچنین می توانید ژست شناسایی شده توسط مدل ژست بلیز را در سمت راست مشاهده کنید.
در تصویر اول، اگر از نزدیک مشاهده کنید، برخی از نکات کلیدی قابل مشاهده نیستند، همچنان ژست به درستی طبقه بندی شده است. این می تواند به دلیل قابل مشاهده بودن ویژگی نقاط کلیدی ارائه شده توسط مدل حالت blaze امکان پذیر باشد.
نتیجه :
تشخیص ژست یک حوزه تحقیقاتی فعال در زمینه یادگیری ماشینی است و چندین برنامه کاربردی در زندگی واقعی ارائه می دهد. در این مقاله سعی کردیم بر روی یکی از این برنامه ها کار کنیم و با تشخیص ژست دست ها را وارد کار کردیم. ما در مورد تشخیص ژست و چندین مدل که می توان برای تشخیص ژست استفاده کرد آشنا شدیم. ما مدل ژست بلیز را برای هدف خود انتخاب کردیم و با مزایا و معایب آن نسبت به مدل های دیگر آشنا شدیم. در پایان، ما یک طبقهبندی برای طبقهبندی ژستهای یوگا با استفاده از طبقهبندی بردار پشتیبانی از کتابخانه sklearn ساختیم. ما همچنین مجموعه داده های خود را برای این منظور ساختیم که می تواند به راحتی با استفاده از تصاویر بیشتر گسترش یابد.
میتوانید به جای SVM الگوریتمهای یادگیری ماشین دیگری را نیز امتحان کنید و نتایج را بر این اساس مقایسه کنید.
موفق باشید
مطالب زیر را حتما مطالعه کنید

منحنی AUC-ROC در یادگیری ماشین

درک منحنی AUC – ROC

چرحه حیات یادگیری ماشین

تشخیص جنسیت و سن افراد با کتابخانه OpenCV

تاثیر هایپرپارامترها در مدل یادگیری عمیق

دیدگاهتان را بنویسید